一、导读
接着上一节的Scrapy环境搭建,这次我们开始长征的第二步,如果第一步的还没走,请出门右转(Scrapy爬虫框架环境搭建)
二、步骤
scrapy startproject scrapyDemo
然后回车,就会自动生成一个项目骨架,如下图:
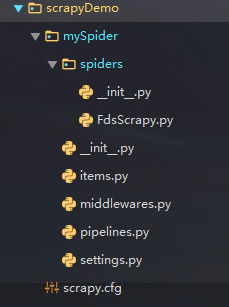
然后我们写爬虫的代码是在spiders里面写的。
import scrapy
from mySpider.items import MyspiderItem
class NextSpiderSpider(scrapy.Spider):
name = "nextSpider"
allowed_domains = ["lab.scrapyd.cn"]
start_urls = ['http://lab.scrapyd.cn/']
def parse(self, response):
content = response.css('div.quote') # 提取首页所有名言,保存至变量content
for v in content: # 循环获取每一条名言里面的:名言内容、作者、标签
text = v.css('.text::text').extract_first() # 提取名言
author = v.css('.author::text').extract_first() # 提取作者
tags = v.css('.tags .tag::text').extract() # 提取标签
tags = ','.join(tags) # 数组转换为字符串
"""
接下来进行写文件操作,每个名人的名言储存在一个txt文档里面
"""
file_name = '%s-语录.txt' % author # 定义文件名,如:木心-语录.txt
item = MyspiderItem()
item['text'] = text
item['author'] = author
item['tags'] = tags
# 将爬取的数据写成txt文件
with open(file_name, "a+") as f: # 不同人的名言保存在不同的txt文档,“a+”以追加的形式
f.write(text)
f.write('\n') # ‘\n’ 表示换行
f.write('标签:' + tags)
f.write('\n-------\n')
f.close()
# scrapy crawl nextSpider -o items.json -s FEED_EXPORT_ENCODING=UTF-8 将数据导出来序列化变成json格式
yield item
# 接下来我们需要判断下一页是否存在,如果存在
# 我们需要继续提交给parse执行关键看 scrapy 如何实现链接提交
next_page = response.css('li.next a::attr(href)').extract_first() # css选择器提取下一页链接
if next_page is not None: # 判断是否存在下一页
"""
如果是相对路径,如:/page/1
urljoin能替我们转换为绝对路径,也就是加上我们的域名
最终next_page为:http://lab.scrapyd.cn/page/2/
"""
next_page = response.urljoin(next_page)
"""
接下来就是爬取下一页或是内容页的秘诀所在:
scrapy给我们提供了这么一个方法:scrapy.Request()
这个方法还有许多参数,后面我们慢慢说,这里我们只使用了两个参数
一个是:我们继续爬取的链接(next_page),这里是下一页链接,当然也可以是内容页
另一个是:我们要把链接提交给哪一个函数(callback=self.parse)爬取,这里是parse函数,也就是本函数
当然,我们也可以在下面另写一个函数,比如:内容页,专门处理内容页的数据
经过这么一个函数,下一页链接又提交给了parse,那就可以不断的爬取了,直到不存在下一页
"""
yield scrapy.Request(next_page, callback=self.parse)