自然语言处理(五)
传统机器学习
1. 朴素贝叶斯的原理
1.1 朴素贝叶斯相关的统计学知识
贝叶斯学派很古老,但是从诞生到一百年前一直不是主流。主流是频率学派。频率学派的权威皮尔逊和费歇尔都对贝叶斯学派不屑一顾,但是贝叶斯学派硬是凭借在现代特定领域的出色应用表现为自己赢得了半壁江山。
贝叶斯学派的思想可以概括为先验概率+数据=后验概率。也就是说我们在实际问题中需要得到的后验概率,可以通过先验概率和数据一起综合得到。数据大家好理解,被频率学派攻击的是先验概率,一般来说先验概率就是我们对于数据所在领域的历史经验,但是这个经验常常难以量化或者模型化,于是贝叶斯学派大胆的假设先验分布的模型,比如正态分布,beta分布等。这个假设一般没有特定的依据,因此一直被频率学派认为很荒谬。虽然难以从严密的数学逻辑里推出贝叶斯学派的逻辑,但是在很多实际应用中,贝叶斯理论很好用,比如垃圾邮件分类,文本分类。
我们先看看条件独立公式,如果X和Y相互独立,则有:
P(X,Y)=P(X)P(Y)
P(X,Y)=P(X)P(Y)
我们接着看看条件概率公式:
P(Y|X)=P(X,Y)/P(X)
P(Y|X)=P(X,Y)/P(X)
P(X|Y)=P(X,Y)/P(Y)
P(X|Y)=P(X,Y)/P(Y)
或者说:
P(Y|X)=P(X|Y)P(Y)/P(X)
P(Y|X)=P(X|Y)P(Y)/P(X)
接着看看全概率公式
P(X)=∑kP(X|Y=Yk)P(Yk)其中∑kP(Yk)=1
P(X)=∑kP(X|Y=Yk)P(Yk)其中∑kP(Yk)=1
从上面的公式很容易得出贝叶斯公式:
P(Yk|X)=P(X|Yk)P(Yk)∑kP(X|Y=Yk)P(Yk)
基于朴素贝叶斯公式,比较出后验概率的最大值来进行分类,后验概率的计算是由先验概率与类条件概率的乘积得出,先验概率和类条件概率要通过训练数据集得出,即为朴素贝叶斯分类模型,将其保存为中间结果,测试文档进行分类时调用这个中间结果得出后验概率。
1.2基本定义
朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
朴素贝叶斯分类的正式定义如下:
1、设 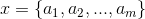 为一个待分类项,而每个a为x的一个特征属性。
为一个待分类项,而每个a为x的一个特征属性。
2、有类别集合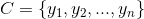 。
。
3、计算。
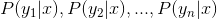
4、如果  ,则。
,则。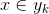
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、统计得到在各类别下各个特征属性的条件概率估计。即
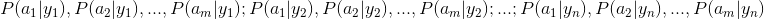
。
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
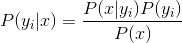
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
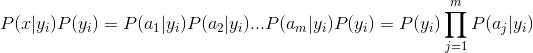
2. 利用朴素贝叶斯模型进行文本分类
2.1模型原理与训练
朴素贝叶斯分类器是一种有监督学习,常见有两种模型,多项式模型(multinomial model)即为词频型和伯努利模型(Bernoulli model)即文档型,还有一种高斯模型。
前二者的计算粒度不一样,多项式模型以单词为粒度,伯努利模型以文件为粒度,因此二者的先验概率和类条件概率的计算方法都不同。计算后验概率时,对于一个文档d,多项式模型中,只有在d中出现过的单词,才会参与后验概率计算,伯努利模型中,没有在d中出现,但是在全局单词表中出现的单词,也会参与计算,不过是作为“反方”参与的。
这里暂不考虑特征抽取、为避免消除测试文档时类条件概率中有为0现象而做的取对数等问题。
# -*- coding: UTF-8 -*-
from sklearn.naive_bayes import MultinomialNB
import matplotlib.pyplot as plt
import os
import random
import jieba
"""
函数说明:中文文本处理
Parameters:
folder_path - 文本存放的路径
test_size - 测试集占比,默认占所有数据集的百分之20
Returns:
all_words_list - 按词频降序排序的训练集列表
train_data_list - 训练集列表
test_data_list - 测试集列表
train_class_list - 训练集标签列表
test_class_list - 测试集标签列表
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-22
"""
def TextProcessing(folder_path, test_size = 0.2):
folder_list = os.listdir(folder_path) #查看folder_path下的文件
data_list = [] #数据集数据
class_list = [] #数据集类别
#遍历每个子文件夹
for folder in folder_list:
new_folder_path = os.path.join(folder_path, folder) #根据子文件夹,生成新的路径
files = os.listdir(new_folder_path) #存放子文件夹下的txt文件的列表
j = 1
#遍历每个txt文件
for file in files:
if j > 100: #每类txt样本数最多100个
break
with open(os.path.join(new_folder_path, file), 'r', encoding = 'utf-8') as f: #打开txt文件
raw = f.read()
word_cut = jieba.cut(raw, cut_all = False) #精简模式,返回一个可迭代的generator
word_list = list(word_cut) #generator转换为list
data_list.append(word_list) #添加数据集数据
class_list.append(folder) #添加数据集类别
j += 1
data_class_list = list(zip(data_list, class_list)) #zip压缩合并,将数据与标签对应压缩
random.shuffle(data_class_list) #将data_class_list乱序
index = int(len(data_class_list) * test_size) + 1 #训练集和测试集切分的索引值
train_list = data_class_list[index:] #训练集
test_list = data_class_list[:index] #测试集
train_data_list, train_class_list = zip(*train_list) #训练集解压缩
test_data_list, test_class_list = zip(*test_list) #测试集解压缩
all_words_dict = {} #统计训练集词频
for word_list in train_data_list:
for word in word_list:
if word in all_words_dict.keys():
all_words_dict[word] += 1
else:
all_words_dict[word] = 1
#根据键的值倒序排序
all_words_tuple_list = sorted(all_words_dict.items(), key = lambda f:f[1], reverse = True)
all_words_list, all_words_nums = zip(*all_words_tuple_list) #解压缩
all_words_list = list(all_words_list) #转换成列表
return all_words_list, train_data_list, test_data_list, train_class_list, test_class_list
"""
函数说明:读取文件里的内容,并去重
Parameters:
words_file - 文件路径
Returns:
words_set - 读取的内容的set集合
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-22
"""
def MakeWordsSet(words_file):
words_set = set() #创建set集合
with open(words_file, 'r', encoding = 'utf-8') as f: #打开文件
for line in f.readlines(): #一行一行读取
word = line.strip() #去回车
if len(word) > 0: #有文本,则添加到words_set中
words_set.add(word)
return words_set #返回处理结果
"""
函数说明:根据feature_words将文本向量化
Parameters:
train_data_list - 训练集
test_data_list - 测试集
feature_words - 特征集
Returns:
train_feature_list - 训练集向量化列表
test_feature_list - 测试集向量化列表
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-22
"""
def TextFeatures(train_data_list, test_data_list, feature_words):
def text_features(text, feature_words): #出现在特征集中,则置1
text_words = set(text)
features = [1 if word in text_words else 0 for word in feature_words]
return features
train_feature_list = [text_features(text, feature_words) for text in train_data_list]
test_feature_list = [text_features(text, feature_words) for text in test_data_list]
return train_feature_list, test_feature_list #返回结果
"""
函数说明:文本特征选取
Parameters:
all_words_list - 训练集所有文本列表
deleteN - 删除词频最高的deleteN个词
stopwords_set - 指定的结束语
Returns:
feature_words - 特征集
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-22
"""
def words_dict(all_words_list, deleteN, stopwords_set = set()):
feature_words = [] #特征列表
n = 1
for t in range(deleteN, len(all_words_list), 1):
if n > 1000: #feature_words的维度为1000
break
#如果这个词不是数字,并且不是指定的结束语,并且单词长度大于1小于5,那么这个词就可以作为特征词
if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1 < len(all_words_list[t]) < 5:
feature_words.append(all_words_list[t])
n += 1
return feature_words
"""
函数说明:新闻分类器
Parameters:
train_feature_list - 训练集向量化的特征文本
test_feature_list - 测试集向量化的特征文本
train_class_list - 训练集分类标签
test_class_list - 测试集分类标签
Returns:
test_accuracy - 分类器精度
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-22
"""
def TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list):
classifier = MultinomialNB().fit(train_feature_list, train_class_list)
test_accuracy = classifier.score(test_feature_list, test_class_list)
return test_accuracy
if __name__ == '__main__':
#文本预处理
folder_path = './SogouC/Sample' #训练集存放地址
all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = TextProcessing(folder_path, test_size=0.2)
# 生成stopwords_set
stopwords_file = './stopwords_cn.txt'
stopwords_set = MakeWordsSet(stopwords_file)
test_accuracy_list = []
deleteNs = range(0, 1000, 20) #0 20 40 60 ... 980
for deleteN in deleteNs:
feature_words = words_dict(all_words_list, deleteN, stopwords_set)
train_feature_list, test_feature_list = TextFeatures(train_data_list, test_data_list, feature_words)
test_accuracy = TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list)
test_accuracy_list.append(test_accuracy)
# ave = lambda c: sum(c) / len(c)
# print(ave(test_accuracy_list))
plt.figure()
plt.plot(deleteNs, test_accuracy_list)
plt.title('Relationship of deleteNs and test_accuracy')
plt.xlabel('deleteNs')
plt.ylabel('test_accuracy')
plt.show()
3. SVM的原理
3.1快速理解SVM原理
很多讲解SVM的书籍都是从原理开始讲解,如果没有相关知识的铺垫,理解起来还是比较吃力的,以下的一个例子可以让我们对SVM快速建立一个认知。
给定训练样本,支持向量机建立一个超平面作为决策曲面,使得正例和反例的隔离边界最大化。
决策曲面的初步理解可以参考如下过程,
1)如下图想象红色和蓝色的球为球台上的桌球,我们首先目的是找到一条曲线将蓝色和红色的球分开,于是我们得到一条黑色的曲线。
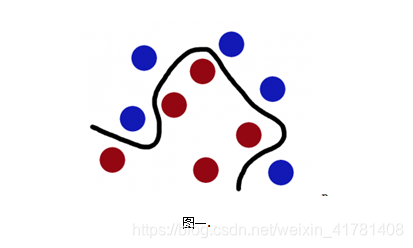
2) 为了使黑色的曲线离任意的蓝球和红球距离(也就是我们后面要提到的margin)最大化,我们需要找到一条最优的曲线。如下图,
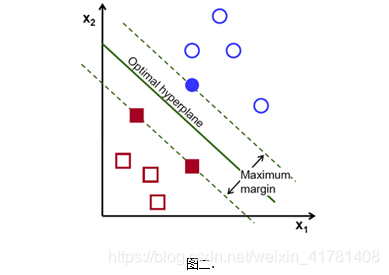
3) 想象一下如果这些球不是在球桌上,而是被抛向了空中,我们仍然需要将红色球和蓝色球分开,这时就需要一个曲面,而且我们需要这个曲面仍然满足跟所有任意红球和蓝球的间距的最大化。需要找到的这个曲面,就是我们后面详细了解的最优超平面。
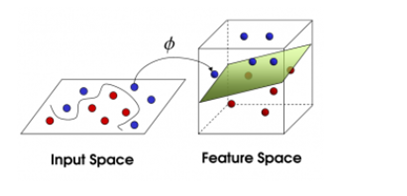
4) 离这个曲面最近的红色球和蓝色球就是Support Vector。
4. 利用SVM模型进行文本分类
具体 参考https://blog.csdn.net/Kaiyuan_sjtu/article/details/80064145
5. pLSA、共轭先验分布;LDA主题模型原理
pLSA:
参考:https://www.cnblogs.com/Determined22/p/7237111.html
LDA主题模型原理:
参考:http://www.cnblogs.com/pinard/p/6831308.html
6. 使用LDA生成主题特征,在之前特征的基础上加入主题特征进行文本分类
参考:https://blog.csdn.net/Kaiyuan_sjtu/article/details/83572927
参考:
1.https://blog.csdn.net/u013710265/article/details/72780520
2.https://blog.csdn.net/u013710265/article/details/72780520
3.https://blog.csdn.net/yyy430/article/details/88346920