什么是机器学习? 机器学习是从数据中自动分析获得规律(模型),并利用规律对未知数据进行预测
应用 AlphoGo:分析的数据,获得经验规律 推荐系统:个性化新闻推荐,广告推荐
机器学习
机器学习能解决哪些问题?
解放生产力 智能客服: 24小时作业
解决专业问题 阿里ET医疗大脑:吸收外部的精良算法和医学经验,医生的助手,应用领域:患者虚拟助理、医学影像、药效挖掘、新药研发、健康管理
提供社会便利 阿里ET城市大脑:对整个城市进行全局实时分析,自动调配公共资源,红绿灯设置、路线推荐、交通事故判定
机器学习
机器学习的应用场景: 自然语言处理 无人驾驶 计算机视觉 推荐系统
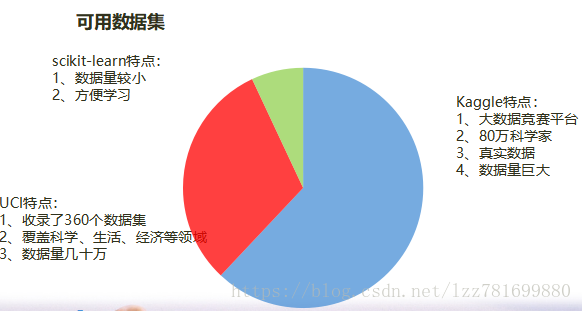
机器学习 数据来源
企业积累 淘宝、ofo、微信、美团
政府数据 经济统计数据
科研机构实验数据 市场调研分析
数据分类 离散型数据 记录不同类别个体的数目的数据,又称计数数据,类型是整数,不能再细分,也不能进一步提高它们的精确度。
连续型数据 变量可以在某个范围内取任一数,即变量的取值可以是连续的,如,长度、时间、质量值等,这类整数通常是非整数,含有小数部分。
数据分类:
离散型数据 记录不同类别个体的数目的数据,又称计数数据,类型是整数,不能再细分,也不能进一步提高它们的精确度。
连续型数据 变量可以在某个范围内取任一数,即变量的取值可以是连续的,如,长度、时间、质量值等,这类整数通常是非整数,含有小数部分。
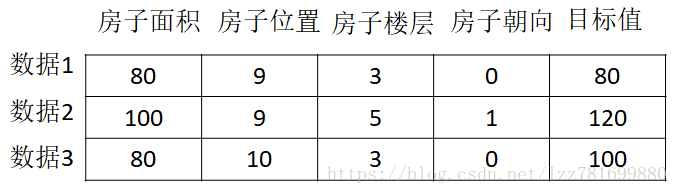
常用数据集的结构组成 结构:特征值+目标值
特征值:要收集的数据,如房子面积 位置 楼层 朝向等
目标值:具体要完成的任务,可以没有目标值 一行是一个样本,一列称为一个特征
sklearn数据集与估计器
数据集划分 机器学习一般的数据集会划分为两个部分:
训练数据:用于训练,构建模型
测试数据:在模型检验时使用,用于评估模型是否有效
sklearn数据集与估计器
sklearn数据集 – API - 分割
sklearn.model_selection.train_test_split(*arrays, **options)
参数说明 X 数据集的特征值 y 数据集的标签值
test_size 测试集的大小,一般为float
random_state 随机数种子,不同的种子会造成不同的随机 采样结果。
相同的种子采样结果相同。
return 训练集特征值,测试集特征值,训练标签,测试标签(默认随机取)
特征工程
机器学习基础 -需明确的问题:
(1)算法是核心,数据和计算是基础
(2)找准定位 大部分复杂模型的算法设计都是算法工程师在做,而我们 分析很多的数据 分析具体的业务 应用常见的算法 特征工程、调参数、优化
机器学习基础 – 应该做的
1学会分析问题,使用机器学习算法想要完成何种任务
2掌握算法基本思想,学会用相应的算法解决对应的问题
3学会利用库或者框架解决问题
机器学习基础 – 开发流程
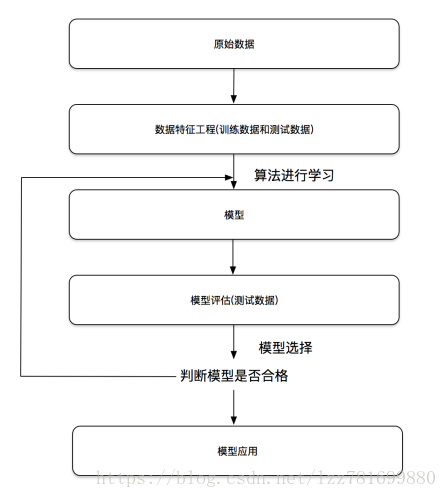
开发机器学习应用程序的步骤
(1)收集数据 我们可以使用很多方法收集样本数据,如:制作网络爬虫从网站上抽取数据、从RSS反馈或者API中得到信息、设备发送过来的实测数据。
(2)准备输入数据 得到数据之后,还必须确保数据格式符合要求。
(3)分析输入数据 主要是确保数据集中没有垃圾数据。如果是使用信任的数据来源,那么可以直接跳过这个步骤
(4)训练算法 机器学习算法从这一步才真正开始学习。如果使用无监督学习算法,由于不存在目标变量值,故而也不需要训练算法,所有与算法相关的内容在第(5)步
(5)测试算法 这一步将实际使用第(4)步机器学习得到的知识信息。当然在这也需要评估结果的准确率,然后根据需要重新训练你的算法
(6)使用算法 转化为应用程序,执行实际任务。以检验上述步骤是否可以在实际环境中正常工作。如果碰到新的数据问题,同样需要重复执行上述的步骤
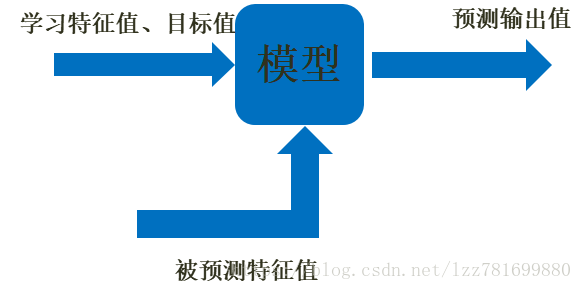
机器学习基础 –机器学习模型
定义:通过一种映射关系将输入值输入模型获得输出值
机器学习基础 –机器学习算法分类
监督学习
分类 k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
回归 线性回归、岭回归
标注 隐马尔可夫模型 (不做要求)
无监督学习 聚类 k-means
机器学习基础 –机器学习算法分类
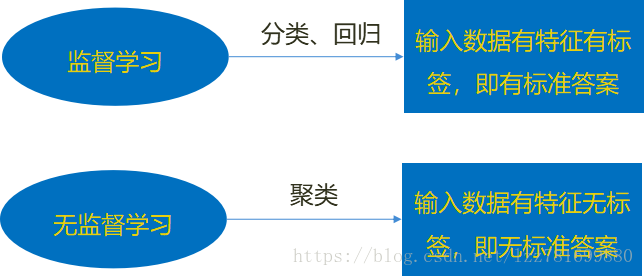
机器学习基础 –监督学习 监督学习(英语:Supervised learning),可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类)。
机器学习基础 –无监督学习 无监督学习(英语:Supervised learning),可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。输入数据是由输入特征值所组成。
机器学习基础 – 机器学习算法 – 分类
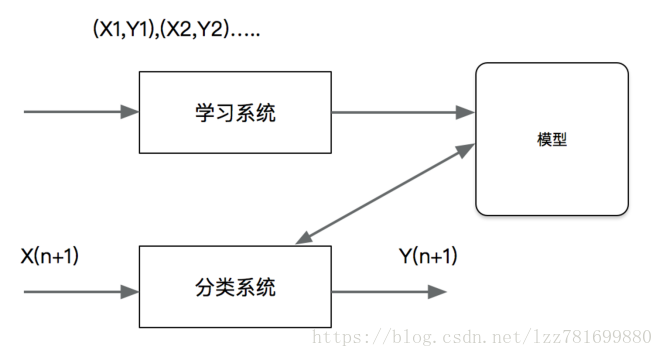
机器学习基础 – 机器学习算法 – 分类
分类是监督学习的一个核心问题,在监督学习中,当输出变量取有限个离散值时,预测问题变成为分类问题。最基础的便是二分类问题,即判断是非,从两个类别中选择一个作为预测结果
机器学习基础 – 机器学习算法 – 分类 – 应用
分类在于根据其特性将数据“分门别类”,所以在许多领域都有广泛的应用
在银行业务中,构建一个客户分类模型,按客户贷款风险的大小进行分类
图像处理中,分类可以用来检测图像中是否有人脸出现,动物类别等
机器学习基础 – 机器学习算法 – 分类 – 应用
手写识别中,分类可以用于识别手写的数字 文本分类,这里的文本可以是新闻报道、网页、电子邮件、学术论文
机器学习基础 – 机器学习算法 – 回归
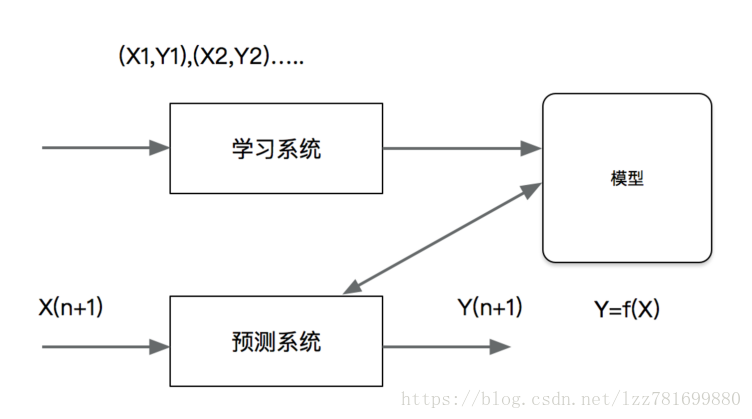
机器学习基础 – 机器学习算法 – 回归
回归是监督学习的另一个重要问题。回归用于预测输入变量和输出变量之间的关系,输出是连续型的值。
机器学习基础 – 机器学习算法 – 回归 – 应用
回归在多领域也有广泛的应用 房价预测,根据某地历史房价数据,进行一个预测 金融信息,每日股票走向
特征工程是什么?
特征工程本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。
特征工程的意义
直接影响模型的预测结果
scikit-learn库
Python语言的机器学习工具 Scikit-learn包括许多知名的机器学习算法的实现 Scikit-learn文档完善,容易上手,丰富的API,使其在学术界颇受欢迎。 目前稳定版本0.18
安装 1、创建一个基于Python3的虚拟环境 mkvirtualenv env2
2、在虚拟环境当中运行以下命令 pip install Scikit-learn
3、通过导入命令查看是否可以使用: import sklearn
数据的特征抽取
特征抽取就是对非连续变量比如分类、文字、图像等特征做数学化表述 sklearn.feature_extraction提供了特征提取的很多方法
字典特征抽取 对字典数据进行特征值化 类:sklearn.feature_extraction.DictVectorizer(sparse = True) sparse 是否将结果转换为scipy.sparse矩阵,默认开启 例如把将城市和环境作为字典数据进行特征抽取
字典特征抽取 DictVectorizer.get_feature_names() 返回类别名称 DictVectorizer.transform(X) 按照原先的标准转换
流程 实例化类DictVectorizer 调用fit_transform方法输入数据并转换,注意返回格式
文本特征抽取 文本的特征提取应用于很多方面,比如说文档分类、垃圾邮件分类和新闻分类。那么文本分类是通过词是否存在、以及词的概率(重要性)来表示。
(1)文档的中词的出现 数值为1表示词表中的这个词出现,为0表示未出现 类:sklearn.feature_extraction.text.CountVectorizer 将文本文档集合转换为计数矩阵(scipy.sparse matrices)
文本特征抽取 fit_transform(raw_documents,y) 注意:返回值利用toarray()方法转变为numpy的数组形式
文本特征抽取 TF-IDF表示词的重要性
TF:term frequency 词频 统计一篇文章中某个词在文档中出现的次数

IDF:inverse document frequency 逆文档频率 是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到
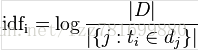
TF-IDF主要思想:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF作用:用以评估某一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。 分类机器学习算法的的重要依据
文本特征抽取 类:sklearn.feature_extraction.text.TfidfVectorizer(stop_words='english')
根据指定的公式将文档中的词转换为概率表示。
fit_transform(raw_documents,y)
学习词汇和idf,返回术语文档矩阵。
#stop_words停止词,不想要的词,筛选掉,不会出现在词频矩阵中
文本特征抽取 范例
from sklearn.feature_extraction.text import TfidfVectorizer
content = ["life is short,i like python","life is too long,i dislike python"]
vectorizer = TfidfVectorizer(stop_words='english')
print(vectorizer.fit_transform(content).toarray())
print(vectorizer.vocabulary_)
数据的特征处理 通过特定的统计方法(数据方法),将数据转换成算法要求的数据
数值型数据:归一化 标准化 确实值 类别型数据:one-hot编码
时间型数据:时间的切分 特征处理的API:sklearn.preprocessing
数据的特征处理 – 归一化
特点:通过对原始数据进行变换,把数据映射到默认值[0,1]之间
归一化在特征(维度)非常多的时候,把不同来源的数据统一到一个参考区间下,防止某一维或某几维对数据影响过大,这样比较起来才有意义 其次可以使程序运行更快。
最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
数据的特征处理 – 归一化
例如:一个人的身高和体重两个特征,假如体重50kg,身高175cm,由于两个单位不一样,数值大小不一样。如果比较两个人的体型差距时,那么身高对结果影响会比较大。
数据的特征处理 – 归一化
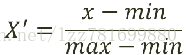
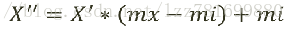
注:作用于每一列,max为一列的最大值,min为一列的最小值,那么X'' 为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0
数据的特征处理 – 归一化 - API MinMaxScaler(feature_range=(0,1)...) 每个特征值缩放到给定范围默认[0,1]
数据转换:MinMaxScaler.fit_transform(X) X:numpy array
格式的数据 [n_samples,n_features],特征值样本的数组
返回值:转换后的形状相同的array
数据的特征处理 – 归一化 – 范例
from sklearn.preprocessing import MinMaxScaler
def mms():
minmax = MinMaxScaler(feature_range=(2,4))
data = minmax.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]])
print(data)
数据的特征处理 – 归一化 – 案例:约会对象数据
相亲约会对象数据,这个样本是男士的数据,三个特征,玩游戏所消耗时间的 百分比、每年获得的飞行常客里程数、每周消费的冰淇淋公升数。然后有一个 所属类别,被女士评价的三个类别,不喜欢didnt、魅力一般small、极具魅力large 也许也就是说飞行里程数对于结算结果或者说相亲结果影响较大,但是统计的 人觉得这三个特征同等重要。