-
Introduction
Here is some understanding of ArcLoss in <ArcFace: Additive Angular Margin Loss for Deep Face Recognition> ArcFace ’ main contribution is training a DCNN model with ArcFace Loss. In face recognition task, firstly train a DCNN with loss function. The common way for doing that is in using Softmax loss function, which declared below: -
Softmax
- formula (1):
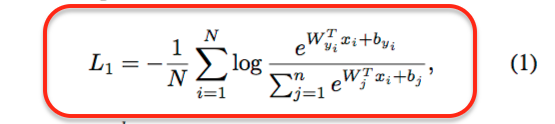
Our goal is to minimise L1, so the more L1 approaches to 0, the better the model is. We notice the formula, when L1 equals to 0, means log(X) equals to 0 so that X should more approach to 1. And only if e^(W_yi xi + b_yi)^ is maxed enough, the whole part of X will equal to 1.
So during the training procession, the weights W will convergence to a matrix to make xi multiply W_yi large enough.
- formula (1):
-
Variants of softmax
In face recognition, feature x1 and matrix W are normalized by l2 normalized, so (W_yi xi + bi) will simply describe as cosθ_yi, ( W_j^T multiply x_i ) = ∥Wj ∥ multiplies ∥xi∥ multiply cos θj, where θ_j is the angle between the weight W_j and the feature x_i. a new formula (2)- formula (2):

the new goal is to maximin cos(θ_yi), in the middle part of the picture below. If W_yi and x_i is close enough so that θ_yi == 0, that cos(θ_yi) will equals to 1 as it max value.
- formula (2):
-
ArcFace Loss
But for many face picture, it sames too easy to convert and gathered feature. In order to make the model learn a more gathered feature representation, ArcFace loss is proposed, which declared in below- formula (3).
 Comparing formula (2) and (3), and a new parameter named
Comparing formula (2) and (3), and a new parameter named mis added, formula (3) add an additive angular margin penaltymbetween xi and W_yi to simultaneously enhance the intra-class compactness and inter-class discrepancy. - But how could m do that?
let’s consider for loss L3, for a pair for weights and xi, if the angular between them θi is easy to convert to a small value, and cos(θi) will convert to 1, but for cos(θi + m), it will become hard, and weights and xi will need to learn more and be become closer to convert to a larger value for cos(θi + m), and weights(Last FC layer weights) and xi (DCNN weights is used to represent feature xi).
- formula (3).
-
conclusion
So compare formula(2), ArcFace Loss in formula(3) would improve the difficult for convert the angular between xi and the centre direction of each identity, which make the feature vector x_i closer to the centre direction of each identity. Just as the picture below.

ArcFace Loss `s main point is adding an angular margin penalty m in cos(θ+m) in order to in increase the difficulty for learning feature representation and gather features closer, which some part like HingleLoss in SVM for adding a threshold in order to separate features belongs to different classes and enhance the inter-class compactness.
Understanding of ArcLoss in 《ArcFace -Additive Angular Margin Loss for Deep Face Recognition》
猜你喜欢
转载自blog.csdn.net/sinat_21720047/article/details/88051591
今日推荐
周排行