


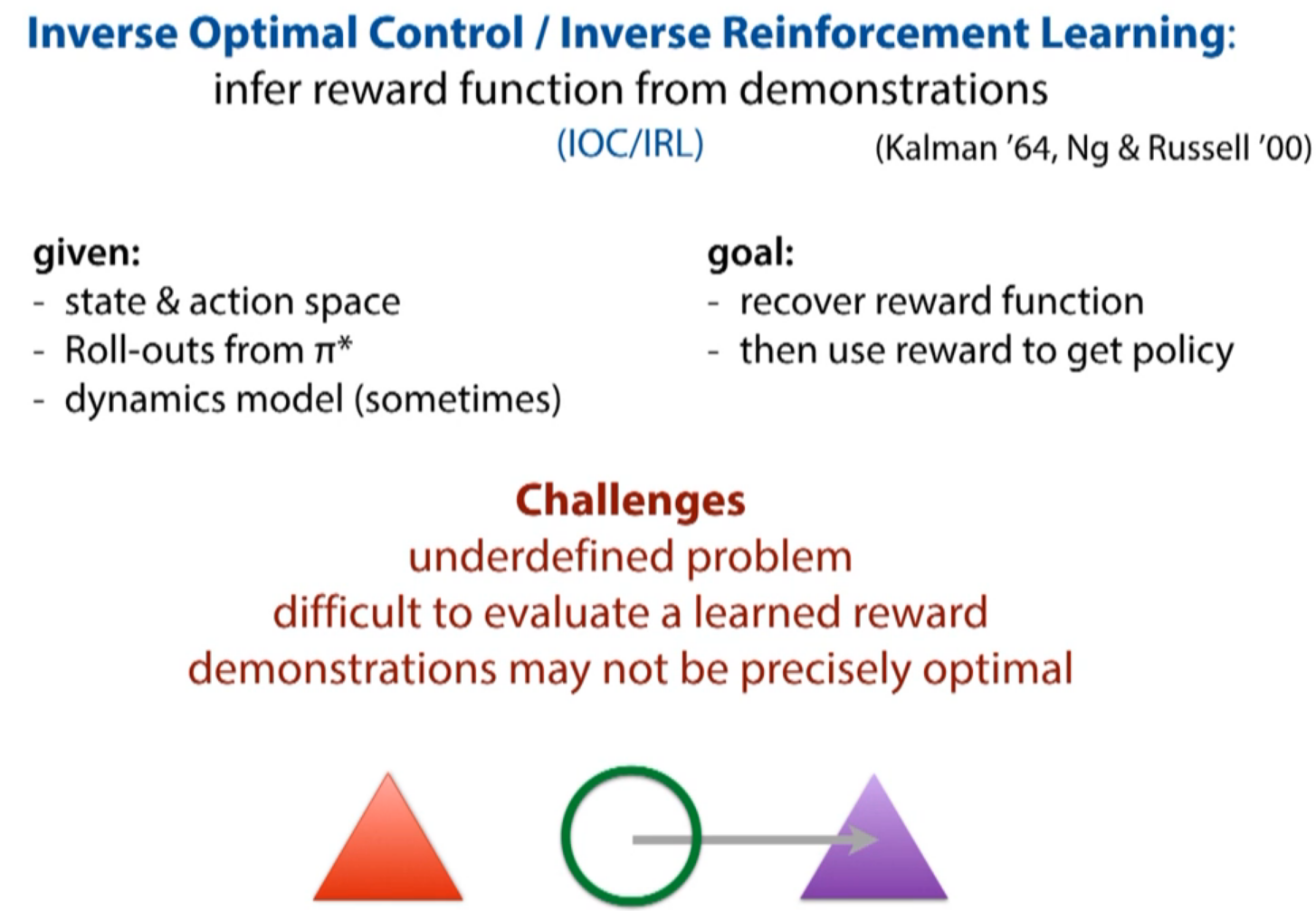
intrinsic ambiguity: move toward purple triangle? move away from red triangle? move along grey arrow? or the combine of them?



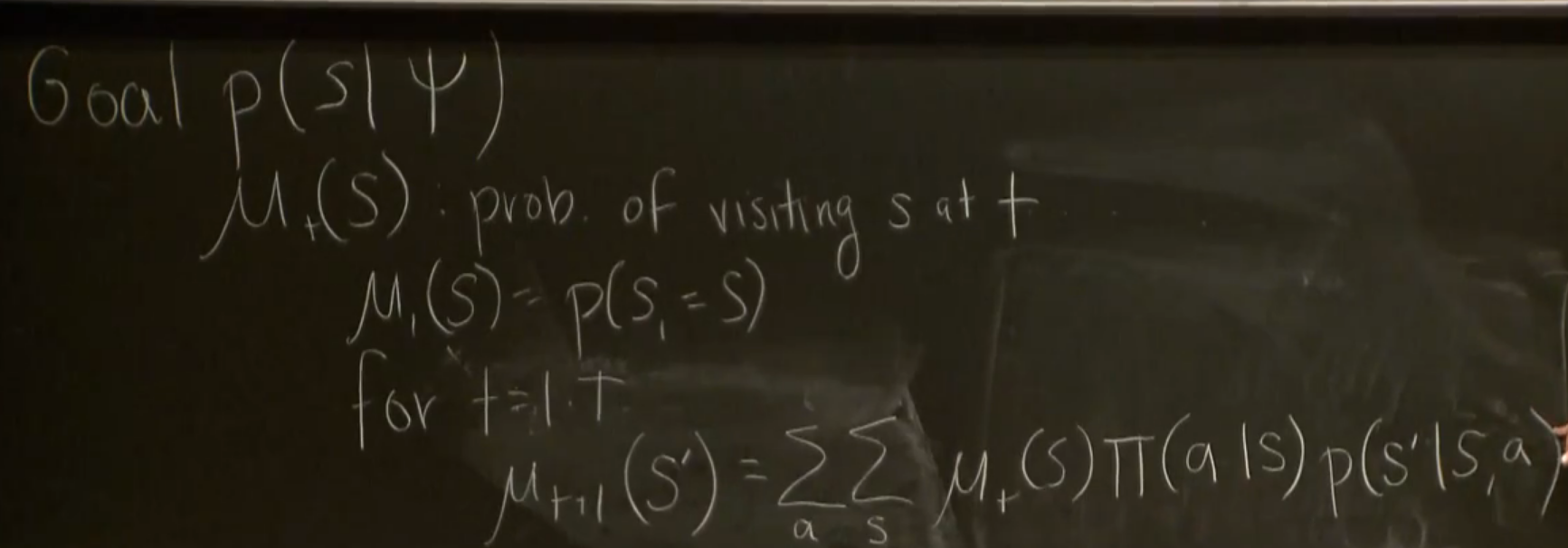
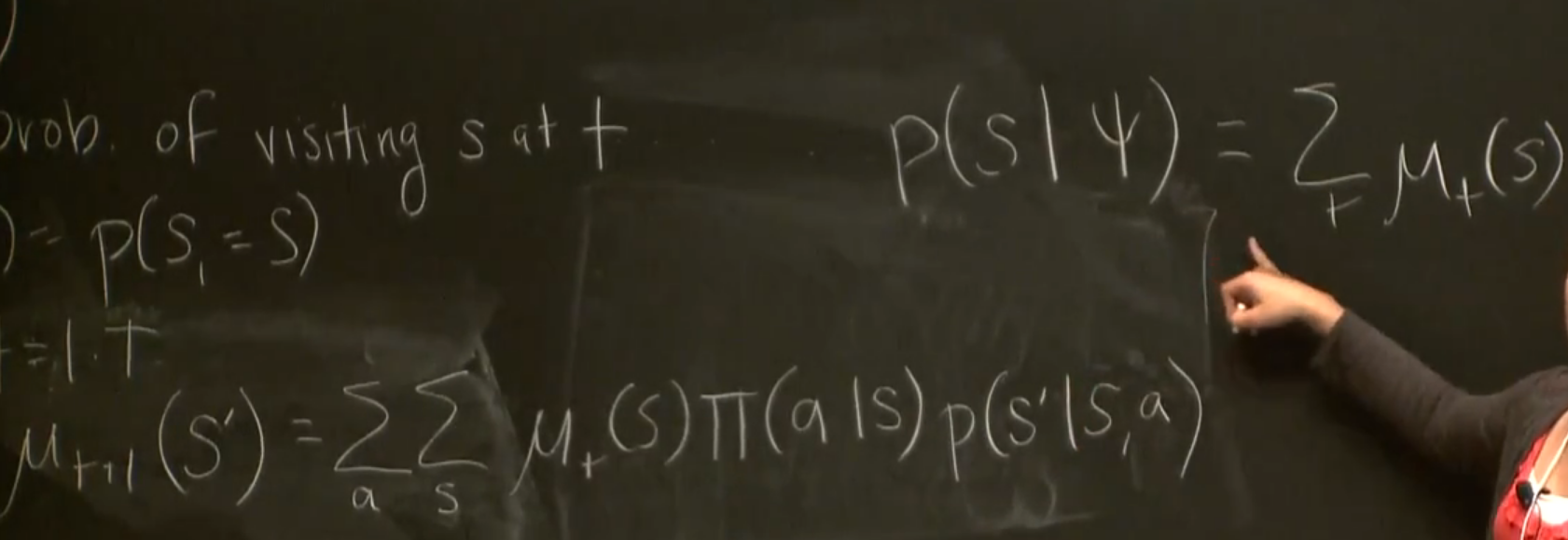
the right part of the right top equation should be divided by T

the original paper used linear function, but equations here aren't limited to linear function.

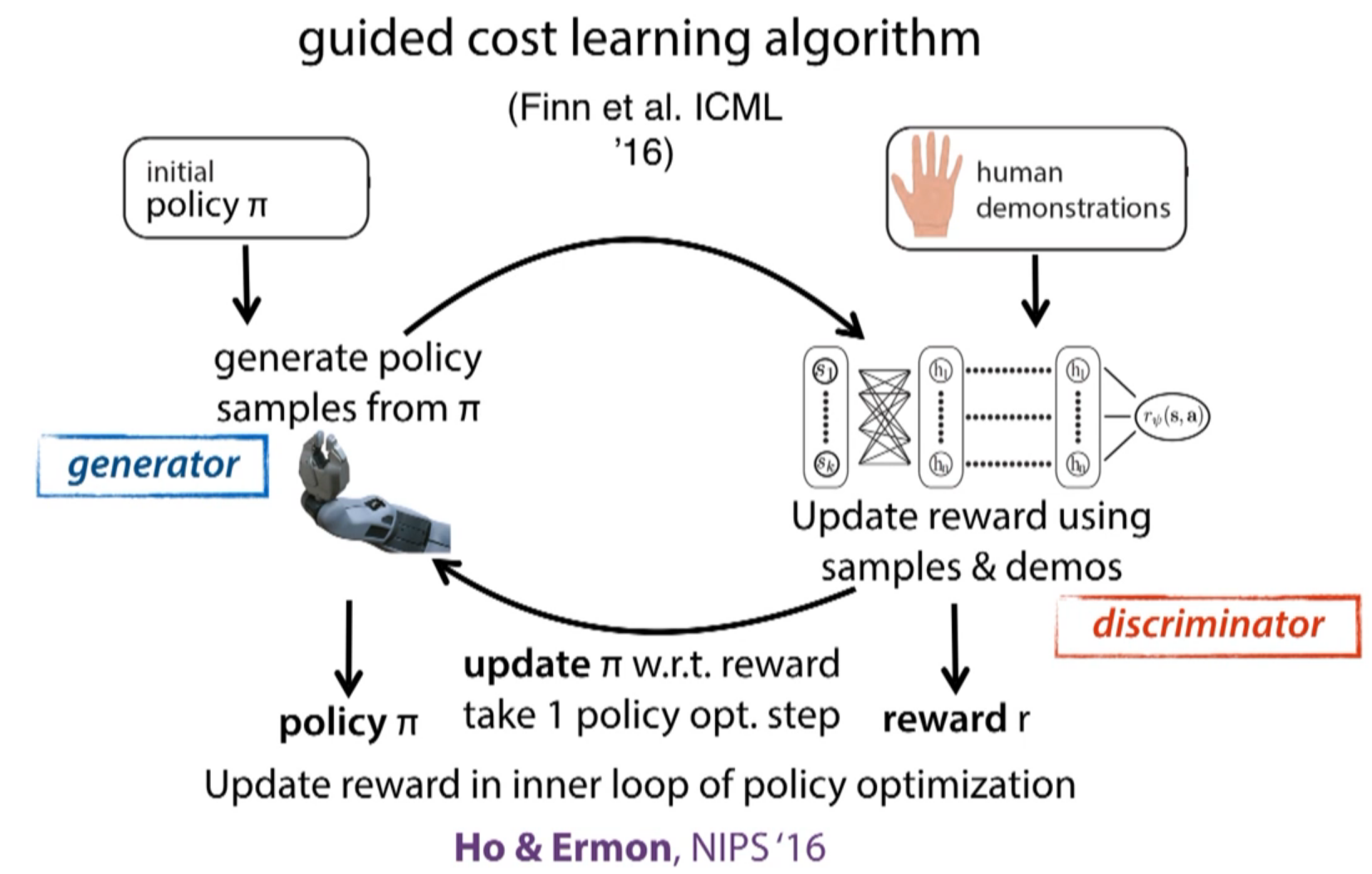
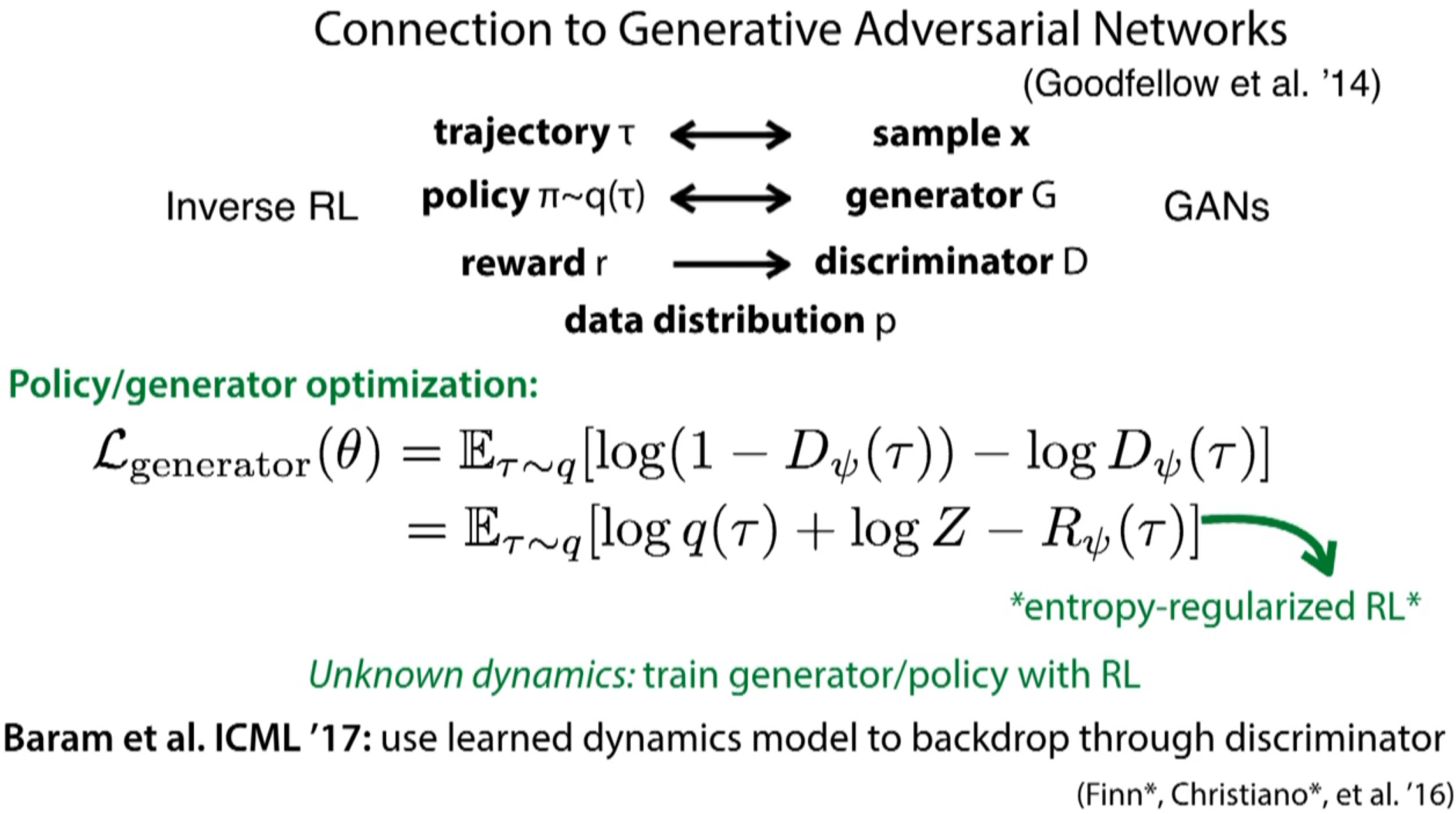
Ho & Ermon's 2016 paper has similar high level structure





robot execuated tasks under the help of human

standard cost/reward function in the algorithm like policy search
cost function is the negetive of the reward function
this video will fail. this isn't to say that we can't that handle of reward function for this task, but require a lot of trials and errors. a lot more difficult than demonstrating how to do that by hand.
it's quite aggressive, because it's trying to get to the goal position as quickly as possible.

this is the result, if you run cross entropy



here is the result running relative entropy in RL. Again, it didn't get a good sense of how to successfully perform the taskj.

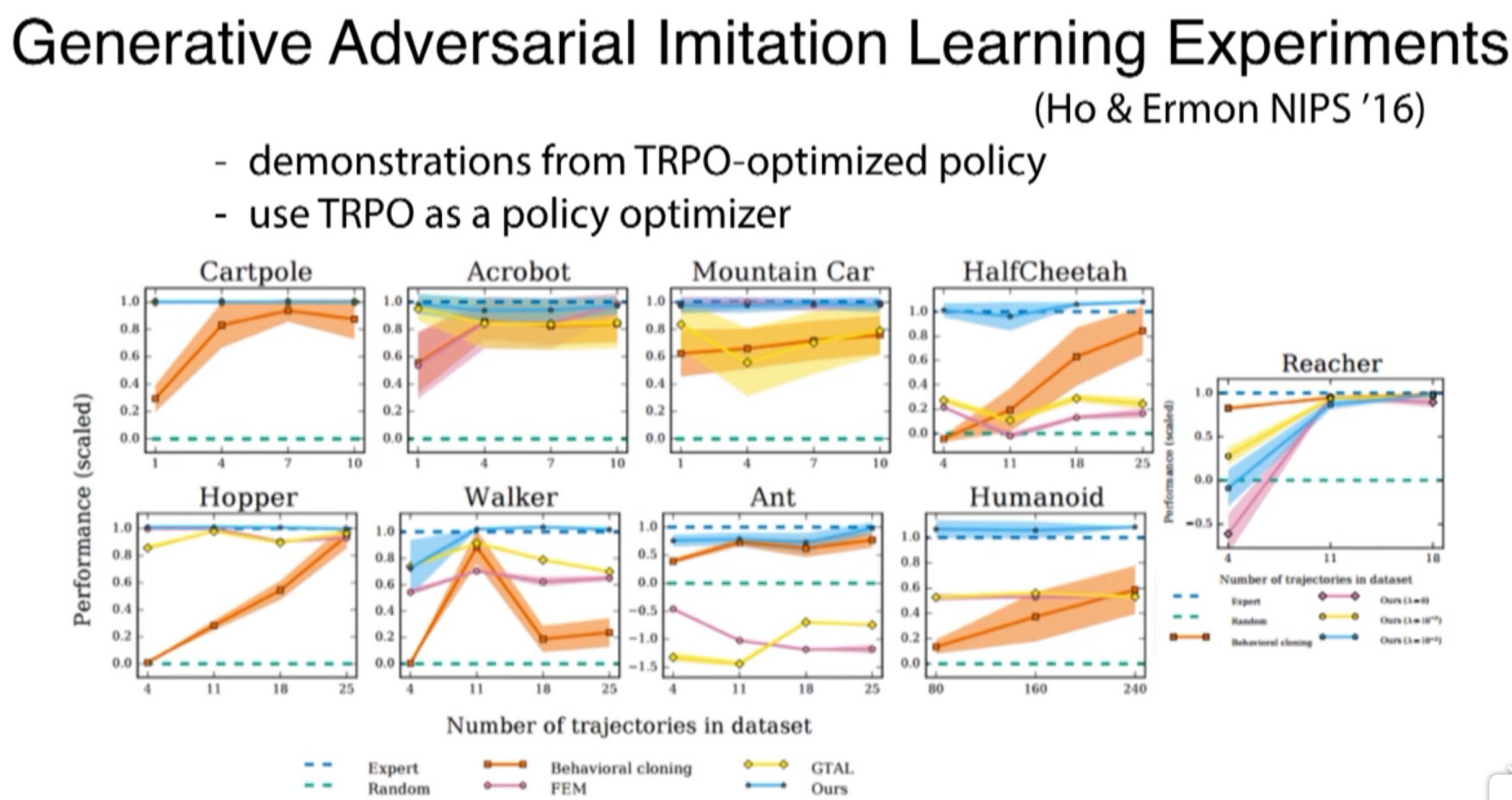

orange: behavior cloning
blue: GAN ...???


Linitations, NO.2: most data used here is low-dimensional feature spaces
NO.2: first person point of view, not what the robot sees


