自然语言处理(八)-卷积神经网络
1. 卷积运算的定义。
1.1卷积网络,
也叫卷积神经网络(CNN),是一种专门依赖处理具有类似网络结构的数据的神经网络。卷积是一种特殊的线性运算。卷积网络是指那些至少在网络的一层中使用卷积运算来代替一般的矩阵乘法运算的神经网络。
卷积神经网络的层级结构
• 数据输入层/ Input layer
• 卷积计算层/ CONV layer
• ReLU激励层 / ReLU layer
• 池化层 / Pooling layer
• 全连接层 / FC layer
1.1.1数据输入层
该层要做的处理主要是对原始图像数据进行预处理,其中包括:
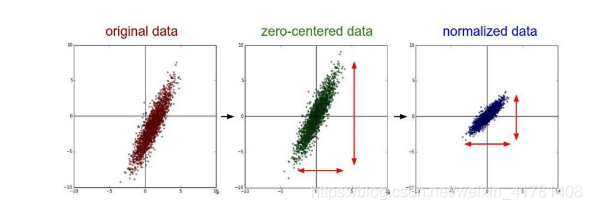
• 去均值:把输入数据各个维度都中心化为0,如下图所示,其目的就是把样本的中心拉回到坐标系原点上。
• 归一化:幅度归一化到同样的范围,如下所示,即减少各维度数据取值范围的差异而带来的干扰,比如,我们有两个维度的特征A和B,A范围是0到10,而B范围是0到10000,如果直接使用这两个特征是有问题的,好的做法就是归一化,即A和B的数据都变为0到1的范围。
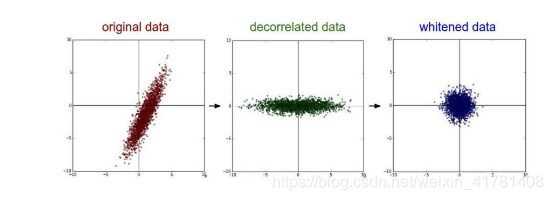
• PCA/白化:用PCA降维;白化是对数据各个特征轴上的幅度归一化。
去均值与归一化效果图:
去相关与白化效果图:
1.1.2.卷积计算层
这一层就是卷积神经网络最重要的一个层次,也是“卷积神经网络”的名字来源。
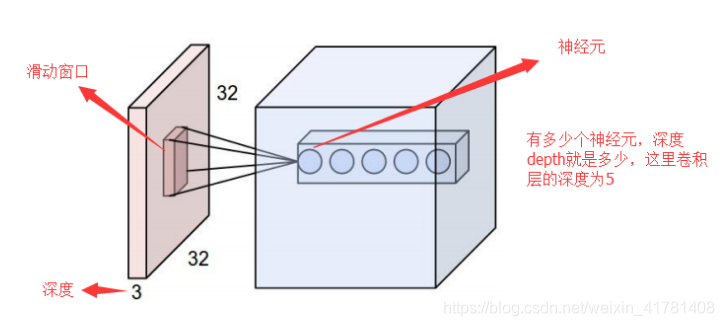
在这个卷积层,有两个关键操作:
• 局部关联。每个神经元看做一个滤波器(filter)
• 窗口(receptive field)滑动, filter对局部数据计算
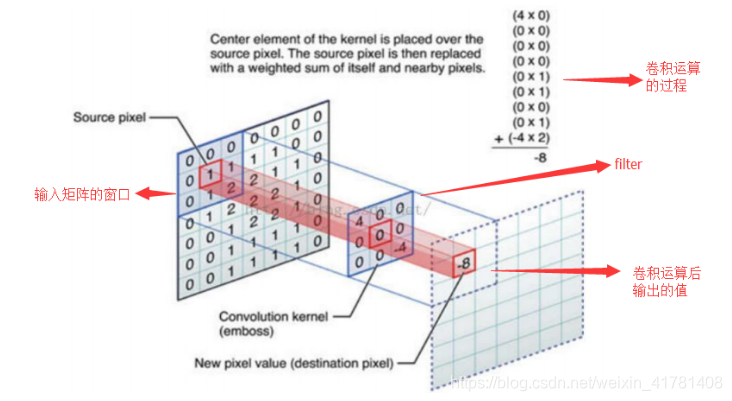
填充值是什么呢?以下图为例子,比如有这么一个55的图片(一个格子一个像素),我们滑动窗口取22,步长取2,那么我们发现还剩下1个像素没法滑完.
那我们在原先的矩阵加了一层填充值,使得变成6*6的矩阵,那么窗口就可以刚好把所有像素遍历完。这就是填充值的作用。
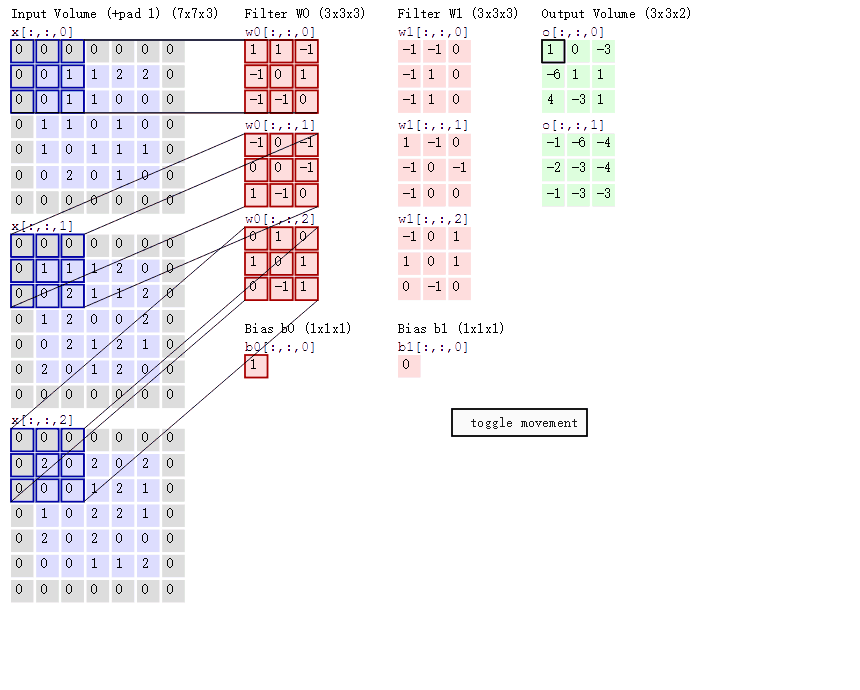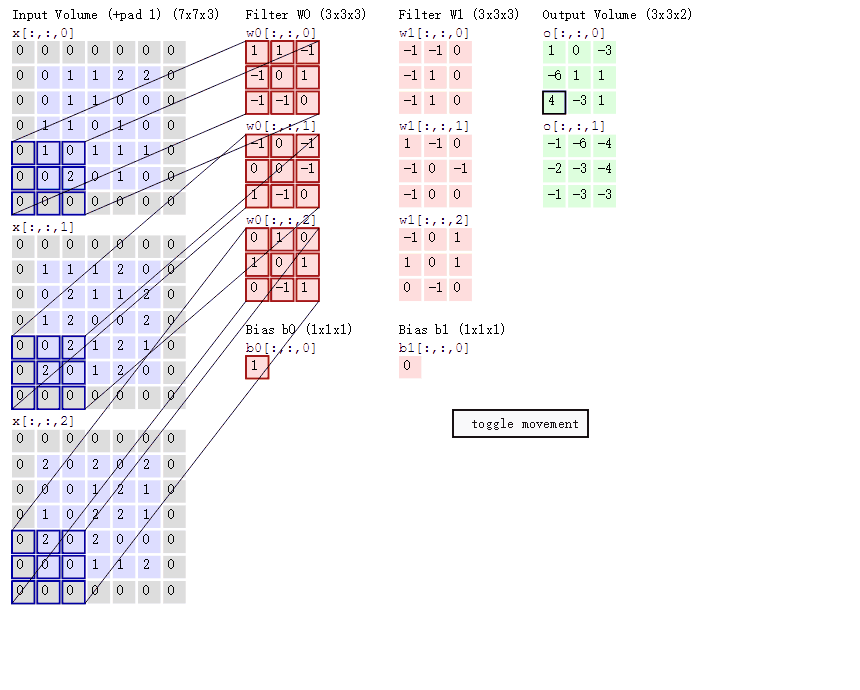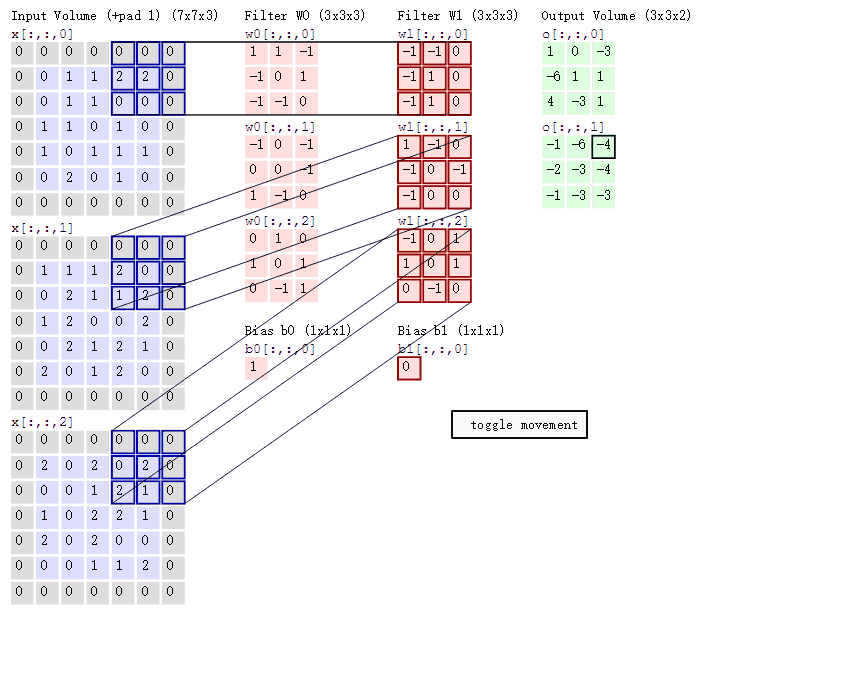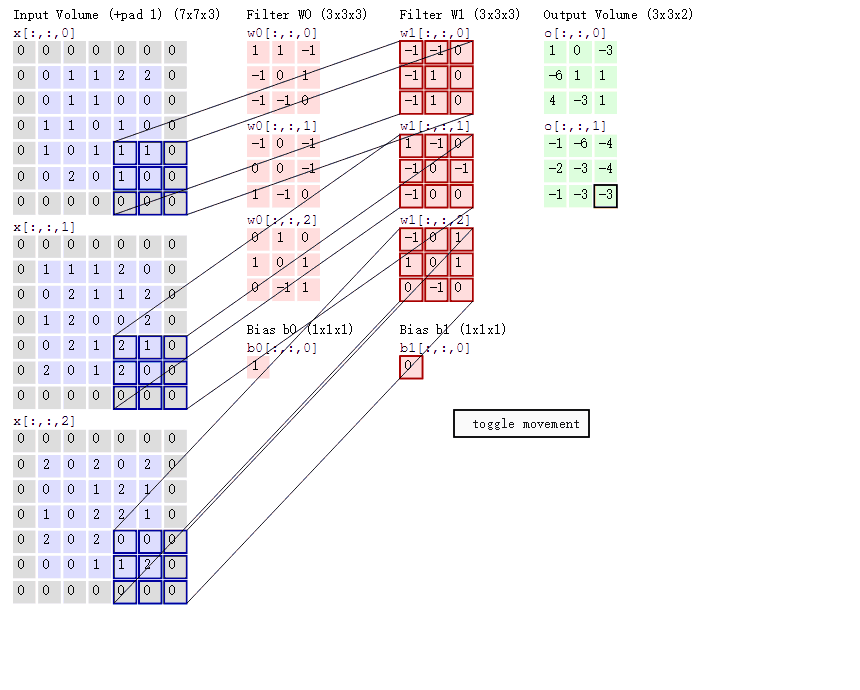
卷积的计算(注意,下面蓝色矩阵周围有一圈灰色的框,那些就是上面所说到的填充值)
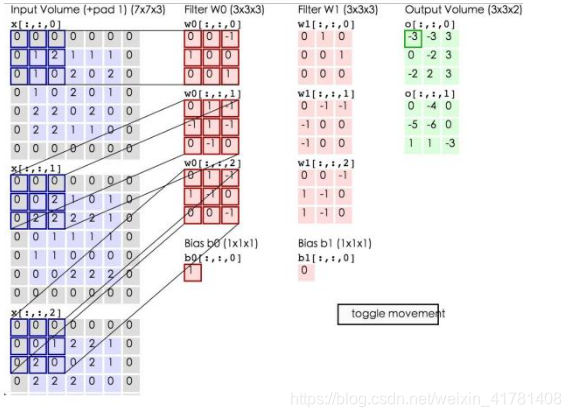
这里的蓝色矩阵就是输入的图像,粉色矩阵就是卷积层的神经元,这里表示了有两个神经元(w0,w1)。绿色矩阵就是经过卷积运算后的输出矩阵,这里的步长设置为2。
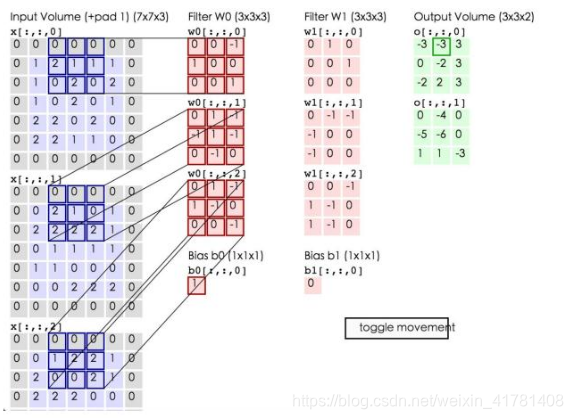
蓝色的矩阵(输入图像)对粉色的矩阵(filter)进行矩阵内积计算并将三个内积运算的结果与偏置值b相加(比如上面图的计算:2+(-2+1-2)+(1-2-2) + 1= 2 - 3 - 3 + 1 = -3),计算后的值就是绿框矩阵的一个元素。
1.1.3参数共享机制
• 在卷积层中每个神经元连接数据窗的权重是固定的,每个神经元只关注一个特性。神经元就是图像处理中的滤波器,比如边缘检测专用的Sobel滤波器,即卷积层的每个滤波器都会有自己所关注一个图像特征,比如垂直边缘,水平边缘,颜色,纹理等等,这些所有神经元加起来就好比就是整张图像的特征提取器集合。
• 需要估算的权重个数减少: AlexNet 1亿 => 3.5w
• 一组固定的权重和不同窗口内数据做内积: 卷积
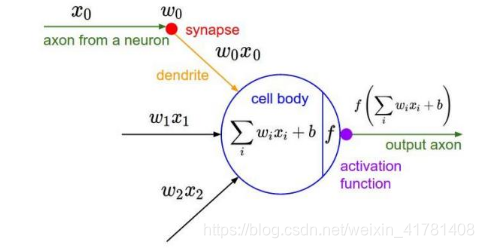
1.1.4.激励层
把卷积层输出结果做非线性映射。
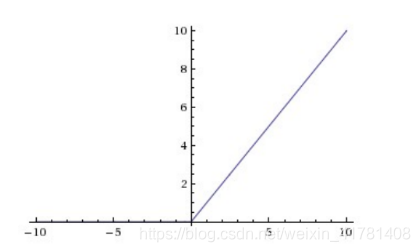
CNN采用的激励函数一般为ReLU(The Rectified Linear Unit/修正线性单元),它的特点是收敛快,求梯度简单,但较脆弱,图像如下。
1.1.5.池化层
池化层夹在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。
简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
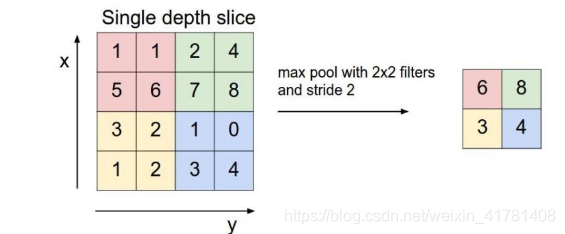
池化层用的方法有Max pooling 和 average pooling,而实际用的较多的是Max pooling。
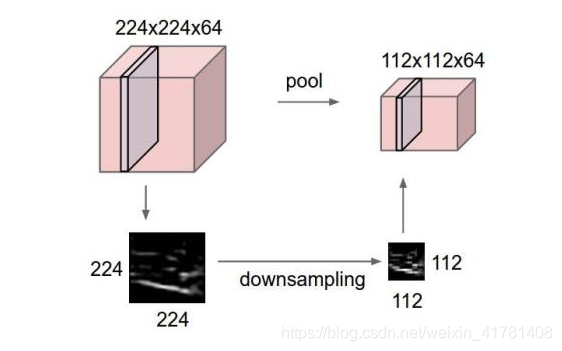
最大池化选择22中最大的一个
平均池化就是22的单元求平均值。
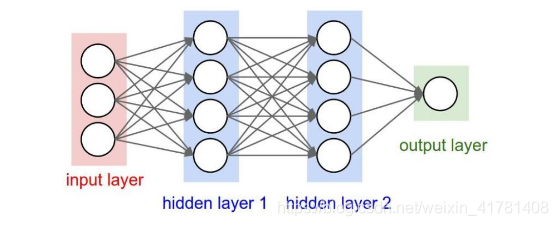
1.1.6.全连接层
两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。也就是跟传统的神经网络神经元的连接方式是一样的:
2. 反卷积(tf.nn.conv2d_transpose)
反卷积就是将原图片变大
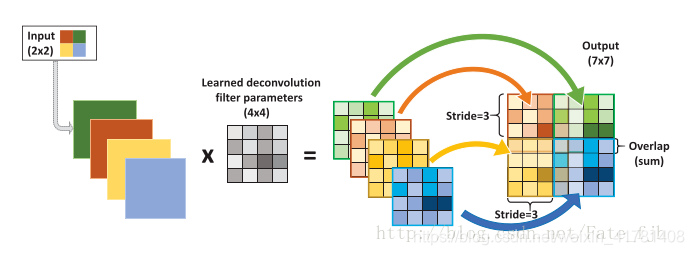
输入:2x2, 卷积核:4x4, 滑动步长:3, 输出:7x7
即输入为2x2的图片经过4x4的卷积核进行步长为3的反卷积的过程
1.输入图片每个像素进行一次full卷积,根据full卷积大小计算可以知道每个像素的卷积后大小为 1+4-1=4, 即4x4大小的特征图,输入有4个像素所以4个4x4的特征图
2.将4个特征图进行步长为3的fusion(即相加); 例如红色的特征图仍然是在原来输入位置(左上角),绿色还是在原来的位置(右上角),步长为3是指每隔3个像素进行fusion,重叠部分进行相加,即输出的第1行第4列是由红色特阵图的第一行第四列与绿色特征图的第一行第一列相加得到,其他如此类推。
可以看出反卷积的大小是由卷积核大小与滑动步长决定, in是输入大小, k是卷积核大小, s是滑动步长, out是输出大小
得到 out = (in - 1) * s + k
上图过程就是, (2 - 1) * 3 + 4 = 7
2. Text-CNN的原理。
TextCNN 是利用卷积神经网络对文本进行分类的算法,由 Yoon Kim 在 “Convolutional Neural Networks for Sentence Classification” 一文 (见参考[1]) 中提出. 是2014年的算法.
将卷积神经网络CNN应用到文本分类任务,利用多个不同size的kernel来提取句子中的关键信息(类似于多窗口大小的ngram),从而能够更好地捕捉局部相关性。
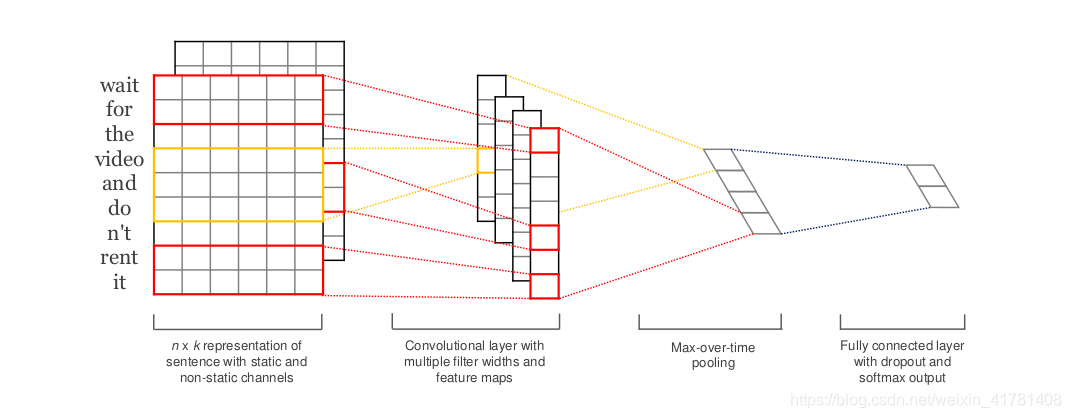
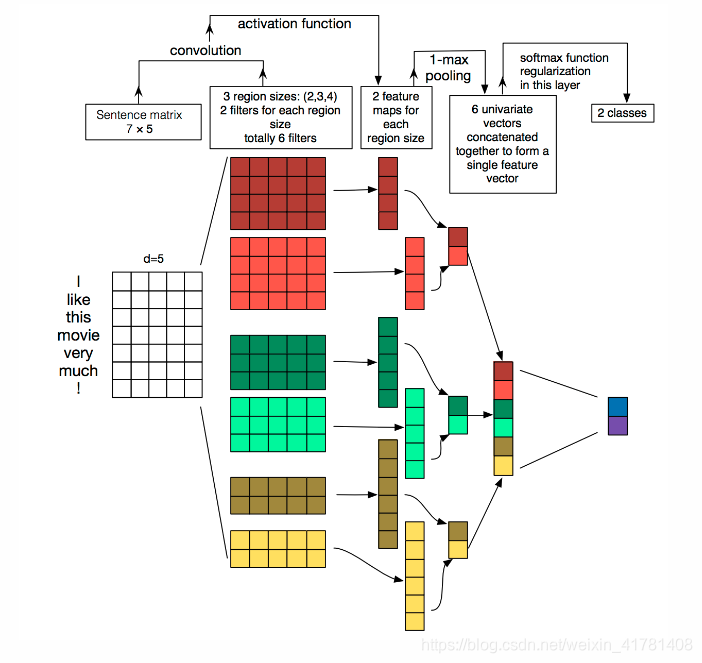
TextCNN详细过程:
Embedding:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。
Convolution:然后经过 kernel_sizes=(2,3,4) 的一维卷积层,每个kernel_size 有两个输出 channel。
MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
FullConnection and Softmax:最后接一层全连接的 softmax 层,输出每个类别的概率。
通道(Channels):
图像中可以利用 (R, G, B) 作为不同channel;
文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):
图像是二维数据;
文本是一维数据,因此在TextCNN卷积用的是一维卷积(在word-level上是一维卷积;虽然文本经过词向量表达后是二维数据,但是在embedding-level上的二维卷积没有意义)。一维卷积带来的问题是需要通过设计不同 kernel_size 的 filter 获取不同宽度的视野。
Pooling层:
利用CNN解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。
3. 利用Text-CNN模型来进行文本分类
3.1代码片
import logging
from keras import Input
from keras.layers import Conv1D, MaxPool1D, Dense, Flatten, concatenate, Embedding
from keras.models import Model
from keras.utils import plot_model
def textcnn(max_sequence_length, max_token_num, embedding_dim, output_dim, model_img_path=None, embedding_matrix=None):
""" TextCNN: 1. embedding layers, 2.convolution layer, 3.max-pooling, 4.softmax layer. """
x_input = Input(shape=(max_sequence_length,))
logging.info("x_input.shape: %s" % str(x_input.shape)) # (?, 60)
if embedding_matrix is None:
x_emb = Embedding(input_dim=max_token_num, output_dim=embedding_dim, input_length=max_sequence_length)(x_input)
else:
x_emb = Embedding(input_dim=max_token_num, output_dim=embedding_dim, input_length=max_sequence_length,
weights=[embedding_matrix], trainable=True)(x_input)
logging.info("x_emb.shape: %s" % str(x_emb.shape)) # (?, 60, 300)
pool_output = []
kernel_sizes = [2, 3, 4]
for kernel_size in kernel_sizes:
c = Conv1D(filters=2, kernel_size=kernel_size, strides=1)(x_emb)
p = MaxPool1D(pool_size=int(c.shape[1]))(c)
pool_output.append(p)
logging.info("kernel_size: %s \t c.shape: %s \t p.shape: %s" % (kernel_size, str(c.shape), str(p.shape)))
pool_output = concatenate([p for p in pool_output])
logging.info("pool_output.shape: %s" % str(pool_output.shape)) # (?, 1, 6)
x_flatten = Flatten()(pool_output) # (?, 6)
y = Dense(output_dim, activation='softmax')(x_flatten) # (?, 2)
logging.info("y.shape: %s \n" % str(y.shape))
model = Model([x_input], outputs=[y])
if model_img_path:
plot_model(model, to_file=model_img_path, show_shapes=True, show_layer_names=False)
model.summary()
return model