基本文本处理技能和语言模型
1. 基本文本处理技能
1.1 分词的概念(分词的正向最大、逆向最大、双向最大匹配法)参考链接1
下面详细说说正向最大匹配法、逆向最大匹配法和双向最大匹配法具体是如何进行的:
先说说什么是最大匹配法:最大匹配是指以词典为依据,取词典中最长单词为第一个次取字数量的扫描串,在词典中进行扫描(为提升扫描效率,还可以跟据字数多少设计多个字典,然后根据字数分别从不同字典中进行扫描)。例如:词典中最长词为“中华人民共和国”共7个汉字,则最大匹配起始字数为7个汉字。然后逐字递减,在对应的词典中进行查找。
下面以“我们在野生动物园玩”详细说明一下这几种匹配方法:
1、正向最大匹配法:
正向即从前往后取词,从7->1,每次减一个字,直到词典命中或剩下1个单字。
第1次:“我们在野生动物”,扫描7字词典,无
第2次:“我们在野生动”,扫描6字词典,无
。。。。
第6次:“我们”,扫描2字词典,有
扫描中止,输出第1个词为“我们”,去除第1个词后开始第2轮扫描,即:
第2轮扫描:
第1次:“在野生动物园玩”,扫描7字词典,无
第2次:“在野生动物园”,扫描6字词典,无
。。。。
第6次:“在野”,扫描2字词典,有
扫描中止,输出第2个词为“在野”,去除第2个词后开始第3轮扫描,即:
第3轮扫描:
第1次:“生动物园玩”,扫描5字词典,无
第2次:“生动物园”,扫描4字词典,无
第3次:“生动物”,扫描3字词典,无
第4次:“生动”,扫描2字词典,有
扫描中止,输出第3个词为“生动”,第4轮扫描,即:
第4轮扫描:
第1次:“物园玩”,扫描3字词典,无
第2次:“物园”,扫描2字词典,无
第3次:“物”,扫描1字词典,无
扫描中止,输出第4个词为“物”,非字典词数加1,开始第5轮扫描,即:
第5轮扫描:
第1次:“园玩”,扫描2字词典,无
第2次:“园”,扫描1字词典,有
扫描中止,输出第5个词为“园”,单字字典词数加1,开始第6轮扫描,即:
第6轮扫描:
第1次:“玩”,扫描1字字典词,有
扫描中止,输出第6个词为“玩”,单字字典词数加1,整体扫描结束。
正向最大匹配法,最终切分结果为:“我们/在野/生动/物/园/玩”,其中,单字字典词为2,非词典词为1。
2、逆向最大匹配法:
逆向即从后往前取词,其他逻辑和正向相同。即:
第1轮扫描:“在野生动物园玩”
第1次:“在野生动物园玩”,扫描7字词典,无
第2次:“野生动物园玩”,扫描6字词典,无
。。。。
第7次:“玩”,扫描1字词典,有
扫描中止,输出“玩”,单字字典词加1,开始第2轮扫描
第2轮扫描:“们在野生动物园”
第1次:“们在野生动物园”,扫描7字词典,无
第2次:“在野生动物园”,扫描6字词典,无
第3次:“野生动物园”,扫描5字词典,有
扫描中止,输出“野生动物园”,开始第3轮扫描
第3轮扫描:“我们在”
第1次:“我们在”,扫描3字词典,无
第2次:“们在”,扫描2字词典,无
第3次:“在”,扫描1字词典,有
扫描中止,输出“在”,单字字典词加1,开始第4轮扫描
第4轮扫描:“我们”
第1次:“我们”,扫描2字词典,有
扫描中止,输出“我们”,整体扫描结束。
逆向最大匹配法,最终切分结果为:“我们/在/野生动物园/玩”,其中,单字字典词为2,非词典词为0。
3、双向最大匹配法:
正向最大匹配法和逆向最大匹配法,都有其局限性,我举得例子是正向最大匹配法局限性的例子,逆向也同样存在(如:长春药店,逆向切分为“长/春药店”),因此有人又提出了双向最大匹配法,双向最大匹配法。即,两种算法都切一遍,然后根据大颗粒度词越多越好,非词典词和单字词越少越好的原则,选取其中一种分词结果输出。
如:“我们在野生动物园玩”
正向最大匹配法,最终切分结果为:“我们/在野/生动/物/园/玩”,其中,两字词3个,单字字典词为2,非词典词为1。
逆向最大匹配法,最终切分结果为:“我们/在/野生动物园/玩”,其中,五字词1个,两字词1个,单字字典词为2,非词典词为0。
非字典词:正向(1)>逆向(0)(越少越好)
单字字典词:正向(2)=逆向(2)(越少越好)
总词数:正向(6)>逆向(4)(越少越好)
因此最终输出为逆向结果。
1.2 词、字符频率统计
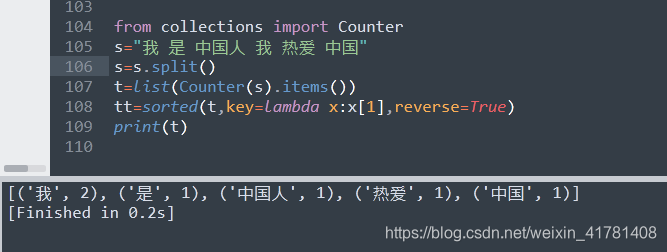
from collections import Counter
s="我 是 中国人 我 热爱 中国"
s=s.split()
t=list(Counter(s).items())
tt=sorted(t,key=lambda x:x[1],reverse=True)
print(t)
2. 语言模型
2.1 语言模型中unigram、bigram、trigram的概念
1.unigram 一元分词,把句子分成一个一个的汉字
2.bigram 二元分词,把句子从头到尾每两个字组成一个词语
3.trigram 三元分词,把句子从头到尾每三个字组成一个词语.
n-gram模型的概念
n-gram模型也称为n-1阶马尔科夫模型,它有一个有限历史假设:当前词的出现概率仅仅与前面n-1个词相关。因此(1)式可以近似为:
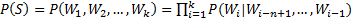
当n取1、2、3时,n-gram模型分别称为unigram、bigram和trigram语言模型。n-gram模型的参数就是条件概率
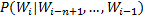
假设词表的大小为100,000,那么n-gram模型的参数数量为
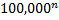
n越大,模型越准确,也越复杂,需要的计算量越大。最常用的是bigram,其次是unigram和trigram,n取≥4的情况较少。
2.2 unigram、bigram频率统计
参考链接: DayNightStudy.
import collections
text = u"""5日下午,中共中央总书记、国家主席、中央军委主席习近平参加他所在的十三届全国人大二次会议内蒙古代表团审议"""
print("-------------counter unigram--------------")
unigram_counter = collections.Counter([text[i] for i in range(0,len(text))])
for k,v in unigram_counter.items():
print(k,v)
print("-------------counter bigram--------------")
bigram_counter = collections.Counter([(text[i],text[i+1]) for i in range(0,len(text)-1)])
for k,v in bigram_counter.items():
print(k,v)
print("-------------counter bigram--------------")
bigram_counter = collections.Counter([(text[i],text[i+1],text[i+2]) for i in range(0,len(text)-2)])
for k,v in bigram_counter.items():
print(k,v)
-------------counter unigram--------------
5 1
日 1
下 1
午 1
, 1
中 3
共 1
央 2
总 1
书 1
记 1
、 2
国 2
家 1
主 2
席 2
军 1
委 1
习 1
近 1
平 1
参 1
加 1
他 1
所 1
在 1
的 1
十 1
三 1
届 1
全 1
人 1
大 1
二 1
次 1
会 1
议 2
内 1
蒙 1
古 1
代 1
表 1
团 1
审 1
-------------counter bigram--------------
('5', '日') 1
('日', '下') 1
('下', '午') 1
('午', ',') 1
(',', '中') 1
('中', '共') 1
('共', '中') 1
('中', '央') 2
('央', '总') 1
('总', '书') 1
('书', '记') 1
('记', '、') 1
('、', '国') 1
('国', '家') 1
('家', '主') 1
('主', '席') 2
('席', '、') 1
('、', '中') 1
('央', '军') 1
('军', '委') 1
('委', '主') 1
('席', '习') 1
('习', '近') 1
('近', '平') 1
('平', '参') 1
('参', '加') 1
('加', '他') 1
('他', '所') 1
('所', '在') 1
('在', '的') 1
('的', '十') 1
('十', '三') 1
('三', '届') 1
('届', '全') 1
('全', '国') 1
('国', '人') 1
('人', '大') 1
('大', '二') 1
('二', '次') 1
('次', '会') 1
('会', '议') 1
('议', '内') 1
('内', '蒙') 1
('蒙', '古') 1
('古', '代') 1
('代', '表') 1
('表', '团') 1
('团', '审') 1
('审', '议') 1
-------------counter bigram--------------
('5', '日', '下') 1
('日', '下', '午') 1
('下', '午', ',') 1
('午', ',', '中') 1
(',', '中', '共') 1
('中', '共', '中') 1
('共', '中', '央') 1
('中', '央', '总') 1
('央', '总', '书') 1
('总', '书', '记') 1
('书', '记', '、') 1
('记', '、', '国') 1
('、', '国', '家') 1
('国', '家', '主') 1
('家', '主', '席') 1
('主', '席', '、') 1
('席', '、', '中') 1
('、', '中', '央') 1
('中', '央', '军') 1
('央', '军', '委') 1
('军', '委', '主') 1
('委', '主', '席') 1
('主', '席', '习') 1
('席', '习', '近') 1
('习', '近', '平') 1
('近', '平', '参') 1
('平', '参', '加') 1
('参', '加', '他') 1
('加', '他', '所') 1
('他', '所', '在') 1
('所', '在', '的') 1
('在', '的', '十') 1
('的', '十', '三') 1
('十', '三', '届') 1
('三', '届', '全') 1
('届', '全', '国') 1
('全', '国', '人') 1
('国', '人', '大') 1
('人', '大', '二') 1
('大', '二', '次') 1
('二', '次', '会') 1
('次', '会', '议') 1
('会', '议', '内') 1
('议', '内', '蒙') 1
('内', '蒙', '古') 1
('蒙', '古', '代') 1
('古', '代', '表') 1
('代', '表', '团') 1
('表', '团', '审') 1
('团', '审', '议') 1
[Finished in 0.4s]
3. 文本矩阵化:要求采用词袋模型且是词级别的矩阵化
步骤有:
分词(可采用结巴分词来进行分词操作,其他库也可以);去停用词;构造词表。
每篇文档的向量化。
3.1 结巴分词以及去停用词
1.分词可以用结巴分词(这里的词还是用前一个任务cnews.test.txt,但是我没用起来,然后我重新复制了保存到tt1.txt可以用了 )。
2.停用词可以在网上搜索一下下载保存成txt记得保存为utf-8的。

import jieba
import re
stopwords = {}
fstop = open('stop_words.txt', 'r',encoding='utf-8',errors='ingnore')
for eachWord in fstop:
stopwords[eachWord.strip()] = eachWord.strip() #停用词典
fstop.close()
f1=open('tt1.txt','r',encoding='utf-8',errors='ignore')
f2=open('fenci.txt','w',encoding='utf-8')
line=f1.readline()
while line:
line = line.strip() #去前后的空格
line = re.sub(r"[0-9\s+\.\!\/_,$%^*()?;;:-【】+\"\']+|[+——!,;:。?、~@#¥%……&*()]+", " ", line) #去标点符号
seg_list=jieba.cut(line,cut_all=False) #结巴分词
outStr=""
for word in seg_list:
if word not in stopwords:
outStr+=word
outStr+=" "
f2.write(outStr)
line=f1.readline()
f1.close()
f2.close()
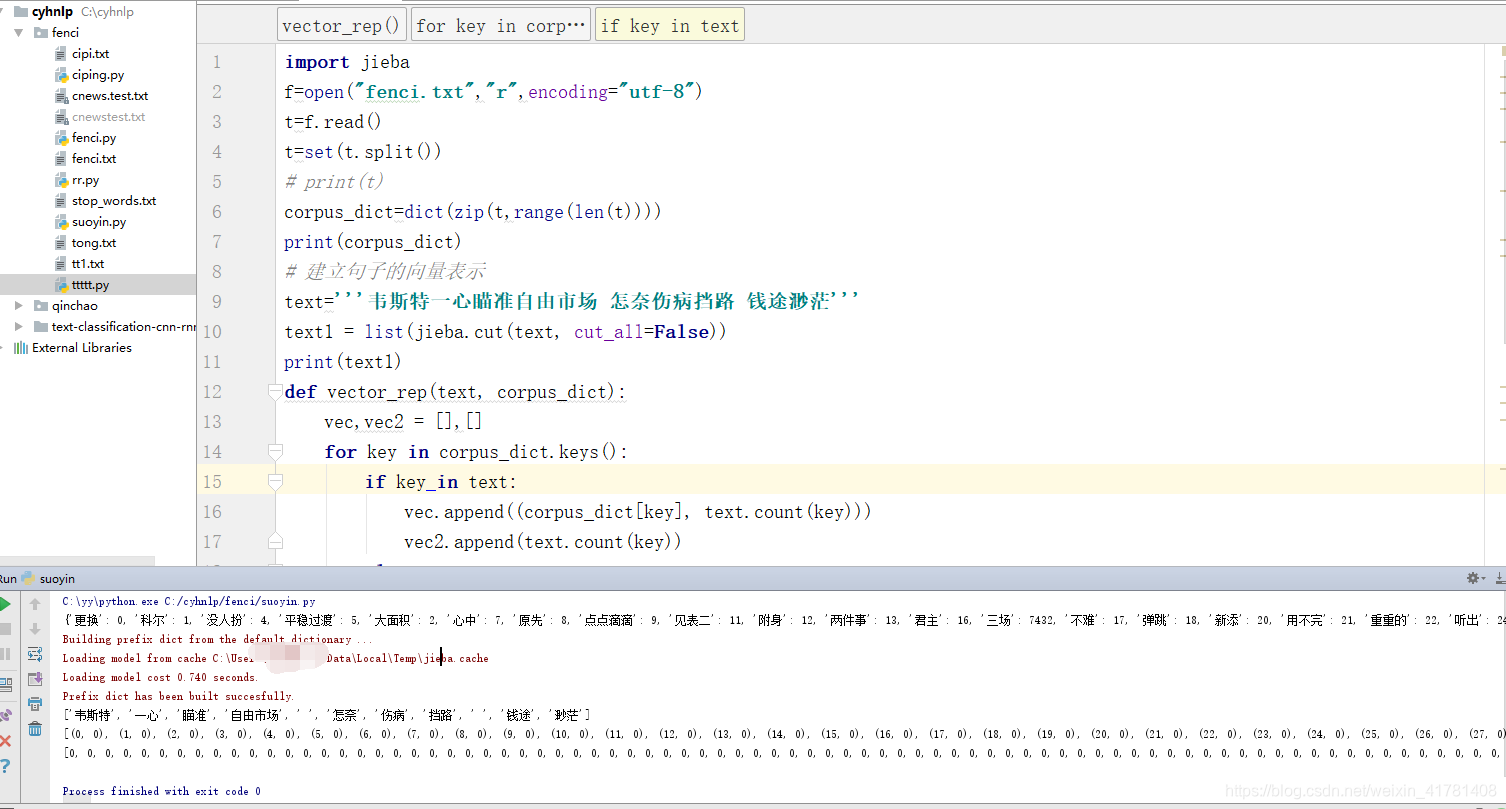
3.4 向量化
3.4.1 建立句子的向量表示
import jieba
f=open("fenci.txt","r",encoding="utf-8")
t=f.read()
t=set(t.split())
# print(t)
corpus_dict=dict(zip(t,range(len(t))))
print(corpus_dict)
# 建立句子的向量表示
text='''韦斯特一心瞄准自由市场 怎奈伤病挡路 钱途渺茫'''
text1 = list(jieba.cut(text, cut_all=False))
print(text1)
def vector_rep(text, corpus_dict):
vec,vec2 = [],[]
for key in corpus_dict.keys():
if key in text:
vec.append((corpus_dict[key], text.count(key)))
vec2.append(text.count(key))
else:
vec.append((corpus_dict[key], 0))
vec2.append(0)
vec = sorted(vec, key= lambda x: x[0])
return vec,vec2
vec1,vec2 = vector_rep(text1, corpus_dict)
print(vec1)
print(vec2)
f.close()
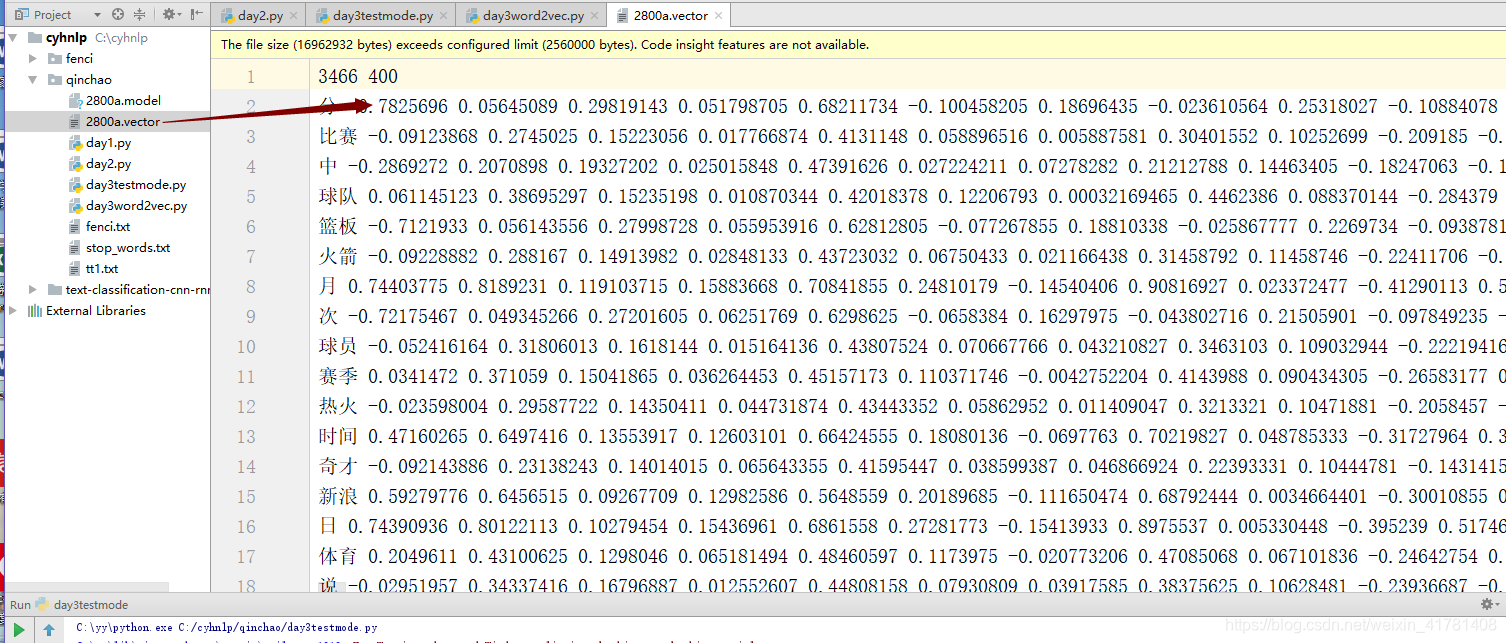
3.4.2 .采用Word2Vec处理结巴分词的文档
import warnings
warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim')
import logging
import os.path
import sys
import multiprocessing
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
if __name__=="__main__":
program=os.path.basename(sys.argv[0])
logger=logging.getLogger(program)
logging.basicConfig(format="%(asctime)s:%(levelname)s:%(message)s")
logger.info("running %s "% " ".join(sys.argv))
if len(sys.argv)<4:
print(globals()['__doc__']%local())
sys.exit()
inp,outp1,outp2=sys.argv[1:4]
model=Word2Vec(LineSentence(inp),size=400,window=5,min_count=5,workers=multiprocessing.cpu_count())
model.save(outp1)
model.wv.save_word2vec_format(outp2,binary=False)
# cmd python day3word2vec.py fenci.txt 2800a.model 2800a.vector 命令行中运行
处理好的模型的词嵌入向量。
如果有不对的希望大家提提意见,谢谢。
参考:
1.https://blog.csdn.net/u013061183/article/details/78259727
2.https://www.cnblogs.com/jclian91/p/9888381.html