一元线性回归分析
步骤:
A.建立回归模型;
B.求解回归模型中的参数;
C.对回归模型进行检验。
R中,与线性模型有关的函数有:lm()、summary()、anova()和predict()。我们由例子入手,逐步学习这些函数。
例1:
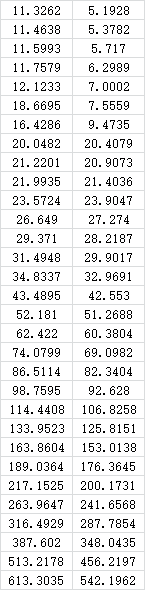
财政收入与税收有密切的依存关系。d4.3给出我们1978年改革开放以来到2008年共31年的税收(x,百亿元)和财政收入(y,百亿元)数据,试分析税收与财政收入之间的依存关系。
(1) 读入数据
> yx=read.table("clipboard",header=T) ##在d4.3中选取B1:C32区域,然后拷贝
(2)拟合模型
> fm=lm(y~x,data=yx)
> fm
结果
Call:
lm(formula = yx$y ~ yx$x)
Coefficients:
(Intercept) yx$x
6.7336 0.9982
(3)作回归直线
> plot(yx$x, yx$y)
> abline(fm)
(4)回归方程的假设检验
####1)模型的方差分析
> anova(fm)
结果
Analysis of Variance Table
Response: y
Df Sum Sq Mean Sq F value Pr(>F)
x 1 712077 712077 27428 < 2.2e-16 ***
Residuals 29 753 26
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
由于p<0.05,于是在0.05水平处拒绝原假设,即本例回归系数有统计学意义,x与y间存在直线回归关系。
####2)回归系数的显著性检验
> summary(fm)
Call:
lm(formula = yx$y ~ yx$x)
Residuals: ##残差的最小值,0.25分位点,中位数点,0.75分位点和最大值
Min 1Q Median 3Q Max
-76.763 -5.627 -1.264 3.003 51.066
Coefficients:
## Estimate是参数估计值,Std. Error表示参数的标准差,t value为t值,Pr(>|t|)为p值
Estimate Std. Error t value Pr(>|t|)
(Intercept) 6.73358 4.38003 1.537 0.135 ##常数项
yx$x 0.99824 0.02436 40.983 <2e-16 *** ##一次项
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 19.46 on 29 degrees of freedom ##残差的标准差
Multiple R-squared: 0.983, Adjusted R-squared: 0.9824 ##R方与调整R方
F-statistic: 1680 on 1 and 29 DF, p-value: < 2.2e-16 ##F值和p值
由于p<0.05,于是在0.05水平处拒绝原假设,即本例回归系数有统计学意义,x与y间存在回归关系。
(5)预测
当经过检验,回归方程是有意义时,可以用它作预测。
> new<-data.frame(x=700) ##输入新的点x=700,这里即时是一个点,也要采用数据框形式
> lm.pred<-predict(fm,new,interval="prediction",level=0.95)##给出预测值,interval="prediction"指给出预测区间,level=0.95表示相应概率为0.95
> lm.pred ##fit为预测值,lwr是95%下限,upr是95%上限
fit lwr upr
1 705.5033 655.461 755.5456
2 多元线性回归分析
例2:
考察财政收入和国内生产总值x1,税收x2,进出口贸易总额x3,经济活动人口x4之间的数量关系,建立多元线性回归方程。
(1)读入数据
在d4.4中选取B1:F32区域,然后拷贝
> yX=read.table("clipboard",header=T)
(2)拟合模型
> (fm=lm(y~x1+x2+x3+x4,data=yX))
结果
Call:
lm(formula = y ~ x1 + x2 + x3 + x4)
Coefficients:
(Intercept) yX$x1 yX$x2 yX$x3 yX$x4
23.5321088 -0.0033866 1.1641150 0.0002919 -0.0437416
(3)方程的标准化系数
由于自变量与因变量都是有单位的,从数值上来看,它们样本取值的极差会有很大的差异,均数与标准差也各不相同,所以不能由偏回归系数的大小直接说明对因变量线性影响的大小。对于这个问题常用变量标准化与计算标准化偏回归系数的方法来处理。标准化后常数项为0,且各变量的标准差相同,可用偏回归的系数的值来反映各自变量在其他自变量固定时对因变量线性影响的大小,相互之间可进行比较。
常用的统计软件都能给出标准化偏回归系数,但R语言中并不包含计算标准回归系数的函数。因此需要自编。

> library(mvstats)
> coef.sd(fm)
$coef.sd
x1 x2 x3 x4
-0.0174513678 1.0423522972 0.0009628564 -0.0371053994
由标准化偏回归系数可见,税收对财政收入的线性影响最大。
(4)回归方程的假设检验
> summary(fm)
Call:
lm(formula = y ~ x1 + x2 + x3 + x4, data = yX)
Residuals:
Min 1Q Median 3Q Max
-5.0229 -2.1354 0.3297 1.2639 6.9690
##系数的t值和p值,系数的显著性检验
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 23.5321088 4.5990714 5.117 2.47e-05 ***
x1 -0.0033866 0.0080749 -0.419 0.678
x2 1.1641150 0.0404889 28.751 < 2e-16 ***
x3 0.0002919 0.0085527 0.034 0.973
x4 -0.0437416 0.0092638 -4.722 7.00e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.79 on 26 degrees of freedom
Multiple R-squared: 0.9997, Adjusted R-squared: 0.9997
F-statistic: 2.289e+04 on 4 and 26 DF, p-value: < 2.2e-16 ##方程的F值和p值,方程的显著性检验
模型的p<0.0001,故本例回归模型是有意义的。
偏回归系数b2,b4的p值都小于0.01,可认为解释变量税收x2和经济活动人口x4显著;b1,b3的p值大于0.50,不能否定b1=0,b3=0的假设。可认为国内生产总值x1和进出口贸易总额x3对财政收入y没有显著的影响。我们可以看到,国内生产总值、经济活动人口所对应的偏回归系数都为负,这与经济现实是不相符的。出现这种结果的可能原因是这些解释变量之间存在高度的共线性。
(5)预测
> new<-data.frame(x1=30,x2=40,x3=50,x4=100)
> lm.pred<-predict(fm,new,interval="prediction",level=0.95)
> lm.pred
结果
fit lwr upr
1 65.63555 56.8971 74.37399
| yx |
|