引言
最近在学习机器学习的一些经典算法,在学习到分类算法时想着写一些博客备忘。于是就有了这篇博文。
分类与聚类
在讲具体的分类算法之前,讲一下什么是分类,什么是聚类。
分类通俗的意思就是将某个样本归属到哪一类别下。聚类的意思就是将相似的样本划为一类。
根据从决策树学习谈到贝叶斯分类算法、EM、HMM的描述
- Classification (分类),对于一个 classifier ,通常需要你告诉它“这个东西被分为某某类”这样一些例子,理想情况下,一个 classifier 会从它得到的训练集中进行“学习”,从而具备对未知数据进行分类的能力,这种提供训练数据的过程通常叫做 supervised learning (监督学习),
- 而Clustering(聚类),简单地说就是把相似的东西分到一组,聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起,因此,一个聚类算法通常只需要知道如何计算相似 度就可以开始工作了,因此 clustering 通常并不需要使用训练数据进行学习,这在 Machine Learning 中被称作 unsupervised learning (无监督学习).
1.1 决策树理解
第一个例子
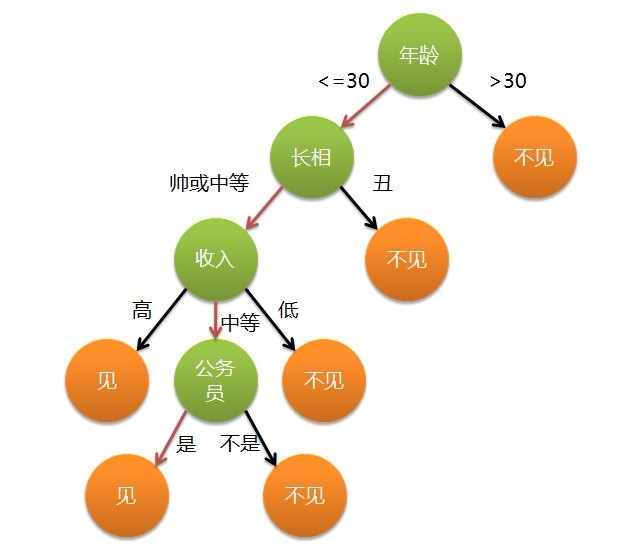
现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
该女孩的决策就是决策树的思想,从年龄,外貌,收入,是否公务员特征来决定是否见面。她的逻辑图可以这样表示:
第二个例子
假设有这么一家餐馆,餐馆经理想知道以下几个因素对顾客是否会到此就餐的影响:目前就餐人数、顾客饿不饿、菜式、今天是否周末。那么,很有可能经理对几百个人进行调查,发现这样一些规律:假如餐馆是空的,没有人正在就餐,顾客感觉不对劲就不会选择到此就餐,如果有一些人在就餐,顾客感觉还行吧就会选择在此就餐,而如果餐馆坐满了,那么顾客就要想一想了,假如自己不饿的话,那还是不在这里就餐了,否则,就要看你餐馆有什么菜色了……
据此,可能存在如下的决策树,它的每个非叶子节点表示一个属性,叶子节点表示顾客是否会到此就餐。有了这棵决策树,对于一个新来的顾客,我们只要从根结点从上往下遍历到叶子节点便能决定这个顾客是否会选择在这里就餐。

所以决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。
我们回到第一个例子。见与不见究竟先看哪一个属性呢,是年龄优先,还是外貌优先?在算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念,熵来衡量哪个属性优先被考虑。熵减越大,对应属性先考虑。下文将详细说明。
1.2 ID3算法简介
ID3算法是由Quinlan首先提出的,该算法是以信息论为基础,以信息熵和信息增益为衡量标准,从而实现对数据的归纳分类。在ID3算法中,选择信息增益最大的属性作为当前的特征对数据集分类。
先解释一下信息熵和信息增益:
信息熵:在信息论中,熵被用来衡量一个随机变量出现的期望值。变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大,熵是整个系统的平均消息量。 信息熵是信息论中用于度量信息量的一个概念。一个系统越是有序,信息熵就越低;反之,一个系统越是混乱,信息熵就越高。所以,信息熵也可以说是系统有序化程度的一个度量。
信息熵的计算公式如下:
其中的 代表有 个分类类别(比如假设是 类问题,那么 )。分别计算这 类样本在总样本中出现的概率 和 ,这样就可以计算出未选中属性分枝前的信息熵。
信息增益:在信息增益中,衡量标准是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。对一个特征而言,系统有它和没它时信息量将发生变化,而前后信息量的差值就是这个特征给系统带来的信息量。这里的信息量就是指的熵。简单地说,信息增益就是熵变化的值
ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。该算法采用自顶向下的贪婪搜索遍历可能的决策树空间。
根据维基百科描述
ID3的思想总结:
- 自顶向下的贪婪搜索遍历可能的决策树空间构造决策树(此方法是ID3算法和C4.5算法的基础);
- 从“哪一个属性将在树的根节点被测试”开始;
- 使用统计测试来确定每一个实例属性单独分类训练样例的能力,分类能力最好的属性作为树的根结点测试(如何定义或者评判一个属性是分类能力最好的呢?这便是信息增益,or信息增益率)。
- 然后为根结点属性的每个可能值产生一个分支,并把训练样例排列到适当的分支(也就是说,样例的该属性值对应的分支)之下。
- 重复这个过程,用每个分支结点关联的训练样例来选取在该点被测试的最佳属性。
ID3算法摘要:

1.3 ID3算法实现
我们再来看看ID3在python下的实现
假设有下表这样的数据集
| 不浮出水面是否可以生存 | 是否有脚蹼 | 属于鱼类 |
|---|---|---|
| 是 | 是 | 是 |
| 是 | 是 | 是 |
| 是 | 否 | 否 |
| 否 | 是 | 否 |
| 否 | 是 | 否 |
基于这样的数据构建决策树,当一个新来的样本比如:不浮出水面是否可以生存:是,是否有脚蹼:是 ,判断该生物是否为鱼类
1、我们用python 代码创建数据集
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
#change to discrete values
return dataSet, labels代码中用1代表‘是’,0代表‘否’,labels是标签数组,yes ,no是类别
2、计算给定数据集熵(香农熵)
from math import log
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet: #the the number of unique elements and their occurance
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2) #log base 2
return shannonEnt这里创建一个数据字典,它的键值是最后一列(类别标签列)的数值。如果当前键值不存在则扩展字典并将当前键值加入字典,每个键值都记录了当前类别出现的次数,最后使用所有类别标签的发生频率计算类别出现的概率。我们将使用这个概率计算香农熵。
3、划分数据集
分类算法除了需要测量信息熵,还要划分数据集,度量划分数据集的熵,以便判断当前是否正确划分了数据集。
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #chop out axis used for splitting
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet以上的代码有3个输入参数:待划分的数据集,划分数据集的特征(标签),需要返回的特征的值。
接下来我们将遍历整个数据集,循环计算熵和划分数据集,找到最好的特征划分方式。
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #the last column is used for the labels
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures): #iterate over all the features
featList = [example[i] for example in dataSet]#create a list of all the examples of this feature
uniqueVals = set(featList) #get a set of unique values
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy #calculate the info gain; ie reduction in entropy
if (infoGain > bestInfoGain): #compare this to the best gain so far
bestInfoGain = infoGain #if better than current best, set to best
bestFeature = i
return bestFeature #returns an integer
遍历当前特征中所有唯一的属性值,对每一个属性值划分一次数据集,然后计算数据集新熵值,对所有唯一特征值得到的熵求和
4、递归建立决策树
在建立决策树之前考虑一个问题:如果数据集处理了所有的属性,但是类标签依然不唯一,此时我们需要如何定义叶子节点。
在这种情况下,我们通常会采用投票的方式定义该叶子节点
import operator
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]接下来我们创建决策树
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]#stop splitting when all of the classes are equal
if len(dataSet[0]) == 1: #stop splitting when there are no more features in dataSet
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:] #copy all of labels, so trees don't mess up existing labels
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
这里使用了两个输入参数:数据集,标签列表。递归函数的第一个停止条件是所有的标签完全相同,则直接返回该标签。递归停止的第二个条件是使用完了所有的特征,仍然不能将数据集划分成唯一的类别分组,无法返回唯一的类标签,这里使用majorityCnt函数做投票选出类别多的作为返回值。
完整的运行一下
dataset,labels=createDataSet()
print(calcShannonEnt(dataset))
print(splitDataSet(dataset,0,0))
print(chooseBestFeatureToSplit(dataset))
print(createTree(dataset,labels))输出:
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
0.9709505944546686
[[1, 'no'], [1, 'no']]
0
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}这是ID3的简单实现,后续还有其他算法,有不足之处请多指教!