
机器学习](https://img-blog.csdnimg.cn/20190504185634424.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMwNTA1Njcz,size_16,color_FFFFFF,t_70)
机器学习是从数据中自动分析获得规律(模型),并利用规律对未知数据进行预测
数据处理:首先将所有数据放在一起,然后将其顺序打乱。由于顺序不是判断酒水的依据,我们并不期望顺序影响到模型学习到的内容。换言之,我们判断一种酒是红的还是啤的,并不需要知道前一种或是接下来有什么酒出现。
这时,可以着手绘出可视化的数据分析结果,这些分析图将有助于你发现不同变量之间的潜在相关性,并且能帮你发现是否有数据失衡。比如,假若我们的数据中大量结果都表现出啤酒的特征,那么模型大多数时候都遇到了啤酒,所以它的推测也将倾向于啤酒。但是真实世界中,模型需要判断的啤酒和红酒的量很有可能是相同的,假若它按照训练的结果得出的大部分都是啤酒,那么它有不少时候都得出了错误的结论。
我们还需要将数据分成两部分。第一部分用于训练模型,它们将占全部数据中的绝大多数。另一部分则是用于评估模型的判断能力的。显然我们不希望用于训练的数据被拿来检测模型,因为这些数据很可能被模型给直接记住了,答案脱口而出。这就好像你在考试里总不会出现平时的作业原题那样。
有时我们得到的数据需要一些其他形式的调整和操作,比如去重、规范化和纠错等等,这些都需要在数据准备的过程当中完成。 而我们的这个问答系统训练用的数据并不需要进一步操作,所以现在进入下一环节。
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的模型准确性 直接影响模型的预测结果
创建一个基于Python3的虚拟环境(可以在你自己已有的虚拟环境中):
mkvirtualenv –p /usr/bin/python3.5 ml3
在ubuntu的虚拟环境当中运行以下命令
pip3 install Scikit-learn
然后通过导入命令查看是否可以使用:
import sklearn
特征抽取针对非连续型数据
特征抽取对文本等进行特征值化
注:特征值化是为了计算机更好的去理解数据
作用:对字典数据进行特征值化
类:sklearn.feature_extraction.DictVectorizer
DictVectorizer.fit_transform(X)
X:字典或者包含字典的迭代器
返回值:返回sparse矩阵(稀疏矩阵)
DictVectorizer.inverse_transform(X)
X:array数组或者sparse矩阵
返回值:转换之前数据格式
DictVectorizer.get_feature_names()
返回类别名称
DictVectorizer.transform(X) 和fit方法
按照原先的标准转换
文本特征抽取
作用:对文本数据进行特征值化
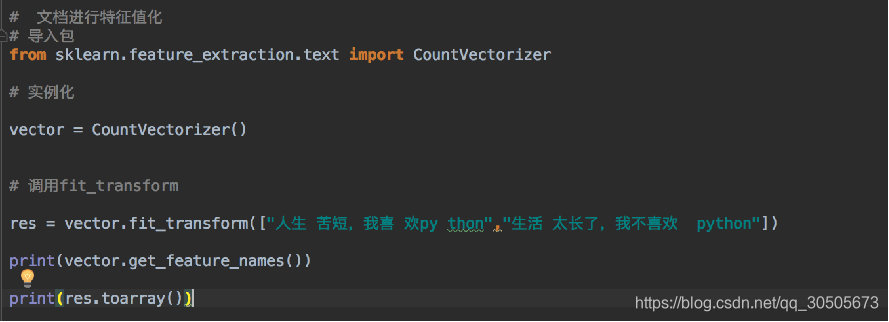
类:sklearn.feature_extraction.text.CountVectorizer
CountVectorizer(max_df=1.0,min_df=1,…)
返回词频矩阵
CountVectorizer.fit_transform(X,y)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵
CountVectorizer.inverse_transform(X)
X:array数组或者sparse矩阵
返回值:转换之前数据格式
CountVectorizer.get_feature_names()
返回值:单词列表
准备句子,利用jieba.cut进行分词
实例化CountVectorizer
将分词结果变成字符串当作fit_transform的输入值
TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
通过特定的统计方法(数学方法)将数据转换成算法要求的数据