版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/sunlanchang/article/details/88973096
观看斯坦福大学公开课CS230后记录笔记,以便以后查阅之用。
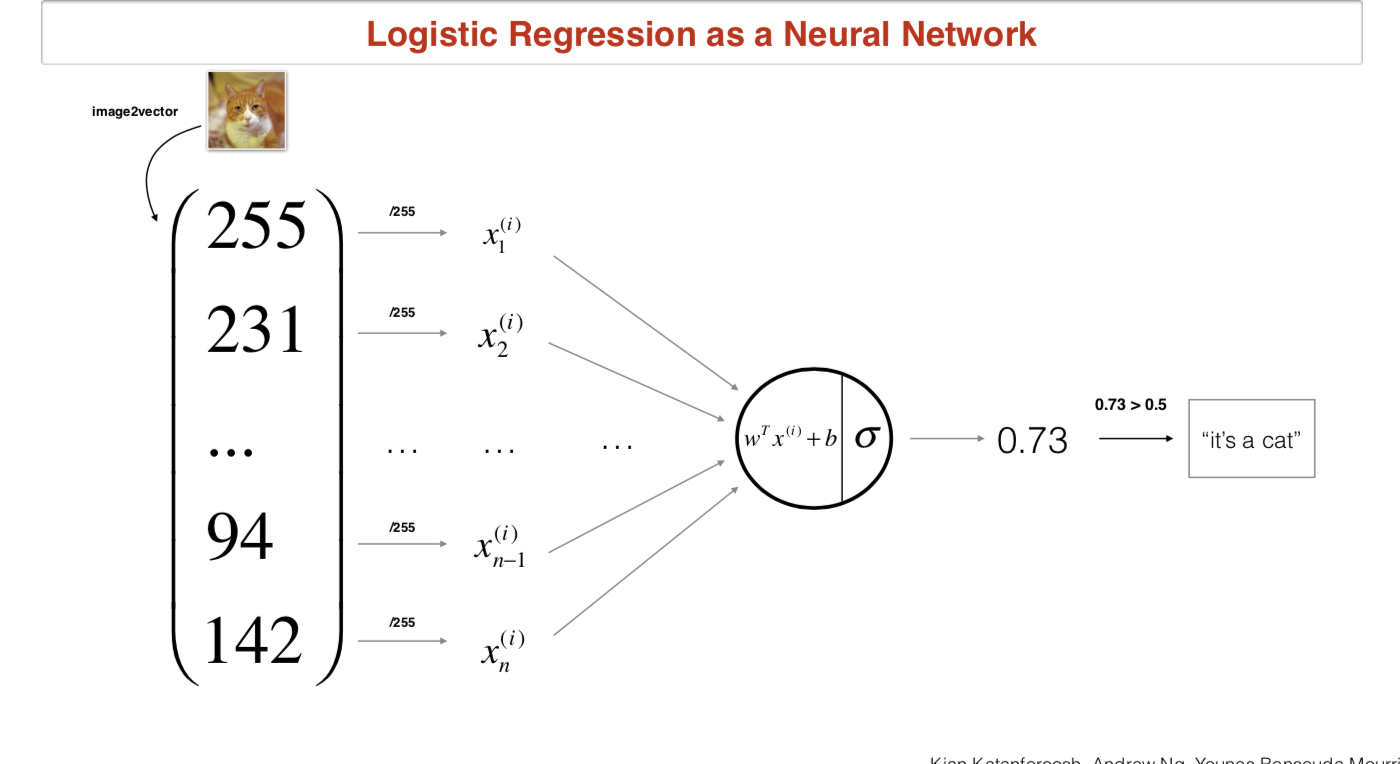
使用逻辑回归解决特定目标是否在图片中问题时,对于判断目标是否存在于图片中,对输出的编码可以采用sigmoid函数编码,设置一个阈值,当模型输出大于阈值时,判断存在,反之不存在图中。
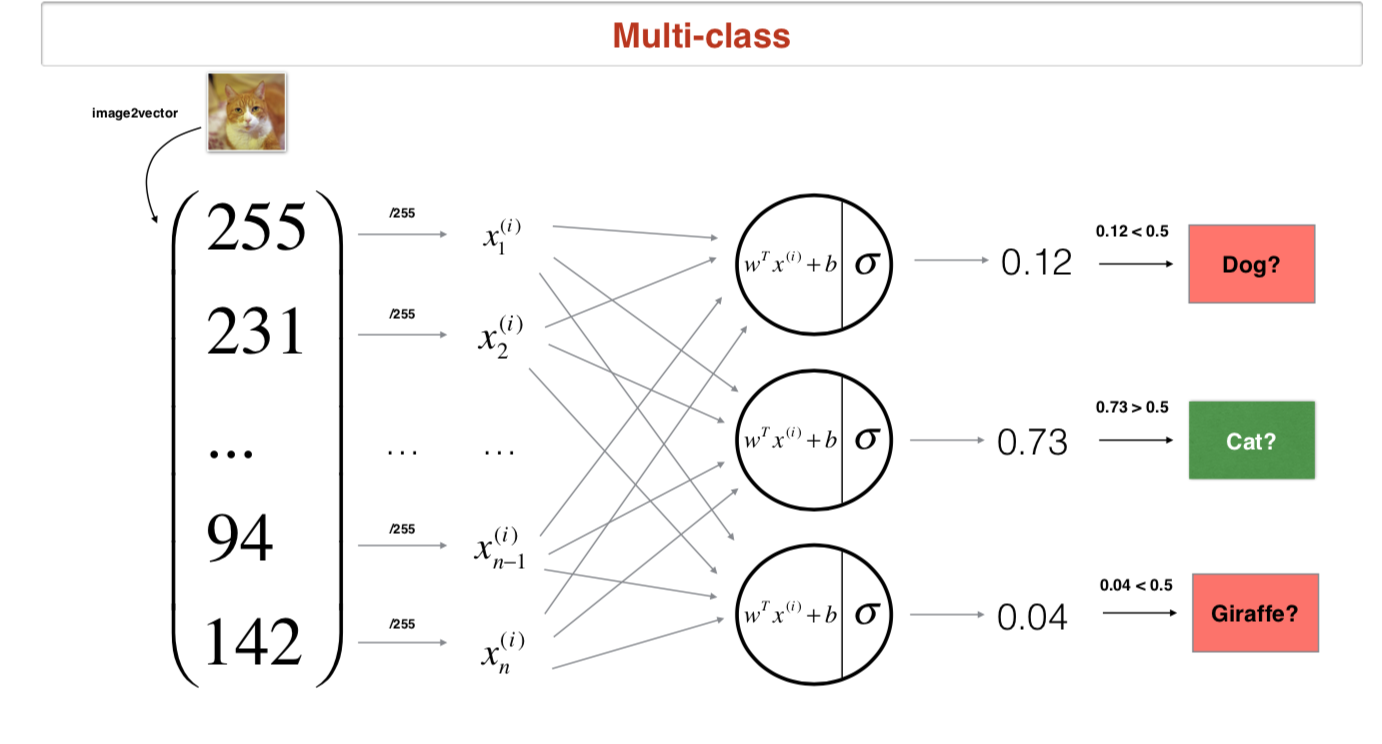
解决一个动物分类问题时,当图片中只有一个动物时,可以使用One-Hot编码,当图片中存在多个动物时,也可以采One-Hot编码,例如[1,1,0],表示图片中存在小狗和小猫。
Deep Learning解决一些问题

这里解决一个给定一个image判断image是白天还是黑夜的问题。
- 数据。估算一下模型的复杂度,这不是一个非常难的分类问题,按照以往的经验大概需要1万张image训练模型,8:2比例划分为训练数据和验证数据集。训练模型的好坏应该以人类的标准衡量模型的分类偏差,例如如果连我们自己都很难分辨一张图片的白天黑夜,那么模型分类错误也就情有可原了。
- 输入。输入模型的数据是像素级别的数据。分辨率应该保证分类准确率召回率的条件下,采用越低越好,这样有利于模型的robust。这个很好理解,因为model的input neurons是规定好的,如果遇到分辨率很高的图片可以下采样同样可以达到很好的accuracy和recall,但是如果给定一个分辨率很低的image,而model的input neurons很多,使用分辨率很低的图片上采样会降低model 的 accuracy和recall。
- 输出。白天和黑夜输出,采用1表示白天,0表示黑夜。最后一层的输出采用sigmoid函数。
- DNN架构。采用一个shallow的network就可以得到一个很好的结果。相反的如果采用一个比较deep的network会使得loss function有很多的local minimum从而导致训练难度增加,还会使得训练的数据量也得增加。
- Loss function。这里是一个分类问题,采用采用cross entropy可能会有比较好的结果。

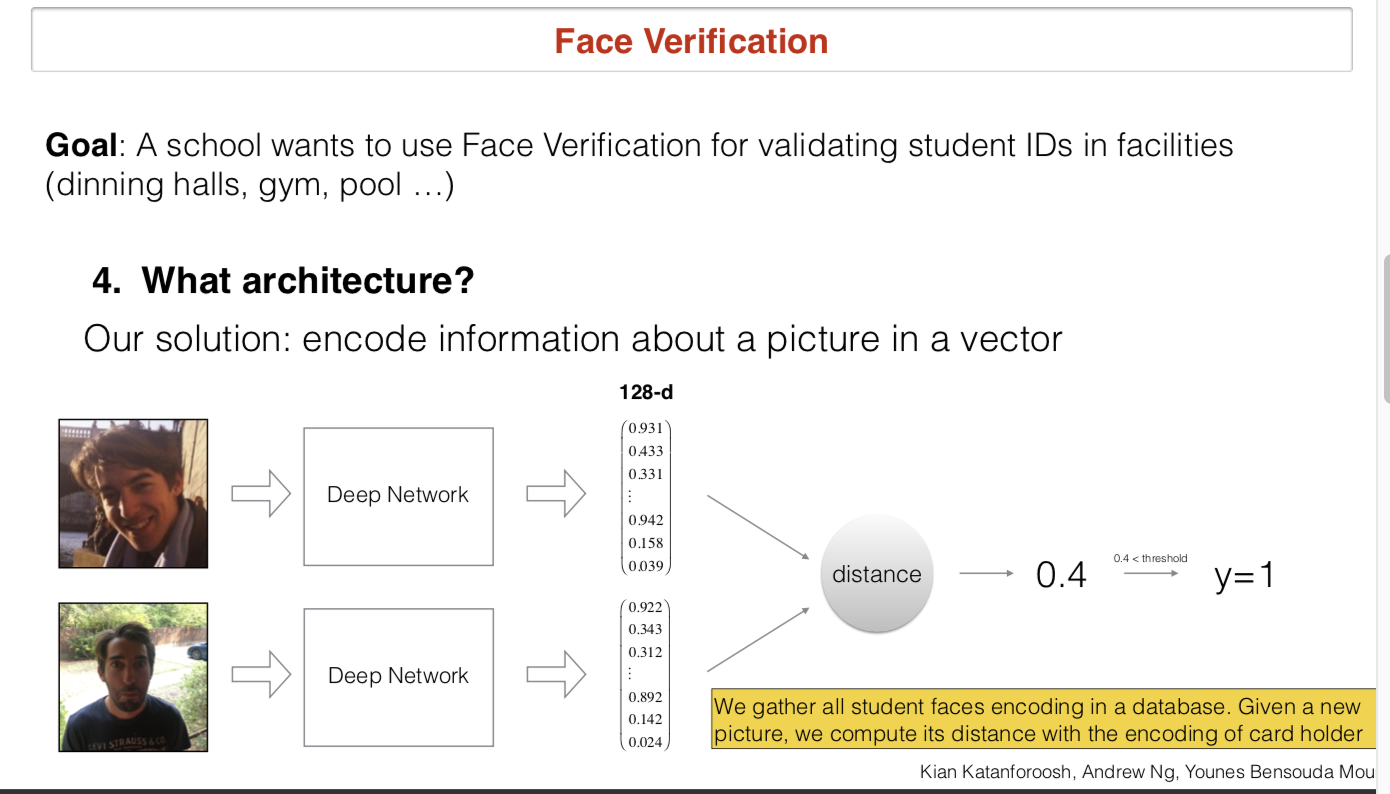
解决一个人脸验证的问题:给定你的现在的照片和你的学生卡,学校通过这套系统查看你学生ID在数据库的照片来确认你是否和数据库中的照片是一个人
- 使用传统算法遇到的问题。当使用传统算法计算两张照片之间的像素距离(欧式距离等),由于背景不同、穿着打扮不同的原因容易造成分类错误。
- 神经网络架构。使用一套在ImageNet等数据集训练好权重的network,去掉最后几层网络,使用当前学校数据库的照片训练model,输出一个向量例如最后一层的output neuron是128个,输出128维向量。进行比对的时候输入该ID的数据库照片model产生一个vector,输入该学生现在的照片输出一个vector,计算这两个vector之间的Distance即可。
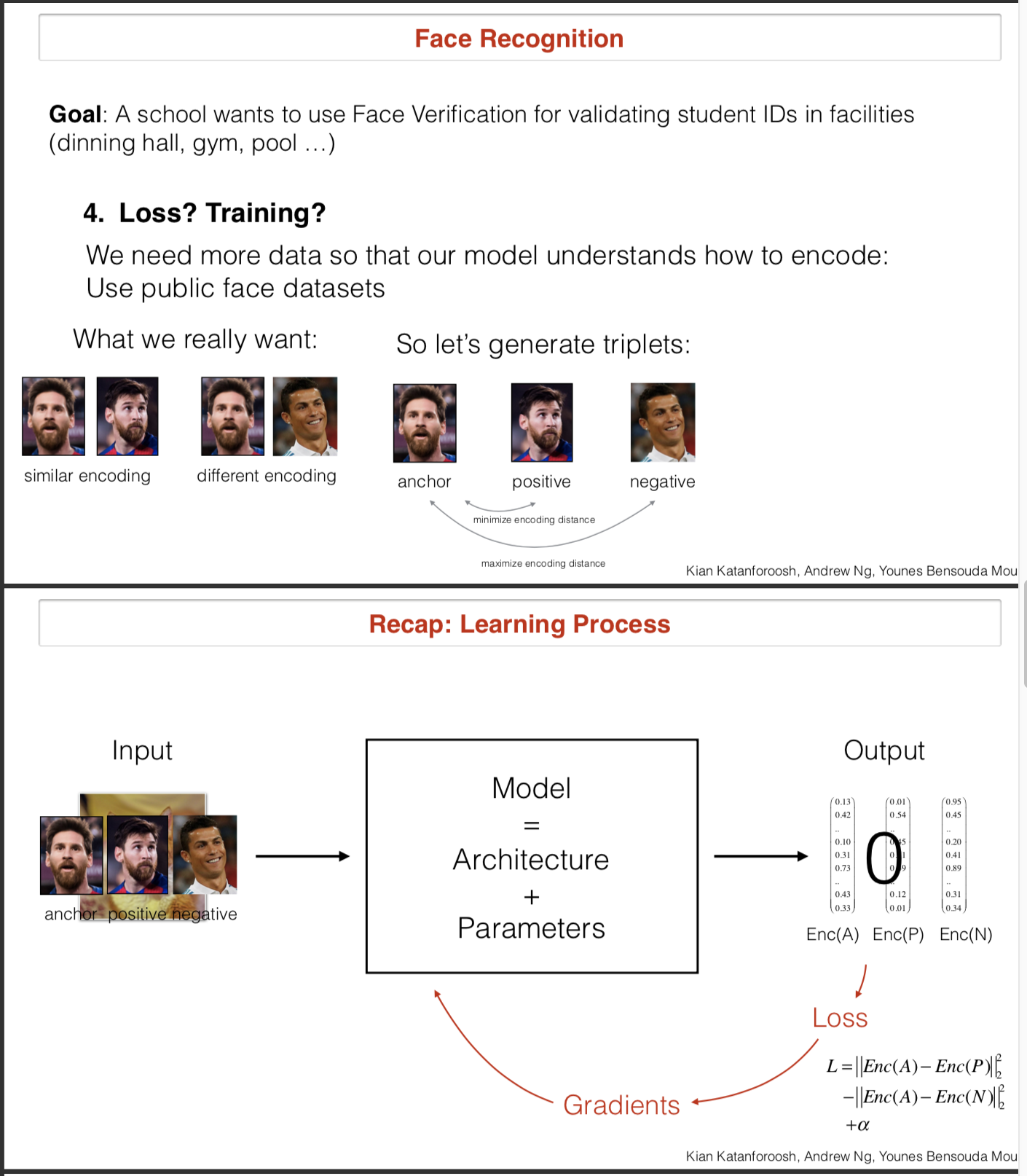
解决一个人脸识别问题,进学校门时由人脸识别系统识别你是本校的学生
- 模型架构。训练模型时首先构造一个三元组(Anchor,Positive, Negtive),Anchor代表门口照相机验证时给你拍摄的照片,Positive是你在数据库中真实的照片,Negtive是其他一个人照片,添加Negtive原因是想让模型学习到同一个人和不同人之间的区别。输入模型三元组,模型输出三个向量Enc(A),Enc§,Enc(N),代表三个照片经过模型处理后的encoding。
- Loss function。 ,这样设计的原因是希望当前image A和真实image P距离越小则loss越小,当前image A和他人image N距离越大则loss越小。

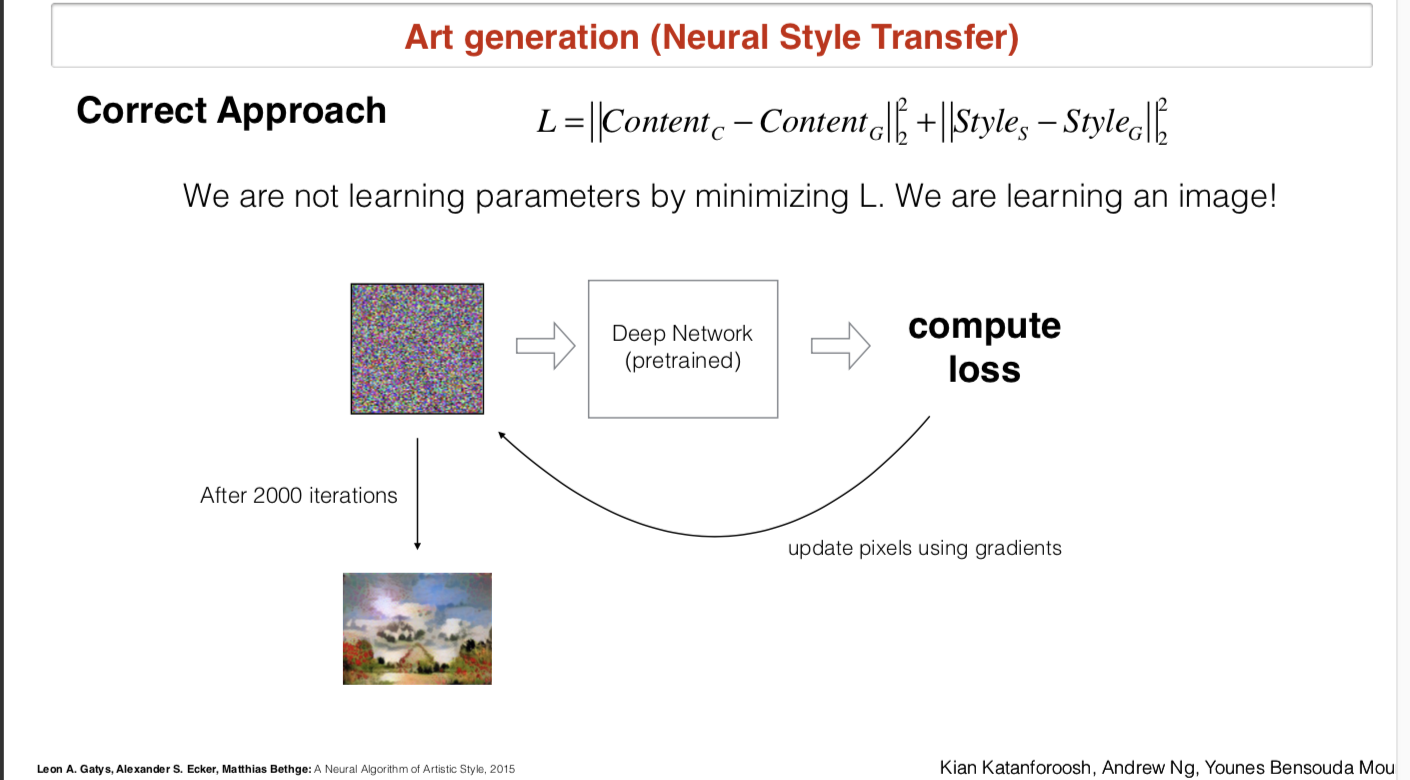
风格转移:给定一件艺术品照片,一个普通照片生成这个普通照片的艺术品风格照片
- 架构。这里的关键是采用一个预训练的网络,将网络中的参数固定不动,输入模型的照片采用一个随机噪声的图片。损失函数设计成与输入有关的函数,BP算法进行更新的时候,更新输入的噪声图片,进行多轮训练更新后,会将输入的噪声图片更新成为风格转移的照片。
- Loss function。 ,其中的Content_C是普通照片的内容,Content_G是需要生成的风格照片的内容,Style_C是普通照片的风格,Style_G是需要生成的照片的风格。这样设计能够使生成照片内容和当前普通照片内容距离近时loss小,生成照片风格和艺术照片风格距离小时loss小。
YOLO V1损失函数

- 第一行是bounding box的中心坐标(x,y)损失
- 第二行是bounding box的高和宽
- 第三行是若bounding box中有object并且ground true也有object则loss会小。
- 第四行是若bounding box中无object并且ground true也无object则loss会小。
- 对object的分类的loss
注意第二行使用开根号的w和h是因为想增大对于小物体损失的loss error。