AlexNet网络架构
网络共有8层,五个卷积层和三个全连接层。接下来介绍一下网络架构的一些特点。
1.ReLU Nonlinearity
标准情况下神经元的输出一般采用tanh或者sigmoid作为激活函数,但是就梯度下降的训练时间而言,这些饱和非线性函数要比非饱和非线性函数f(x) = max(0, x)慢得多,这里将这种非线性单元称为Rectified Linear Units (ReLUs)。带有ReLU的深度卷积神经网络的训练速度比带有tanh的快几倍。
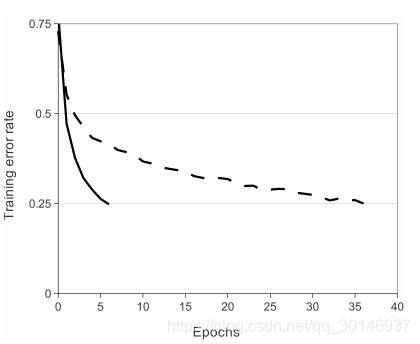
上图显示了在特定的四层卷积网络中,分别以ReLU和tanh作为激活函数在CIFAR-10数据集上达到25%的训练错误率所需的迭代次数。可以看到,ReLU(实线)比tanh(虚线)收敛速度快六倍。这表明如果继续使用传统的饱和神经元模型将无法在如此大规模的神经网络上进行实验。
2.Training on Multiple GPUs
单个GTX580 GPU的内存只有3GB,因此在其上训练网络的最大大小也会受到限制。当前的GPU特别适合跨GPU并行化操作,因为它们能够直接读取和写入彼此的内存,而无需通过主机内存。作者将网络放在两个GPU上,具体来说就是采用并行化的方案将卷积核(或神经元)的一半分别放在每个GPU上,并且GPU仅在某些层进行通信。例如,第三层的卷积核从第二层中的所有卷积核映射(kernel maps)中获取输入,我的理解是第二层所有卷积核得到的feature maps作为第三层卷积核的输入。但是第四层的卷积核仅从位于同一GPU上的第三层中的kernel maps中获取输入,我的理解是第四层的卷积核的输入来自于和它位于同一个GPU上的第三层的卷积核得到的feature maps。
3.Local Response Normalization
首先提到神经生物学中的一个概念叫做侧抑制(lateral inhibitio),指的是被激活的神经元抑制相邻神经元。归一化(normalization)的目的就是抑制,LRN就是借鉴侧抑制的思想来实现局部抑制,尤其是使用RELU的时候,这种“侧抑制”很有效。在卷积层的激活函数后进行LRN操作,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。公式如下:
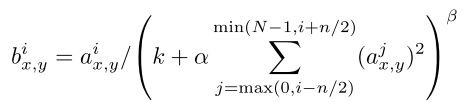
ai(x,y)代表的是ReLU在第i个kernel的(x, y)位置的输出,n表示的是ai(x,y)的邻居个数,N表示kernel的总数。bi(x,y)表示LRN的输出结果。ReLU输出的结果和它周围一定范围的邻居做一个局部的归一化。
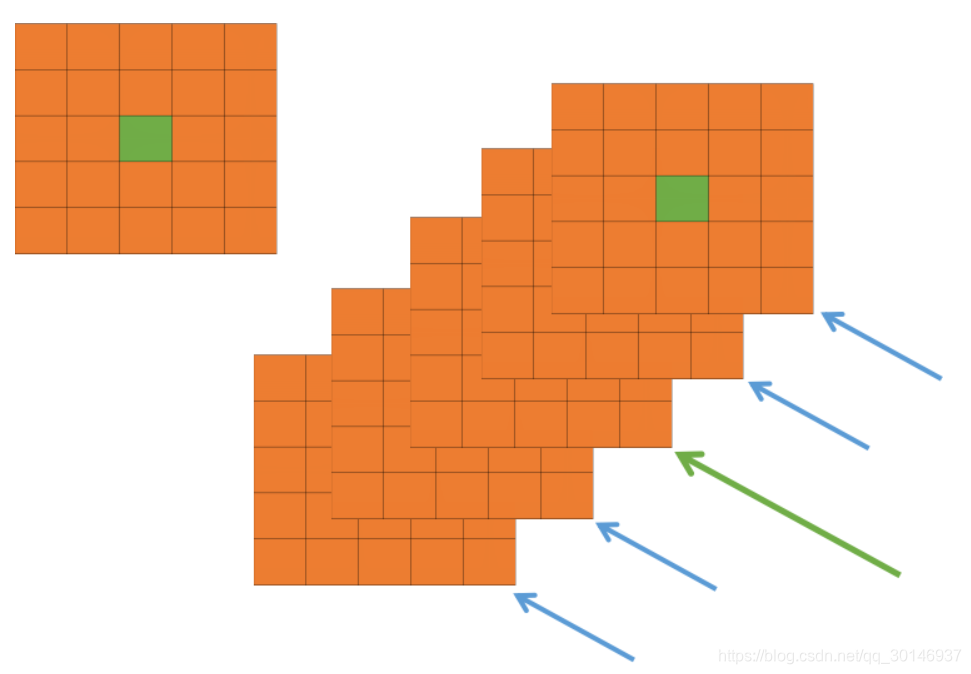
我们看上图,每一个矩形表示一个kernel生成的feature map。所有的pixel已经经过了ReLU激活函数,现在我们都要对具体的pixel进行局部的归一化。假设绿色箭头指向的是第i个kernel对应的feature map,其余的四个蓝色箭头是它周围的邻居kernel对应的feature map,假设矩形中间的绿色的pixel的位置为(x, y),那么我需要提取出来进行局部归一化的数据就是周围邻居kernel对应的feature map的(x, y)位置的pixel的值。也就是上面式子中的ai(x,y)。然后把这些邻居pixel的值平方再加和,乘以一个系数α再加上一个常数k,然后β次幂,就是分母。分子就是第i个kernel对应的feature map的(x, y)位置的pixel值。常数k、n、α和β都是超参数(hyper-parameters),它们的值都由验证集决定。
4.Overlapping Pooling
一般的池化层中,pool_size和stride是相同的。例如8×8的一个图像,如果池化层的尺寸是2×2,那么经过池化操作得到的图像是 4×4大小,这种叫做不重叠的池化操作。当stride<pool_size时,就会产生重叠的池化操作。比如还是8×8的一个图像,pool_size为2×2,但是stride为1,那么经过池化操作得到的图像是7×7。论文指出,在训练模型的过程中,具有重叠池化层的模型会更难拟合。
5.Overall Architecture
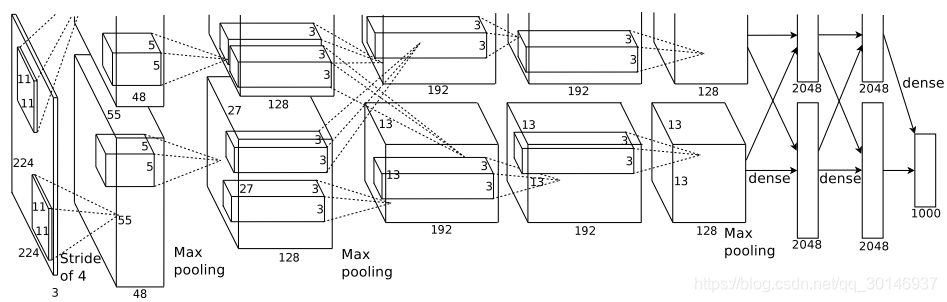
之前说了,这个网络在两个GPU上运行,我们可以把上图看成上下两部分,上层运行在一个GPU上,下层运行在另一个GPU上,GPU只在某些层进行联系。
如上图所示,这个网络共有8层,前5个是卷积层,后3个是全连接层,最后一个全连接层的输出被送入到一个1000维的softmax函数中,产生1000个类标签的分布。第2、4、5层的卷积核仅与位于同一GPU上的上一层的卷积核映射相连,第3层的卷积核与第2层中所有的卷积核映射相连。LRN在第1、2个卷积层之后,最大池化层在LRN和第5个卷积层之后。RELU函数作为所有卷积层和全连接层输出的激活函数。
第一个卷积层输入224x224x3的图像,对其用96个尺寸为11x11x3,步长为4的卷积核进行处理。第二个卷积层将第一个卷积层的输出结果(包括LRN和池化)作为输入,用256个尺寸为5x5x48的卷积核进行处理。第三、第四、第五个卷积层彼此连接,中间没有LRN和池化。第三个卷积层有384个尺寸为3x3x256的卷积核,其输入为第二个卷积层的输出(包括LRN和池化)。第四个卷积层有384个尺寸为3x3x192的卷积核,第五个卷积层有256个3x3x192的卷积核。全连接层共有4096个神经元。
如何减少过拟合?
1.Data Augmentation
减少过拟合最简单最常用的方法就是通过标签保留转换(label-preserving transformations)来人工地扩大数据集。作者采用了两种不同的数据增强方式,每种都会从原始图片中通过很少的计算生成转换图片,所以转换后的图片不需要存储在硬盘上。在实现过程中,转换图片在CPU上由python代码生成,而与此同时GPU还在训练上一批次的图片,所以这些数据增强方案实际上是很高效的。
数据增强的第一种方式包括平移图像和水平映射。作者从尺寸为256x256的图像中提取出随机的224x224的图像块(包括它们的水平映射),然后在这些图像块上对网络进行训练。这虽然使训练集的规模增大了2048倍,但由此产生的训练样本还是高度相互依赖的。在测试时,网络通过提取5个224x224的图像块(四个角和中心的图像块)以及它们的水平映射(总共十个图像块)来进行预测,然后求softmax函数对这十个图像块得出的预测结果的均值。
数据增强的第二种方式是改变训练图像RGB通道的灰度。具体来说,在整个ImageNet训练集中,对图像的RGB像素值进行PCA操作,为每个训练图像添加多个通过PCA找到的主成分,大小与相应的特征值成比例,然后乘以一个随机值,这个随机值属于均值为0,标准差为0.1的高斯分布。添加以下值:
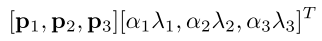
pi和λi分别表示3x3的RGB协方差矩阵的第i个特征向量和第i个特征值,αi是上面提到的随机数。对于一个特定训练图像的所有像素,每个αi只能被获取一次,直到这个图象再次被用来训练,才会重新获取随机数。
2.Dropout
减少预测错误率的一种成功的方法是结合许多不同模型的预测结果,但这样做对于已经花费数天时间训练的大型神经网络来说,成本太高了。dropout操作会以50%的概率将隐层神经元的输出置为0,以这种方法被置0的神经元不参与网络的前馈和反向传播。因此每次给网络提供一个输入后,神经网络都会采用不同的结构,但是所有这些结构都共享权重。这项技术减少了神经元的复杂适应性,因为一个神经元无法依赖于其他特定的神经元而存在。在本文的神经网络中,在前两个全连接层上使用了dropout方法,如果没有dropout,会出现严重的过拟合。dropout操作会使达到收敛的迭代次数翻倍。
参考:https://blog.csdn.net/yangdashi888/article/details/77918311
https://blog.csdn.net/hduxiejun/article/details/70570086
https://blog.csdn.net/luoluonuoyasuolong/article/details/81750190
