Python数据分析:NLTK
Natural Language Toolkit
-
nlp领域中最常用的一个Python库
-
开源项目
-
自带分类、分词等功能
-
强大的社区支持
-
语料库,语言的实际使用中真实出现过的语言材料
-
语料库安装
import nltk
nltk.download()
语料库
- nltk.corpus
分词(tokenize)
-
将句子拆分成具有语言语义学上意义的词
-
中英文分词区别
- 英文单词之间是以空格作为自然分界符
- 中文没有一个形式上的分界符,分词比英文复杂
-
中文分词工具,jieba
-
得到分词结果后,中英文的后续处理类似
特殊字符的分词
- 使用正则表达式处理
词形问题
- look,looked,looking
- 影响预料学习的准确度
- 词形归一化
词形归一化
-
stemming,词干提取,如将ing,ed去掉,只保留单词主干
-
lemmatization,词形归并,将单词的各种词形归并成一种形式,如am,is,are归并为be
-
NLTK中的stemmer
- porterstemmer,snowballstemmer,lancasterstemmer
-
NLTK中的lemma
- wordnetlemmatizer
-
指定词性可以更准确的进行lemma
词性标注
-
NLTK中的词性标注 nltk.word_tokenize()
-
停用词(stopwords)
- 为节省存储空间和提高搜索效率,NLP会自动过滤掉某些字或词
- 停用词都是人工输入、非自动化生成的,形成停用词表
-
分类
- 语言中的功能词
- 使用广泛的词汇词
-
中文停用词表
- 中文停用词表
- 哈工大停用词表
- 四川大学机器智能实验室停用词库
- 百度停用词库
-
使用NLTK去除停用词 stopwords.words()
文本预处理流程:

import nltk
from nltk.corpus import brown # 需要下载brown语料库
# 引用布朗大学的语料库
# 查看语料库包含的类别
print(brown.categories())
运行:
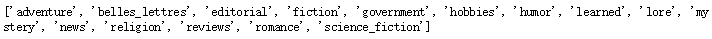
# 查看brown语料库
print('共有{}个句子'.format(len(brown.sents())))
print('共有{}个单词'.format(len(brown.words())))
运行:
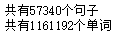
sentence = "Python is a widely used high-level programming language for general-purpose programming."
tokens = nltk.word_tokenize(sentence) # 需要下载punkt分词模型
print(tokens)
运行:
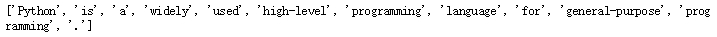
词干提取(stemming)
# PorterStemmer
from nltk.stem.porter import PorterStemmer
porter_stemmer = PorterStemmer()
print(porter_stemmer.stem('looked'))
print(porter_stemmer.stem('looking'))
# SnowballStemmer
from nltk.stem import SnowballStemmer
snowball_stemmer = SnowballStemmer('english')
print(snowball_stemmer.stem('looked'))
print(snowball_stemmer.stem('looking'))
# LancasterStemmer
from nltk.stem.lancaster import LancasterStemmer
lancaster_stemmer = LancasterStemmer()
print(lancaster_stemmer.stem('looked'))
print(lancaster_stemmer.stem('looking'))
运行:
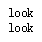
词形归并(lemmatization)
from nltk.stem import WordNetLemmatizer # 需要下载wordnet语料库
wordnet_lematizer = WordNetLemmatizer()
print(wordnet_lematizer.lemmatize('cats'))
print(wordnet_lematizer.lemmatize('boxes'))
print(wordnet_lematizer.lemmatize('are'))
print(wordnet_lematizer.lemmatize('went'))
运行:
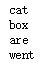
# 指明词性可以更准确地进行lemma
# lemmatize 默认为名词
print(wordnet_lematizer.lemmatize('are', pos='v'))
print(wordnet_lematizer.lemmatize('went', pos='v'))
运行:
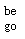
词性标注:
import nltk
words = nltk.word_tokenize('Python is a widely used programming language.')
print(nltk.pos_tag(words)) # 需要下载 averaged_perceptron_tagger
运行:

去除停用词:
from nltk.corpus import stopwords # 需要下载stopwords
filtered_words = [word for word in words if word not in stopwords.words('english')]
print('原始词:', words)
print('去除停用词后:', filtered_words)
运行:

文本预处理流程:
import nltk
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
# 原始文本
raw_text = 'Life is like a box of chocolates. You never know what you\'re gonna get.'
# 分词
raw_words = nltk.word_tokenize(raw_text)
# 词形归一化
wordnet_lematizer = WordNetLemmatizer()
words = [wordnet_lematizer.lemmatize(raw_word) for raw_word in raw_words]
# 去除停用词
filtered_words = [word for word in words if word not in stopwords.words('english')]
print('原始文本:', raw_text)
print('预处理结果:', filtered_words)
运行:
