目录
1.pandas的数据结构:Series和DataFrame
@python3.6.6;ubuntu18.04
一 numpy模块
1.numpy的数据结构:多维数组ndarray
Numpy最重要的一个特点就是其N维数组对象ndarray,ndarray是一个通用的同构数据多维容器,也就是说其中所有的元组必须是相同类型的,他接收一切序列类型的对象(包括其他数组)
1.1 创建数组
import numpy as np
In [15]: np.array([1,2,3])
Out[15]: array([1, 2, 3])#传入列表,产生一维数组
In [16]: np.array([[1,2,3],[4,5,6]])
Out[16]:
array([[1, 2, 3],
[4, 5, 6]])#传入嵌套列表,产生二维数组
#传入一个数组
In [22]: rnd=np.random.randn(12)
In [23]: rnd_re=rnd.reshape(3,4)#reshape,重新构造数组结构
In [24]: rnd
Out[24]:
array([ 0.65986137, 0.59780991, -0.29968381, -0.13900897, -0.91233434,
-1.11650251, 0.10361076, -0.99113903, -0.18876077, -1.07867959,
-1.35017413, -0.02826018])
In [25]: rnd_re
Out[25]:
array([[ 0.65986137, 0.59780991, -0.29968381, -0.13900897],
[-0.91233434, -1.11650251, 0.10361076, -0.99113903],
[-0.18876077, -1.07867959, -1.35017413, -0.02826018]])
In [26]: np.array(rnd_re)
Out[26]:
array([[ 0.65986137, 0.59780991, -0.29968381, -0.13900897],
[-0.91233434, -1.11650251, 0.10361076, -0.99113903],
[-0.18876077, -1.07867959, -1.35017413, -0.02826018]])
1.2 shape和dtype
shape表示各维度大小的元组,tdype用于说明数组数据类型的对象
In [1]: import numpy as np
In [2]: data=np.array([1,2,3])
In [3]: data.shape
Out[3]: (3,)
In [4]: data=np.array([[1,2,3],[4,5,6]])
In [5]: data.shape
Out[5]: (2, 3)
In [6]: data.dtype
Out[6]: dtype('int64')
1.3 empty、zeros、ones
empty创建一个没有任何具体值的数组(应该是无意义的虚数)
zeros创建一个全是0的数组
ones创建一个全是1的数组
In [30]: np.empty((3,3))
Out[30]:
array([[1.96923895e-316, 2.04482388e-316, 3.92581470e+170],
[2.33607195e-301, 5.94613337e-302, 2.29457644e+156],
[3.66137200e-244, 4.10074486e-322, 3.95252517e-322]])
In [32]: np.zeros((3,3))
Out[32]:
array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
In [33]: np.ones((3,3))
Out[33]:
array([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
1.4 arange
arange是python内置函数range的数组版
In [34]: np.arange(10)
Out[34]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
1.5 ndarray的数据类型
dtype(数据类型)是一个特殊对象,它含有ndarray将一块内存解释为特定数据类型所需的信息
主要有int64,int32,float64,float32等(不涉及底层工作,很少涉及,不用记)
#数值型dtype的命名方式相同:一个类型名(如int,float),后面跟一个表示各元素位长的数字,如float64
In [36]: np.array([1,2,3]).dtype
Out[36]: dtype('int64')
In [37]: data=np.array([1,2,3],dtype=np.float64)
In [38]: data.dtype
Out[38]: dtype('float64')
1.6 astype
通过astype可以显式的转换数组的数据类型
In [41]: data=np.array(['1','2','3'])
In [42]: data.dtype
Out[42]: dtype('<U1')
In [43]: data.astype(np.float64)#注意:使用astype会创建出一个新的数组(即不改变原始数据)
Out[43]: array([1., 2., 3.])
#astype也可用作调用其他数组的数据类型
In [44]: data1=np.array([1,2,3])
In [45]: data2=np.array(['1','2','3'])
In [46]: data2.astype(data1.dtype)
Out[46]: array([1, 2, 3])
1.7 数组和标量的运算
矢量化(vectorization),数组可以让你不是用循环即可对数据执行批量运算,这通常叫做矢量化
数组和标量之间的运算,会将运算应用到元素级,同样的,大小相等的数组之间的任何运算都会应用到元素级
广播:不同大小数组之间的运算叫做广播
In [47]: data=np.array([[1,2,3],[4,5,6]])
In [49]: data*data
Out[49]:
array([[ 1, 4, 9],
[16, 25, 36]])
In [52]: data*3
Out[52]:
array([[ 3, 6, 9],
[12, 15, 18]])
1.8索引和切片
一维数组很简单,类似python数据类型
In [53]: data=np.array([1,2,3])
In [54]: data[1]
Out[54]: 2
当你将一个标量值赋值给一个切片时,该值会自动传播到整个选区,跟列表最重要的区别在于,数组切片是原始数据的视图,即和数据不会被复制,视图上的任何修改都会直接反映到源数据,若需要得到数组的副本,需要使用data.copy()显式的复制
In [59]: data_arr=np.array([x for x in range(10)])
In [61]: arr_slice=data_arr[5:8]
In [62]: data_arr
Out[62]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [64]: arr_slice
Out[64]: array([5, 6, 7])
In [65]: arr_slice[1]=12345
In [66]: arr_slice
Out[66]: array([ 5, 12345, 7])
In [67]: data_arr
Out[67]:
array([ 0, 1, 2, 3, 4, 5, 12345, 7, 8,
9])
#给数组arr_slice赋值,会改变其源数据data_arr,而列表则不会
In [68]: data_list=[x for x in range(10)]
In [69]: list_slice=data_list[5:8]
In [70]: data_list
Out[70]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
In [71]: list_slice
Out[71]: [5, 6, 7]
In [72]: list_slice[1]=12345
In [73]: list_slice
Out[73]: [5, 12345, 7]
In [74]: data_list
Out[74]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
#使用copy()方法显式的复制源数据,则不会修改源数据
In [75]: data_arr=np.array([x for x in range(10)])
In [76]: data_arr
Out[76]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [77]: arr_slice=data_arr[5:8].copy()
In [78]: arr_slice
Out[78]: array([5, 6, 7])
In [79]: arr_slice=12345
In [80]: arr_slice
Out[80]: 12345
In [81]: data_arr
Out[81]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
二维数组中,索引位置上的元素不再是标量,而是一维数组,因此对各个元素进行递归访问需要的方法不同,其切片有两种方法实现,其中第一种类似嵌套列表的切片
In [84]: data_arr=np.array([[x for x in range(10)],[x for x in range(10,20)]])
In [85]: data_arr
Out[85]:
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]])
In [86]: data_arr[1][1]
Out[86]: 11
In [87]: data_arr[1,1]
Out[87]: 11
三维数组,切片取值可以理解为三层嵌套列表,同样可以使用两种方法表达
In [90]: data_arr=np.array([[[x for x in range(10)],[x for x in range(10,20)]],[
...: [x for x in range(20,30)],[x for x in range(40,50)]]])
In [91]: data_arr
Out[91]:
array([[[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]],
[[20, 21, 22, 23, 24, 25, 26, 27, 28, 29],
[40, 41, 42, 43, 44, 45, 46, 47, 48, 49]]])
In [95]: data_arr[1,1,1]
Out[95]: 41
In [92]: data_arr[1]
Out[92]:
array([[20, 21, 22, 23, 24, 25, 26, 27, 28, 29],
[40, 41, 42, 43, 44, 45, 46, 47, 48, 49]])
In [93]: data_arr[1][1]
Out[93]: array([40, 41, 42, 43, 44, 45, 46, 47, 48, 49])
In [94]: data_arr[1][1][1]
Out[94]: 41
布尔型索引
跟算术运算一样,数组的比较运算(如==)也是矢量花的,因此,对数据和字符串的比较运算将会产生一个布尔型数组,布尔型数组的轴长度跟被索引的数组的轴长度一致
In [105]: data=np.array(['a','b','c'])
In [106]: data=='d'
Out[106]: array([False, False, False])
In [107]: data!='d'
Out[107]: array([ True, True, True])
布尔型数组和整数数组混合使用
In [108]: data1=np.array(['a','b','c'])
In [109]: data2=np.array([1,2,3])
In [110]: data_boolean=data1=='a'
In [111]: data_boolean
Out[111]: array([ True, False, False])
In [112]: data2[data_boolean]
Out[112]: array([1])布尔算术运算符:& |
python中的and和or在numpy中无效
In [108]: data1=np.array(['a','b','c'])
In [109]: data2=np.array([1,2,3])
In [121]: data_boolean=(data1=='a')&(data1=='b')
In [122]: data_boolean
Out[122]: array([False, False, False])
In [123]: data_boolean=(data1=='a')|(data1=='b')
In [124]: data_boolean
Out[124]: array([ True, True, False])
In [125]: data2[data_boolean]
Out[125]: array([1, 2])
花式索引
花式索引(Fancy indexing)是一个Numpy术语,它指利用整数数组进行索引
#子集赋值
In [126]: arr=np.empty((8,4))
In [127]: arr
Out[127]:
array([[1.78873028e-316, 6.92799192e-310, 6.92799191e-310,
6.92799192e-310],
[6.92799191e-310, 6.92799191e-310, 6.92799191e-310,
6.92799191e-310],
[6.92799191e-310, 6.92799191e-310, 6.92799192e-310,
6.92799191e-310],
[6.92799192e-310, 6.92799191e-310, 6.92799191e-310,
6.92799192e-310],
[6.92799191e-310, 6.92799191e-310, 6.92799192e-310,
6.92799192e-310],
[6.92799191e-310, 6.92799191e-310, 5.41734680e-317,
6.92799191e-310],
[6.92799191e-310, 6.92799191e-310, 6.92799191e-310,
6.92799191e-310],
[6.92799192e-310, 6.92799192e-310, 6.92799192e-310,
6.92799191e-310]])
In [128]: for i in range(8):
...: arr[i]=i
...:
In [129]: arr
Out[129]:
array([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])
#为了以特定的顺序选取子集,只需要传入一个用于指定顺序的整数列表或ndarray即可
In [130]: arr[[4,3,0,6]]
Out[130]:
array([[4., 4., 4., 4.],
[3., 3., 3., 3.],
[0., 0., 0., 0.],
[6., 6., 6., 6.]])
#一次传入多个索引数组会有一点特别,他返回一个一维数组,其中的元素对应各个索引元组
In [133]: arr[[1,2,3,4],[5,6,7,0]]#第二个列表表示列的排序,不能超过3
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-133-b97868d57f0c> in <module>()
----> 1 arr[[1,2,3,4],[5,6,7,0]]
IndexError: index 5 is out of bounds for axis 1 with size 4
In [134]: arr[[1,4,5,7],[0,3,1,2]]#返回的是数组的第一列数据,即默认的索引
Out[134]: array([1., 4., 5., 7.])
In [143]: arr[[1,4,5,7]][:,[0,3,1,2]]#前面的列表表示子集,后面列表表示选取的子集的数据排列
Out[143]:
array([[ 4, 7, 5, 6],
[16, 19, 17, 18],
[20, 23, 21, 22],
[28, 31, 29, 30]])
#也可以使用np.ix_函数,它可以将两个一维整数数组转换为一个用于选取方形区域的索引
In [144]: arr[np.ix_([1,4,5,7],[0,3,1,2])]
Out[144]:
array([[ 4, 7, 5, 6],
[16, 19, 17, 18],
[20, 23, 21, 22],
[28, 31, 29, 30]])
二 pandas模块
1.pandas的数据结构:Series和DataFrame
Series 是一维标签数组(Data must be 1-dimension),能够保存任何数据类型(整型,浮点型,字符串或其他Python对象类型)。轴标签被称为索引
>>> import numpy as np
>>> import pandas as pd
>>> pd.Series(np.random.randn(12))#Series函数用于创建Series
0 0.445457
1 1.410470
2 -0.669725
3 -0.907310
4 0.081393
5 0.034115
6 1.219609
7 0.135690
8 -0.353035
9 0.640904
10 0.218566
11 0.836471
dtype: float64
>>> pd.Series(np.random.randn(12).reshape(3,4))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/zelin/.local/lib/python3.6/site-packages/pandas/core/series.py", line 275, in __init__
raise_cast_failure=True)
File "/home/zelin/.local/lib/python3.6/site-packages/pandas/core/series.py", line 4165, in _sanitize_array
raise Exception('Data must be 1-dimensional')
Exception: Data must be 1-dimensional
DataFrame是一个2维标签的数据结构,是一种表格型数据结构,它的列可以存在不同的类型,你可以把它简单的想成Excel表格或SQL Table,或者是包含字典类型的Series。它是最常用的Pandas对象。和Series一样,DataFrame接受许多不同的类型输入:
包含1维ndarray,列表对象,字典对象或者Series对象的字典对象
2维的ndarray对象
结构化或记录型的ndarray
Series对象
另一个DataFrame对象
#np.random.randn(12)产生一个服从正态分布的12个数字的一维数组,reshape(3,4)将数组重构为3行4列的二维数组
>>> pd.DataFrame(np.random.randn(12).reshape(3,4))#DataFrame函数用于创建DataFrame
0 1 2 3
0 -0.862802 1.176531 -0.009699 -0.455003
1 1.051637 -0.199708 0.402293 0.014919
2 0.588871 0.059458 1.911373 2.224995
分组运算:GroupBy技术
拆分--应用--合并
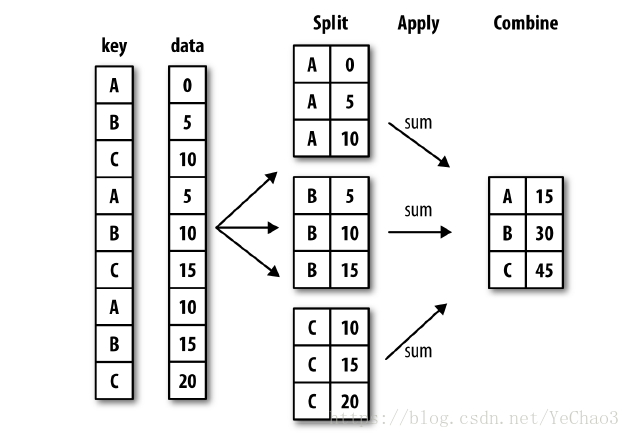
In [1]: import pandas as pd
In [2]: import numpy as np
#构建DataFrame
In [3]: df=pd.DataFrame({'key1':['a','a','b','b','a'],'key2':['one','two','one',
...: 'two','one'],'data1':np.random.randn(5),'data2':np.random.randn(5)})
In [4]: df
Out[4]:
key1 key2 data1 data2
0 a one -0.769863 0.321557
1 a two 0.163815 -0.635989
2 b one -1.048893 1.988060
3 b two -0.427548 0.322831
4 a one -1.115058 0.663252
#以键key1分组,获取data1的GroupBy对象
In [5]: grouped=df['data1'].groupby(df['key1'])
In [6]: grouped
Out[6]: <pandas.core.groupby.groupby.SeriesGroupBy object at 0x7fd8664248d0>
#GroupBy对象可以调用mean,sum等方法求平均值,和等值
In [7]: grouped.mean()#返回一个Series
Out[7]:
key1
a -0.573702
b -0.738221
Name: data1, dtype: float64
时间序列time series
时间序列是一种结构化数据形式,在多个时间点观测或测量到的任何事物都可以形成一段时间序列,时间序列数据的意义取决于具体的应用场景,主要有以下几种:
时间戳timestamp,特定的时刻
固定时期period,如2018全年
时间间隔interval,有起始和结束时间戳表示,时期period可以被看作间隔interval的特例
实验/过程时间,每个时间点都是相对于特定起始时间的一个度量,例如,从放入冰箱时起,每分钟橙子的温度python标准库包含用于日期date,时间time,日历calendar的datetime,time,calendar模块,datetime.datetime是用得最多的数据类型
详情见python之时间格式(datetime,time,calendar),此处只举例
In [47]: from datetime import datetime#datetime模块的datetime类用的最多
In [48]: import time
In [49]: import calendar
In [50]: datetime.now()#返回一个时间元组
Out[50]: datetime.datetime(2018, 10, 19, 15, 47, 17, 175724)
In [51]: time.time()#返回一个时间戳
Out[51]: 1539935328.026199
In [52]: calendar.calendar(2013)#传入年份,返回一个日历表
Out[52]: ' 2013\n\n January February March\nMo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su\n 1 2 3 4 5 6 1 2 3 1 2 3\n 7 8 9 10 11 12 13 4 5 6 7 8 9 10 4 5 6 7 8 9 10\n14 15 16 17 18 19 20 11 12 13 14 15 16 17 11 12 13 14 15 16 17\n21 22 23 24 25 26 27 18 19 20 21 22 23 24 18 19 20 21 22 23 24\n28 29 30 31 25 26 27 28 25 26 27 28 29 30 31\n\n April May June\nMo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su\n 1 2 3 4 5 6 7 1 2 3 4 5 1 2\n 8 9 10 11 12 13 14 6 7 8 9 10 11 12 3 4 5 6 7 8 9\n15 16 17 18 19 20 21 13 14 15 16 17 18 19 10 11 12 13 14 15 16\n22 23 24 25 26 27 28 20 21 22 23 24 25 26 17 18 19 20 21 22 23\n29 30 27 28 29 30 31 24 25 26 27 28 29 30\n\n July August September\nMo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su\n 1 2 3 4 5 6 7 1 2 3 4 1\n 8 9 10 11 12 13 14 5 6 7 8 9 10 11 2 3 4 5 6 7 8\n15 16 17 18 19 20 21 12 13 14 15 16 17 18 9 10 11 12 13 14 15\n22 23 24 25 26 27 28 19 20 21 22 23 24 25 16 17 18 19 20 21 22\n29 30 31 26 27 28 29 30 31 23 24 25 26 27 28 29\n 30\n\n October November December\nMo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su\n 1 2 3 4 5 6 1 2 3 1\n 7 8 9 10 11 12 13 4 5 6 7 8 9 10 2 3 4 5 6 7 8\n14 15 16 17 18 19 20 11 12 13 14 15 16 17 9 10 11 12 13 14 15\n21 22 23 24 25 26 27 18 19 20 21 22 23 24 16 17 18 19 20 21 22\n28 29 30 31 25 26 27 28 29 30 23 24 25 26 27 28 29\n 30 31\n'
时间序列基础
以时间为索引构建Series序列
In [57]: from datetime import datetime
#datetime传入数字参数,表示年,月,日,时,分,秒,年月日为必传参数,时分秒可选
In [62]: dates=[datetime(2018,10,19,10,0,0),datetime(2018,10,19,10,1,1),datetime
...: (2018,10,19,10,2,2)]
In [63]: s=pd.Series(np.random.randn(3),index=dates)
In [64]: s
Out[64]:
2018-10-19 10:00:00 2.450767
2018-10-19 10:01:01 -0.941043
2018-10-19 10:02:02 0.216157
dtype: float64
#这些datetime对象实际上是被放在列一个DatetimeIndex中,DatetimeIndex中的各个标量值是pandas的Timestamp对象
In [68]: type(s)
Out[68]: pandas.core.series.Series#--利用python进行数据分析书中显示为pandas.core.series.TimeSeries,与实际符,预计是新版本改变
In [69]: s.index
Out[69]:
DatetimeIndex(['2018-10-19 10:00:00', '2018-10-19 10:01:01',
'2018-10-19 10:02:02'],
dtype='datetime64[ns]', freq=None)
索引,选取,子集构造
In [82]: dates=[datetime(2018,10,19,10,0,0),datetime(2018,10,19,10,1,1),datetime
...: (2018,10,19,10,2,2),datetime(2018,10,19,10,3,3),datetime(2018,10,19,10,
...: 4,4)]
In [83]: s=pd.Series(np.random.randn(5),index=dates)
In [84]: s
Out[84]:
2018-10-19 10:00:00 0.879305
2018-10-19 10:01:01 1.218865
2018-10-19 10:02:02 -0.859521
2018-10-19 10:03:03 -1.272252
2018-10-19 10:04:04 0.200955
dtype: float64
In [85]: stamp=s.index[2]
In [86]: s[stamp]
Out[86]: -0.8595210222802377#获取到第三行的值
#索引也可传入一个可被解释为日期的字符串
In [90]: s['20181019100202']
Out[90]: -0.8595210222802377
In [92]: s['19/10/2018 10:02:02']
Out[92]: -0.8595210222802377
#当传入索引前相同部分的字符串,也可用作切片
In [93]: s['19/10/2018']时间字符串格式之一
Out[93]:
2018-10-19 10:00:00 0.879305
2018-10-19 10:01:01 1.218865
2018-10-19 10:02:02 -0.859521
2018-10-19 10:03:03 -1.272252
2018-10-19 10:04:04 0.200955
dtype: float64
In [94]: s['20181019']#时间字符串格式之一
Out[94]:
2018-10-19 10:00:00 0.879305
2018-10-19 10:01:01 1.218865
2018-10-19 10:02:02 -0.859521
2018-10-19 10:03:03 -1.272252
2018-10-19 10:04:04 0.200955
dtype: float64
#由于大部分时间序列数据都是按照时间先后排序的,因此也可以用不存在于该时间序类中的时间戳对其进行切片(即范围查询)
In [98]: s['19/10/2018 10:0:0':'19/10/2018 10:01:02']
Out[98]:
2018-10-19 10:00:00 0.879305
2018-10-19 10:01:01 1.218865
dtype: float64
#实例方法truncate也能实现截取两个日期时间的Series,所选范围为闭端,即包含所穿参数
In [105]: s.truncate(after='20181019100303',before='20181019100000')
Out[105]:
2018-10-19 10:00:00 0.879305
2018-10-19 10:01:01 1.218865
2018-10-19 10:02:02 -0.859521
2018-10-19 10:03:03 -1.272252
dtype: float64
带有重复索引的时间序列
#当索引为不重复项时,返回标量值,当索引为重复项时,返回Series序列
In [109]: s['20181001']
Out[109]:
2018-10-01 -1.217149
2018-10-01 -1.714301
dtype: float64
In [113]: s['20181003']
Out[113]: 0.14757289913298496
注意:datetime不能传入01,02等0开头的参数,会报错
In [122]: dates=[datetime(2011,01,02),datetime(2011,01,05),datetime(2011,01,07),
...: datetime(2011,01,08),datetime(2011,01,10),datetime(2011,01,12)]
File "<ipython-input-122-98aa28d7950b>", line 1
dates=[datetime(2011,01,02),datetime(2011,01,05),datetime(2011,01,07),datetime(2011,01,08),datetime(2011,01,10),datetime(2011,01,12)]
^
SyntaxError: invalid token
In [123]: dates=[datetime(2011,1,2),datetime(2011,1,5),datetime(2011,1,7),dateti
...: me(2011,1,8),datetime(2011,1,10),datetime(2011,1,12)]
生成日期范围
#pandas.date_range可用于指定长度的DatetimeIndex,默认情况下,产生按天计算的时间点,date_range默认保留起始和结束日期,即闭端
In [139]: index=pd.date_range('4/1/2018','4/10/2018')#月日年
In [140]: s=pd.Series(np.random.randn(10),index=index)
In [141]: s
Out[141]:
2018-04-01 -0.667058
2018-04-02 1.781576
2018-04-03 -0.845532
2018-04-04 -1.121527
2018-04-05 0.572054
2018-04-06 -0.120728
2018-04-07 1.396313
2018-04-08 1.559138
2018-04-09 0.737590
2018-04-10 1.905737
Freq: D, dtype: float64
#如果给参数period传入一个表示索引个数的数字,可以设定索引间隔时间,即时间差/periods
In [149]: index=pd.date_range(start='4/1/2018',end='4/10/2018',periods=5)#表示间隔两天,产生5个索引,即5等分时间差
In [150]: s=pd.Series(np.random.randn(5),index=index)
In [151]: s
Out[151]:
2018-04-01 00:00:00 -1.440547
2018-04-03 06:00:00 0.295920
2018-04-05 12:00:00 0.297291
2018-04-07 18:00:00 -0.753377
2018-04-10 00:00:00 1.643616
dtype: float64
#如果希望产生一组被规范化到午夜的时间戳,normalize参数可实现该功能,即忽略时间,从开始日期的零点始,结束日期的零点终
In [155]: index=pd.date_range(start='4/1/2018 08:04:22',end='4/10/2018 12:12:21'
...: ,periods=5)
In [156]: index=pd.date_range(start='4/1/2018',end='4/10/2018',periods=5,normali
...: ze=True)
In [157]: s=pd.Series(np.random.randn(5),index=index)
In [158]: s
Out[158]:
2018-04-01 00:00:00 1.209585
2018-04-03 06:00:00 -1.129351
2018-04-05 12:00:00 -1.488379
2018-04-07 18:00:00 -0.882576
2018-04-10 00:00:00 -0.152073
dtype: float64
频率和基础偏移量
pandas中的频率是由一个基础频率(hbase frequency)和一个乘数组成的,基础频率通常以一个字符串别名表示,比如'M'表示月,'H'表示小时,对于每个基础频率,都有一个被称为日期偏移量(date offset)的对象与之对应
In [159]: from pandas.tseries.offsets import Hour,Minute
In [160]: hour=Hour()#基础频率
In [161]: hour
Out[161]: <Hour>
In [162]: four_hours=Hour(4)#导入一个整数即可定义偏移量的倍数
In [163]: four_hours
Out[163]: <4 * Hours>
#一般无需显式创建这样的对象,在date_range函数前传入参数freq,参数值使用诸如'h','4h'这样的字符串别名的整数倍
In [164]: dates=pd.date_range('20181211','20181220',freq='2d')#字符串别名不区分大小写
In [165]: s=pd.Series(np.random.randn(5),index=dates)
In [166]: s
Out[166]:
2018-12-11 -0.031886
2018-12-13 0.827174
2018-12-15 0.317349
2018-12-17 -1.938784
2018-12-19 -0.410817
Freq: 2D, dtype: float64
#也可以传入频率字符串:如'4h30min',这种字符串可以被高效的解析为等效的表达式
In [168]: dates=pd.date_range('20181211','20181220',freq='2d48h')
In [170]: s=pd.Series(np.random.randn(3),index=dates)
In [171]: s
Out[171]:
2018-12-11 -1.380608
2018-12-15 -0.012547
2018-12-19 -0.858346
Freq: 4D, dtype: float64
#大部分偏移量对象都可以用'+'加号连接
In [167]: Hour(2)+Minute(30)
Out[167]: <150 * Minutes>
时间序列的常见基础频率表
注意:有些频率描述的时间点不是均匀分隔的,如‘M’日里月末和’BM’每月最后一个工作日,对于前者,就取决于每月的天数,对于后者,还要考虑月末是不是周末,我们称这些为锚点偏移量
| 别名 | 偏移量类型 | 说明 |
| D | Day | 每日历日 |
| B | BussinessDay | 每工作日 |
| H | Hour | 每小时 |
| T/min | Minute | 每分 |
| S | Second | 每秒 |
| L/ms | Milli | 每毫秒(即千分之一秒) |
| U | Micro | 每微秒(即每百万分之一秒) |
| M | MonthEnd | 每月最后一个日历日 |
| BM | BusinessMonthEnd | 每月最后一个工作日 |
| MS | MonthBegin | 每月第一个日历日 |
| BMS | BusinessMonthBegin | 每月第一个工作日 |
| W-MON,W-TUE.... | Week | 从指定的星期几开始计算 |
| WOM-1MON,WOM-2MON... | 从指定的每月第一,第二...周的星期即,例如:WOM-3FRI表示每月的第三隔星期五 | |
| A-JAN,A-FEB | YearEnd | 每年指定月份的最后一个日历日 |
| BA-JAN,BA-FEB | BusinessYearEnd | 每年指定月份的最后一个工作日 |
| AS-JAN,AS-FEB | YearBegin | 每年指定月份的第一个日历日 |
| BAS-JAN,BAS-FEB | BusinessYearBegin | 每年指定月份的第一个工作日 |
WOM日期
WOM(Week Of Month)是一种非常使用的频率类,它以WOM开头,它使你能获得'每月第3隔星期五'之类的日期
In [172]: rng=pd.date_range('1/1/2018','9/1/2018',freq='WOM-3FRI')
In [173]: list(rng)
Out[173]:
[Timestamp('2018-01-19 00:00:00', freq='WOM-3FRI'),
Timestamp('2018-02-16 00:00:00', freq='WOM-3FRI'),
Timestamp('2018-03-16 00:00:00', freq='WOM-3FRI'),
Timestamp('2018-04-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2018-05-18 00:00:00', freq='WOM-3FRI'),
Timestamp('2018-06-15 00:00:00', freq='WOM-3FRI'),
Timestamp('2018-07-20 00:00:00', freq='WOM-3FRI'),
Timestamp('2018-08-17 00:00:00', freq='WOM-3FRI')]
移动(超前或滞后)数据
移动(shifting)指的是沿着时间轴将数据前移或者后移,但保持索引不变
In [4]: ts=pd.Series(np.random.randn(4),index=pd.date_range('1/1/2018',periods=4
...: ,freq='M'))
#periods=4表示以1/1/2018为起始日期产生4个时间索引,间隔为月,即freq='M'
In [5]: ts
Out[5]:
2018-01-31 0.467078
2018-02-28 -0.664430
2018-03-31 -0.823731
2018-04-30 2.407555
Freq: M, dtype: float64
In [14]: ts.shift(2)#正整数向下移
Out[14]:
2018-01-31 NaN
2018-02-28 NaN
2018-03-31 0.467078
2018-04-30 -0.664430
Freq: M, dtype: float64
In [15]: ts.shift(-2)#负整数向上移动
Out[15]:
2018-01-31 -0.823731
2018-02-28 2.407555
2018-03-31 NaN
2018-04-30 NaN
Freq: M, dtype: float64
#shift通常用于计算一个时间序列或多个时间序列中的百分比变化,可以这样表达:
ts/ts.shift(1)-1
#由于单纯的位移操作不会修改索引,所以部分数据会被丢弃,因此如果频率已知,则可以将频率freq传给shift以便实现移动时间戳进行位移,而不是移动数据:
In [17]: ts.shift(2,freq='M')
Out[17]:
2018-03-31 0.467078
2018-04-30 -0.664430
2018-05-31 -0.823731
2018-06-30 2.407555
Freq: M, dtype: float64
#还可以使用其他频率,于是就能非常灵活地对数据进行超前或滞后处理了
In [21]: ts.shift(1,'3d')
Out[21]:
2018-02-03 0.467078
2018-03-03 -0.664430
2018-04-03 -0.823731
2018-05-03 2.407555
dtype: float64
In [22]: ts.shift(3,'d')
Out[22]:
2018-02-03 0.467078
2018-03-03 -0.664430
2018-04-03 -0.823731
2018-05-03 2.407555
dtype: float64
通过偏移量对日期进行位移
pandas的日期偏移量还可以用在datetime和Timestamp对象上
In [25]: from pandas.tseries.offsets import Day,MonthEnd
In [26]: now=datetime(2011,11,7)
In [27]: now+3*Day()
Out[27]: Timestamp('2011-11-10 00:00:00')
#如果加的是锚点偏移量,第一次增量会将原日期向前滚动到符合频率规则的下一个日期,比如第一次位移的量可能没有一个月那么长,就在当月
In [26]: now=datetime(2011,11,7)
In [27]: now+3*Day()
Out[27]: Timestamp('2011-11-10 00:00:00')
In [28]: now+MonthEnd()
Out[28]: Timestamp('2011-11-30 00:00:00')
In [29]: now+2*MonthEnd()
Out[29]: Timestamp('2011-12-31 00:00:00')
In [30]: now+MonthEnd(2)
Out[30]: Timestamp('2011-12-31 00:00:00')
#通过锚点偏移量的rollforward和rollback方法,可以显式的将日期前移或向后滚动
In [31]: offset=MonthEnd()
In [32]: offset.rollforward(now)#向前翻滚就是本月
Out[32]: Timestamp('2011-11-30 00:00:00')
In [33]: offset.rollback(now)#前后翻滚就是上一个月
Out[33]: Timestamp('2011-10-31 00:00:00')
#结合groupby使用前后滚动
In [34]: ts=pd.Series(np.random.randn(20),index=pd.date_range('1/15/2018',period
...: s=20,freq='4d'))
In [35]: ts
Out[35]:
2018-01-15 -1.123869
2018-01-19 0.691454
2018-01-23 -1.492071
2018-01-27 0.047393
2018-01-31 0.190645
2018-02-04 -1.427506
2018-02-08 0.318326
2018-02-12 -0.073011
2018-02-16 0.636296
2018-02-20 -0.570525
2018-02-24 -0.865244
2018-02-28 -0.356154
2018-03-04 -0.247588
2018-03-08 0.589253
2018-03-12 1.113633
2018-03-16 1.722783
2018-03-20 -2.332676
2018-03-24 -0.275168
2018-03-28 -0.171739
2018-04-01 -0.369748
Freq: 4D, dtype: float64
In [36]: ts.groupby(offset.rollforward).mean()#全部转换为几类相同日期,然后分类
Out[36]:
2018-01-31 -0.337290
2018-02-28 -0.333974
2018-03-31 0.056928
2018-04-30 -0.369748
dtype: float64
#结合groupby函数使用滚动的封装方法:resample
In [38]: ts.resample('M',how='mean')#python2
/usr/bin/ipython3:1: FutureWarning: how in .resample() is deprecated
the new syntax is .resample(...).mean()
#! /bin/sh
Out[38]:
2018-01-31 -0.337290
2018-02-28 -0.333974
2018-03-31 0.056928
2018-04-30 -0.369748
Freq: M, dtype: float64
#结合groupby函数使用滚动的封装方法:resample
In [39]: ts.resample('M').mean()#python3
Out[39]:
2018-01-31 -0.337290
2018-02-28 -0.333974
2018-03-31 0.056928
2018-04-30 -0.369748
Freq: M, dtype: float64
时区处理
时区信息来自python库pytz,它使python可以使用Olso数据库(汇编了世界时区信息),由于pandas包装了pytz的功能,因此可以不用记其API,只要记住时区名即可,时区名可以在文档中找到,也可以通过交互查看
In [42]: import pytz#时区信息库
In [43]: pytz.timezone('US/Eastern')#获取时区信息,
Out[43]: <DstTzInfo 'US/Eastern' LMT-1 day, 19:04:00 STD>
In [48]: pytz.common_timezones[1]#时区名称列表
Out[48]: 'Africa/Accra'
本地化和转换
默认情况下,pandas中的时间序列是单纯的(naive)时区,其索引的tz字段为None,在生成日期范围的时候还可以加上一个时区集,从单纯到本地化的转换是通过tz_locallize方法处理的:
In [56]: rng=pd.date_range('3/9/2018 9:30',periods=6,freq='D')
In [57]: ts=pd.Series(np.random.randn(len(rng)),index=rng)
In [58]: ts
Out[58]:
2018-03-09 09:30:00 -1.470021
2018-03-10 09:30:00 -1.171575
2018-03-11 09:30:00 0.739337
2018-03-12 09:30:00 -0.990569
2018-03-13 09:30:00 0.007370
2018-03-14 09:30:00 0.389544
Freq: D, dtype: float64
In [62]: rng.tz
In [63]: #返回值为空
In [52]: ts1=pd.date_range('3/9/2018 9:30',periods=10,freq='D',tz='UTC')
Out[52]:
DatetimeIndex(['2018-03-09 09:30:00+00:00', '2018-03-10 09:30:00+00:00',
'2018-03-11 09:30:00+00:00', '2018-03-12 09:30:00+00:00',
'2018-03-13 09:30:00+00:00', '2018-03-14 09:30:00+00:00',
'2018-03-15 09:30:00+00:00', '2018-03-16 09:30:00+00:00',
'2018-03-17 09:30:00+00:00', '2018-03-18 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq='D')
In [55]: ts1.tz#默认tz属性为None
Out[55]: <UTC>
In [65]: ts_utc=ts.tz_localize('UTC')
#使用tz_localize转换为UTC本地时区
In [66]: ts_utc
Out[66]:
2018-03-09 09:30:00+00:00 -1.470021
2018-03-10 09:30:00+00:00 -1.171575
2018-03-11 09:30:00+00:00 0.739337
2018-03-12 09:30:00+00:00 -0.990569
2018-03-13 09:30:00+00:00 0.007370
2018-03-14 09:30:00+00:00 0.389544
Freq: D, dtype: float64
#当时间序列被本地化到某个特定时区,就可以用tz_convert将其转换为别的时区了
In [67]: ts_utc.tz_convert('US/Eastern')
Out[67]:
2018-03-09 04:30:00-05:00 -1.470021
2018-03-10 04:30:00-05:00 -1.171575
2018-03-11 05:30:00-04:00 0.739337
2018-03-12 05:30:00-04:00 -0.990569
2018-03-13 05:30:00-04:00 0.007370
2018-03-14 05:30:00-04:00 0.389544
Freq: D, dtype: float64
#tz_localize和tz_convert是DatetimeIndex的实例方法,对于单纯时间戳的本地化操作还会检查夏令时转变期附近容易混淆或不存在的时间
操作时区意识型Timestamp对象
跟时间序列和日期范围差不多,Timestamp对象也能被从单纯型(naive)本地化为时区意识型(time zone-aware),并从一个时区转换为另一个时区
#单纯时区和本地时区之间可以灵活转换
In [70]: stamp=pd.Timestamp('2011-03-12 04:00')#创建Timestamp
In [71]: stamp
Out[71]: Timestamp('2011-03-12 04:00:00')
In [72]: stamp_utc=stamp.tz_localize('utc')
In [73]: stamp_utc
Out[73]: Timestamp('2011-03-12 04:00:00+0000', tz='UTC')
In [75]: stamp_utc.tz_convert('US/Eastern')
Out[75]: Timestamp('2011-03-11 23:00:00-0500', tz='US/Eastern')
#创建Timestamp时,还可以传入一个时区信息
In [76]: stamp_moscow=pd.Timestamp('2011-01-12 04:00',tz='Europe/Moscow')
In [77]: stamp_moscow
Out[77]: Timestamp('2011-01-12 04:00:00+0300', tz='Europe/Moscow')
时区意识型Timestamp对象在内部保存了一个UTC时间戳(自UNIX纪元(1970年1月1日0时)算起的纳秒数)。这个UTC值在时区转换过程中是不会发生变化的
In [76]: stamp_moscow=pd.Timestamp('2011-01-12 04:00',tz='Europe/Moscow')
In [77]: stamp_moscow
Out[77]: Timestamp('2011-01-12 04:00:00+0300', tz='Europe/Moscow')
In [78]: stamp_utc.value
Out[78]: 1299902400000000000
In [79]: stamp_utc.tz_convert('US/Eastern').value
Out[79]: 1299902400000000000
当使用pandas的DateOffset对象执行时间算术运算时,运算过程会自动关注是否存在夏令时转变期
#夏令时转变前30分钟--没有区别
In [80]: from pandas.tseries.offsets import Hour
In [81]: stamp=pd.Timestamp('2012-03-12 01:30',tz='US/Eastern')
In [82]: stamp+Hour()
Out[82]: Timestamp('2012-03-12 02:30:00-0400', tz='US/Eastern')
In [83]: stamp
Out[83]: Timestamp('2012-03-12 01:30:00-0400', tz='US/Eastern')
#夏令时转变前90分钟--少了一个小时,why?
In [84]: stamp=pd.Timestamp('2012-11-04 00:30',tz='US/Eastern')
In [85]: stamp
Out[85]: Timestamp('2012-11-04 00:30:00-0400', tz='US/Eastern')
In [86]: stamp+2*Hour()
Out[86]: Timestamp('2012-11-04 01:30:00-0500', tz='US/Eastern')
不同时区之间的运算
如果两个时间序列的时区不同,在将他们合并到一起时,最终结果就会是UTC,由于时间戳其实是以UTC存储的,所以并不需要发生任何转换
In [87]: rng=pd.date_range('3/7/2012 9:30',periods=10,freq='B')
In [88]: ts=pd.Series(np.random.randn(10),index=rng)
In [89]: ts
Out[89]:
2012-03-07 09:30:00 1.946924
2012-03-08 09:30:00 0.305003
2012-03-09 09:30:00 0.529779
2012-03-12 09:30:00 -1.501415
2012-03-13 09:30:00 -0.837557
2012-03-14 09:30:00 0.529487
2012-03-15 09:30:00 0.055145
2012-03-16 09:30:00 -0.746819
2012-03-19 09:30:00 -0.824349
2012-03-20 09:30:00 0.627202
Freq: B, dtype: float64
In [90]: ts1=ts[:7].tz_localize('Europe/London')
In [91]: ts2=ts[2:].tz_localize('Europe/Moscow')
In [92]: ts1
Out[92]:
2012-03-07 09:30:00+00:00 1.946924
2012-03-08 09:30:00+00:00 0.305003
2012-03-09 09:30:00+00:00 0.529779
2012-03-12 09:30:00+00:00 -1.501415
2012-03-13 09:30:00+00:00 -0.837557
2012-03-14 09:30:00+00:00 0.529487
2012-03-15 09:30:00+00:00 0.055145
Freq: B, dtype: float64
In [93]: ts2
Out[93]:
2012-03-09 09:30:00+04:00 0.529779
2012-03-12 09:30:00+04:00 -1.501415
2012-03-13 09:30:00+04:00 -0.837557
2012-03-14 09:30:00+04:00 0.529487
2012-03-15 09:30:00+04:00 0.055145
2012-03-16 09:30:00+04:00 -0.746819
2012-03-19 09:30:00+04:00 -0.824349
2012-03-20 09:30:00+04:00 0.627202
Freq: B, dtype: float64
In [94]: ts1+ts2#为什么是NaN值?????????
Out[94]:
2012-03-07 09:30:00+00:00 NaN
2012-03-08 09:30:00+00:00 NaN
2012-03-09 05:30:00+00:00 NaN
2012-03-09 09:30:00+00:00 NaN
2012-03-12 05:30:00+00:00 NaN
2012-03-12 09:30:00+00:00 NaN
2012-03-13 05:30:00+00:00 NaN
2012-03-13 09:30:00+00:00 NaN
2012-03-14 05:30:00+00:00 NaN
2012-03-14 09:30:00+00:00 NaN
2012-03-15 05:30:00+00:00 NaN
2012-03-15 09:30:00+00:00 NaN
2012-03-16 05:30:00+00:00 NaN
2012-03-19 05:30:00+00:00 NaN
2012-03-20 05:30:00+00:00 NaN
dtype: float64
三 matplotlib模块
matplotlib是一个用于创建出版质量图表的桌面绘图包(主要是2D方面),其目的是为python构建一个MATLAB式的绘图接口,它不仅支持各种操作系统上许多不同的GUI后端,而且还能将图片导出为各种常见的矢量(vector)和光栅(raster)图
:PDF JPG什么的
'''
安装matplotlib,需要使用apt-get安装依赖包(不是用pip3安装)
sudo apt-get install python3-tk
pip3 install matplotlib
'''
>>> import matplotlib
>>> import matplotlib.pyplot as plt
>>> fg=plt.figure()
>>> ax1=fg.add_subplot(2,2,1)
>>> ax2=fg.add_subplot(2,2,2)
>>> ax3=fg.add_subplot(2,2,3
... )
>>> plt.gcf()
<Figure size 640x480 with 3 Axes>