该小节讲解一下归一化以及标准化对比。
归一化
我们先看看归一化的计算。下面是他的公式(没必要琢磨,往下看,学习讲究效率):

那么针对这个公式怎么把结果计算出来?我们先看看归一化的结果,使用API:
模块导入:
(预处理) (最小最大的缩放)
sklearn归一化API: sklearn.preprocessing.MinMaxScaler
用法:
MinMaxScalar(feature_range=(0,1)…)
每个特征缩放到给定范围(默认[0,1])
MinMaxScalar.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
知道用法之后,我们实现一个如下的归一化(其是作用于没一列):
1、实例化MinMaxScalar
2、通过fit_transform转换
数据
[[90,2,10,40],
[60,4,15,45],
[75,3,13,46]]
注意,这里的数据和我们特征抽取的数据是不一样的,在对数据预处理的时候,在这里使用的是二位数组,编写程序如下:
from sklearn.preprocessing import MinMaxScaler
def mm():
"""
归一化处理
:return:
"""
#默认为0-1
mm = MinMaxScaler()
data = mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]])
print(data)
return None
if __name__ == '__main__':
mm()
执行之后,得到如下打印信息:
[[1. 0. 0. 0. ]
[0. 1. 1. 0.83333333]
[0.5 0.5 0.6 1. ]]
上面是默认的缩放范围,如果我们把缩放范围改为1-3:
- mm = MinMaxScaler()
+ mm = MinMaxScaler(feature_range=(2,3))
重新运行,得到如下打印信息:
[[3. 2. 2. 2. ]
[2. 3. 3. 2.83333333]
[2.5 2.5 2.6 3. ]]
其下是具体计算过程:

那么上面这些处理有什么用?在什么时候我们才会用到所谓的归一化?下面是一个案例:

上面的数据都是男士的数据,
三个特征:玩游戏所消耗时间的百分比、每年获得的飞行常客里程数、每周消费的冰淇淋公升数。
所属类别:被女士评价的三个类别,不喜欢didnt、魅力一般small、极具魅力large。
也许也就是说飞行里程数对于结算结果或者说相亲结果影响较大,但是统计的人觉得这三个特征同等重要。
那么对着3个特征同等重要的时候,我们就要进行归一化:

假设我们以蓝色的两个样本为例子,用下面的公式去评断:
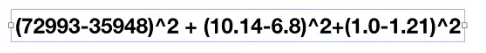
我们可以看到,其玩游戏所消耗时间的百分比,每周消费的冰淇淋公升数两个特征,对评判基本没有影响了,所以为了让他们3个特征同等重要,我们要进行归一化,转化到同一标准下面。
其目的:是为了使得某一特征不会对结果造成更大影响,减少在机器分析过程中的干扰。
以上就是归一化,后面我们会讲解他的应用。
接下来我们有几个问题:如果数据中异常点较多,会造成什么影响。
我们需要从他的公式中去考虑;

可以看到,如果最大值与最小值异常,影响是非常大的,所以归一化的缺点是,对异常点的处理不是十分的好。
在特定场景下最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性(稳定性)较差,只适合传统精确小数据场景。
但是传统精确小数据场景几乎很少存在,那么我们怎么办呢?我们会想到另外一种方法:标准化,这也是使用最广泛的方法,
标准化
下面是标准化的公式:

其和归一化一样,是也作用于一列,即一列特征。我们还是哪刚才的数据:

首先,从上面我们可以看到,方差的开平方就是标准差,所以要了解一个种药品的东西,即方差的概念:列的每个数据减去该列的平均值,然后求平方,加上所有的和,最后除以平均数,那么得到的就是方差,如果再开平方,就是标准差。
根据公司我们可以知道,当方差为0的时候,其最为稳定。即所有的点都重合了。
那么我们现在结合归一化来谈谈标准化:

既然标准化不容易受到异常数据的影响,那么大部分普遍的数据都可以用他来进行处理,把数据进行缩放。
下面我们介绍标准化的API用法
模块导入:
sklearn特征化API: scikit-learn.preprocessing.StandardScaler
用法:
StandardScaler(…)
处理之后每列来说所有数据都聚集在均值0附近标准差为1
StandardScaler.fit_transform(X,y)
X:numpy array格式的数据[n_samples,n_features]
返回值:转换后的形状相同的array
StandardScaler.mean_
原始数据中每列特征的平均值
StandardScaler.std_
原始数据每列特征的方差
我们使用如下数据:
[[ 1., -1., 3.],
[ 2., 4., 2.],
[ 4., 6., -1.]]
编写一下程序:
def stand():
"""
标准化缩放
:return:
"""
std = StandardScaler()
data = std.fit_transform([[ 1., -1., 3.],[ 2., 4., 2.],[ 4., 6., -1.]])
print(data)
return None
from sklearn.preprocessing import MinMaxScaler,StandardScaler
if __name__ == '__main__':
stand()
运行程序之后,打印信息如下:
[[-1.06904497 -1.35873244 0.98058068]
[-0.26726124 0.33968311 0.39223227]
[ 1.33630621 1.01904933 -1.37281295]]
我们把第一列的和加起来求平均值可以得到0,当标出差为一的时候,说明这个数据最适中。所以我们前面提到:特点:通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内。上面得到的数据就是我们机器学习需要的数据
标准化总结:在已有 ,适合现代嘈杂大数据场景。