什么是回归?
回归是指研究某一个变量(称为因变量)与一个或多个变量(称为自变量或解释变量)之间的相互依赖关系,或者说用自变量解释因变量的变化,进一步,对于自变量(在重复抽样中)的给定值,估计或预测因变量的总体均值。
变量间的关系:
(1)确定性关系或函数关系:研究的是确定现象非随机变量间的关系。
- 是一一对应的确定关系
- 设有两个变量x和y,变量y随变量 x一起变化,并完全依赖于x,当变量x取某个数值时,y依确定的关系取相应的值,则称y是x
的函数,记为y=f(x),其中x称为自变量,y称为因变量 - 各观测点落在一条线上
(2)统计依赖或相关关系:研究的是非确定现象随机变量间的关系。
- 变量间关系不能用函数关系精确表达
- 一个变量的取值不能由另一个(或某一些)变量唯一确定
- 当变量x 取某个值时,变量y的取值可能有几个
- 各观测点分布在直线周围
回归分析与相关分析的区别:
- 相关分析中,变量x和变量y处于平等的地位;回归分析中,变量y称为因变量,处在被解释的地位,x称为自变量,用于预测因变量的变化
- 相关分析中所涉及的变量x和y都是随机变量;回归分析中,因变量y是随机变量,自变量x可以是随机变量,也可以是非随机的确定变量
- 相关分析主要是描述两个变量之间线性关系的密切程度;回归分析不仅可以揭示变量x对变量y的影响大小,还可以由回归方程进行预测和控制
回归分析的步骤:
- 根据客观对象的定性认识确定变量之间是否存在相关关系;
- 判断相关关系的大致类型;
- 绘制散点图,并初步推测回归模型;
- 进行回归分析并拟合出回归模型;
- 对回归模型的可信度进行检验;
- 运用模型进行预测;
R语言与回归分析
可决系数


可决系数定量地描述了Y的变化中可以用回归模型来说明的部分,即在被解释变量的变动中,由模型中解释变量所引起的比例。
注意:可决系数只是说明列入模型的所有解释变量对被解释变量的联合影响程度,不说明模型中每个解释变量的影响程度
回归的主要目的如果是经济结构分析,不能只追求高的可决系数,而是要得到总体回归系数可信的估计量。可决系数高并不一定每个回归系数都可信。
修正的可决系数与原来的可决系数的关系与区别: 关系:两者都是对模型拟合优度进行检验。修正后的可决系数是在原来的可决系数的基础上运用自由度进行了修正。 区别:修正后的可决系数消除了拟合优度评价中解释变量多少对决定系数计算的影响。对于包含解释变量个数不同的模型可以用调整后的可决系数来比较,但不能用原来的未调整的决定系数来比较。
举例:
为了研究某社区家庭月消费支出与家庭月可支配收入之间的关系,随机抽取并调查了12户家庭的相关数据。通过调查所得的样本数据能否发现家庭消费支出与家庭可支配收入之间的数量关系,以及如果知道了家庭的月可支配收入,能否预测家庭的月消费支出水平呢?
> consume=c(594,638,1122,1155,1408,1595,1969,2078,2585,2530)
> income=c(800,1100,1400,1700,2000,2300,2600,2900,3200,3500)
绘制出散点图:
> plot(income,consume)
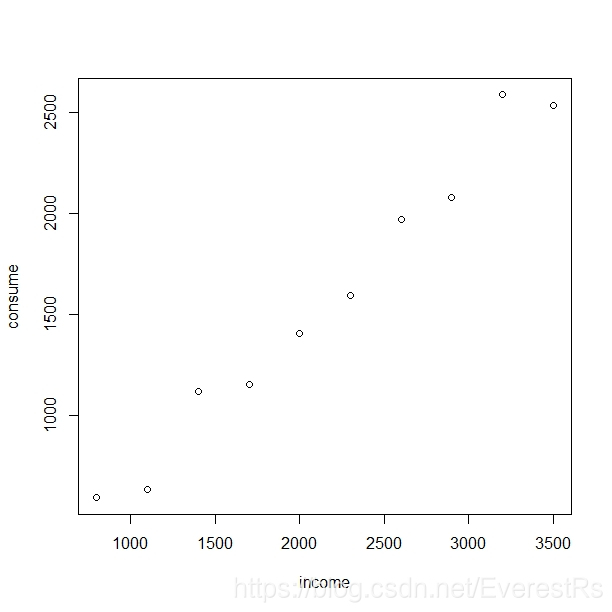
注:
pch (绘图符号设置参数) :绘图时我们可以用各类符号显示数据,pch是plotting character 的缩写。pch缺省下设定数据显示为点状。pch 符号可以使用0 : 25来表示26 个标识(参看图pch 符号),如pch=23设定数据点显示形状为菱形;当pch=0时不显示任何符号;当然我们也可以任意指定如#;%; ¤; j;+;¡; :; o等符号。值得注意的是,21 : 25这几个符号可以使用bg=“颜色” 参数进行不同的颜色填充。颜色参数col则可以用于设置1:25所表示符号的颜色。
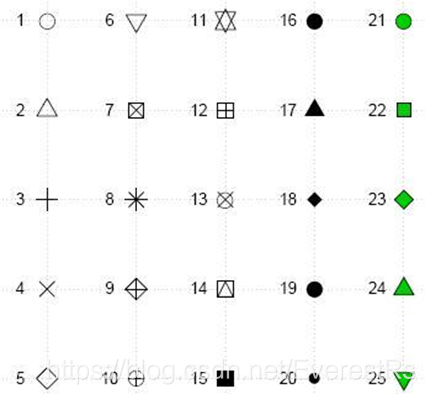
cex:指定符号的大小。cex是一个数值,表示pch的倍数,默认是1.5倍
lty:指定线条类型。lty=1代表实线,2至6都是虚线,虚的程度不一样
lwd:指定线条宽度,默认值为lwd=1,可以适当修改1.5倍、2倍等
求相关系数:
> cor(income,consume)
[1] 0.9882517
生成回归模型:
lm()函数
lm(formula, data, subset, weights, na.action, method = "qr", model = TRUE, x = FALSE, y = FALSE, qr = TRUE, singular.ok = TRUE, contrasts = NULL, offset,...)
> model=lm(consume~income) 有截距
> model
Call:
lm(formula = consume ~ income)
Coefficients:
(Intercept) income
-103.172 0.777
> model=lm(consume~income-1) 无截距
> model
Call:
lm(formula = consume ~ income - 1)
Coefficients:
income
0.7357
添加回归趋势线:
> abline(lm(consume~income))
提取估计系数:
> coef(model)
(Intercept) income
-103.1717172 0.7770101
或
> coefficients(model)
(Intercept) income
-103.1717172 0.7770101
显示回归结果
> summary(model)
Call:
lm(formula = consume ~ income)
Residuals:
Min 1Q Median 3Q Max
-113.54 -82.81 -52.80 69.66 201.74
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -103.17172 98.40598 -1.048 0.325
income 0.77701 0.04249 18.289 8.22e-08 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 115.8 on 8 degrees of freedom
Multiple R-squared: 0.9766, Adjusted R-squared: 0.9737
F-statistic: 334.5 on 1 and 8 DF, p-value: 8.217e-08
注:通过summary函数可以看出可决系数r.squared、残差等
绘制回归模型
> plot(model)
预测
> point=data.frame(income=2000)
> predict(model,point,interval="prediction”) 预测区间
fit lwr upr
1 1471.329 1198.367 1744.291
> predict(model,point,interval="confidence") 置信区间
fit lwr upr
1 1471.329 1467.221 1475.437
注:
在函数predict中,参数model是之前建立的线形模型,point是要预测的点,参数interval="prediction"表示要求给出预测的区间(上下界)
置信区间估计(confidence interval estimate):利用估计的回归方程,对于自变量 x 的一个给定值 x0 ,求出因变量 y 的平均值的估计区间。
预测区间估计(prediction interval estimate):利用估计的回归方程,对于自变量 x 的一个给定值 x0 ,求出因变量 y 的一个个别值的估计区间。
如果求样本内X给定下的拟合值,可以调用fitted()函数
fitted(model)
如果求回归的残差,可以调用resid()函数
resid(model)