本项目的完整代码放在最后
目录

1.环境的安装
激活自己的虚拟环境 :activate 虚拟环境名
然后安装scrapy环境
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy2.在cmd中创建一个scrapy项目
scrapy startproject 项目名项目名是自己设定的,最好设成某个单词
比如我在电脑F盘某个文件夹下面,左上角输入cmd回车,就可以快速进入该路径下

1、输入activate pytorch(pytorch是我虚拟环境名称)
2、输入scrapy startproject CDSN (CSND是爬虫项目名,根据自己情况写名称)

3、然后我们可以看见在该路径下多了一个CSND文件夹,我们用pycharm打开它
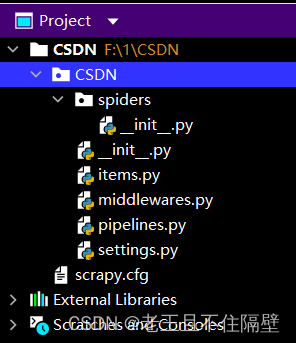
可以看到CSND文件夹下的文件结构
spiders包:存储爬虫代码的目录,稍后会在此包下创建爬虫主文件
items.py: 项目的目标文件
middlewares.py :项目的输入输出处理文件
pipelines.py : 项目的管道文件
settings.py: 项目的设置文件
3.cmd中创建spider包下的爬虫主文件
注意要cd到spiders文件下哦,输入如下:
scrapy genspider test https://www.csdn.net表示创建一个为test (这个名字根据自己喜好设定) 的爬虫文件,并限制在https://www.csdn.net域下爬取,最后接的网站域名可写可不写。(注意要cd到spiders文件下哦)


即可看到spiders文件夹下多了test.py文件。
4.对scrapy文件的具体编写
4.1用xpath对爬取的内容进行一个定位
比如我想爬取CSDN首页文章的标题,我们来到csdn的相关页面。

选中其中一个标题,鼠标右键选择“”检查“”

可以由下图可以看见网页源码中标题的大概位置,我们需要将每个标题给他定位出来,
这里推荐一个Google Chrome浏览器的一个插件XPath Helper,用xpath对我们需要爬取的内容进行一个定位与验证,请自行百度安装一下。

接下来手写xpath,(虽然xpath插件可以快速定位,但我还是推荐手写,能加深对xpath的理解) 对爬取内容进行定位,我们可以将手写的定位代码在xpath插件中验证,本文就不在此细讲如何手写定位,这个建议找一下xpath的相关视频学习一下。

可以看到我们能定位到首页的标题了。
4.2编写spiders下的test.py爬虫主文件
# -*- coding: utf-8 -*-
import scrapy
from CSDN.items import CsdnItem
class TestSpider(scrapy.Spider):
name = 'test'
# allowed_domains = ['www.csdn.net']
start_urls = ['http://www.csdn.net/']
def parse(self, response):
node_list = response.xpath("//span[@class='blog-text']")
for node in node_list:
item = CsdnItem()
title = node.xpath("./text()").extract()
item['title'] = title[0]
yield item4.3编写items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class CsdnItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()#标题4.4编写settings.py
该文件只要修改部分:
1、首先,由于是学习用,可以不遵守robots.txt协议,因此找到ROBOTSTXT_OBEY
进行修改。(大约在第20行)
ROBOTSTXT_OBEY = False2、插入虚假浏览器 (将下方代码插入在空白行,比如上面ROBOTSTXT_OBEY 这行下面)
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'#把自己伪装成浏览器3、把65--67行左右的ITEM_PIPELINES 注释去掉,如下的三行
ITEM_PIPELINES = {
'CSDN.pipelines.CsdnPipeline': 300,
}4.5编写pipelines.py保存爬取内容文件
# -*- coding: utf-8 -*-
# useful for handling different item types with a single interface
import json
class CsdnPipeline:
def __init__(self):
self.f = open("csnd.json", "w", encoding='utf-8') # “w”
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.f.write(content)
return item
# 关闭文件
def close_spider(self, spider):
self.f.close()其他没改动的文件采用默认即可。
5.cmd中运行爬虫
在项目的根目录下运行:
scrapy crawl test也可以在pycharm中编写run.py,这样不用去cmd中运行代码:内容如下
# -*- coding: utf-8 -*-
from scrapy import cmdline
cmdline.execute('scrapy crawl test'.split())记得将test名称更改为你设置名称。
run.py位置如下:
运行后得到如下:

在项目文件的目录下多出一个csdn.json文件

打开:

本文是最基础的爬虫教学,可能有的地方细节没说出来,还请各位见谅。最近感觉空余时间很少,有的伙伴的问题回答的不及时,也请多多包涵!
代码地址:
链接:https://pan.baidu.com/s/1KgVpMFx8JGo5dOD0X6s6Zw?pwd=5555&_at_=1656090501842
提取码:5555