本文同步发表于我的微信公众号,扫一扫文章底部的二维码或在微信搜索 极客导航 即可关注,每个工作日都有文章更新。
一、概况
上一篇我们用一个表情网站入门了爬虫,爬了很多表情。今天我们继续在爬的路上,今天就爬个校花吧,毕竟妹子属于稀缺资源,要不妈妈总会问,你到底找不找女朋友了,爬点校花吧,以后跟妈妈聊天,可以哭着对她说,这就是我女朋友,漂亮吧~。行了,为了妈妈不担心,我们开始行动吧。
二、准备
在爬之前,我们要确定我们爬取的网站以及要爬取的哪些信息。
- 目标网站:校花网(http://www.xiaohuar.com/list-1-1.html)
- 获取信息:
- 校花的名字
- 校花的照片
- 校花的详细资料
确定好要爬的东西,就开始分析网站,其实我特别想获取联系方式,可是实力不允许呀。没有~
三、首页分析
- URL地址变化分析
不解释了,每页的地址应该能看的清清楚楚,明明白白。
- 提取信息分析
我们确定了每张图片都是一个独立的div标签,那么我首要任务就是把每页的div标签全部在爬下来
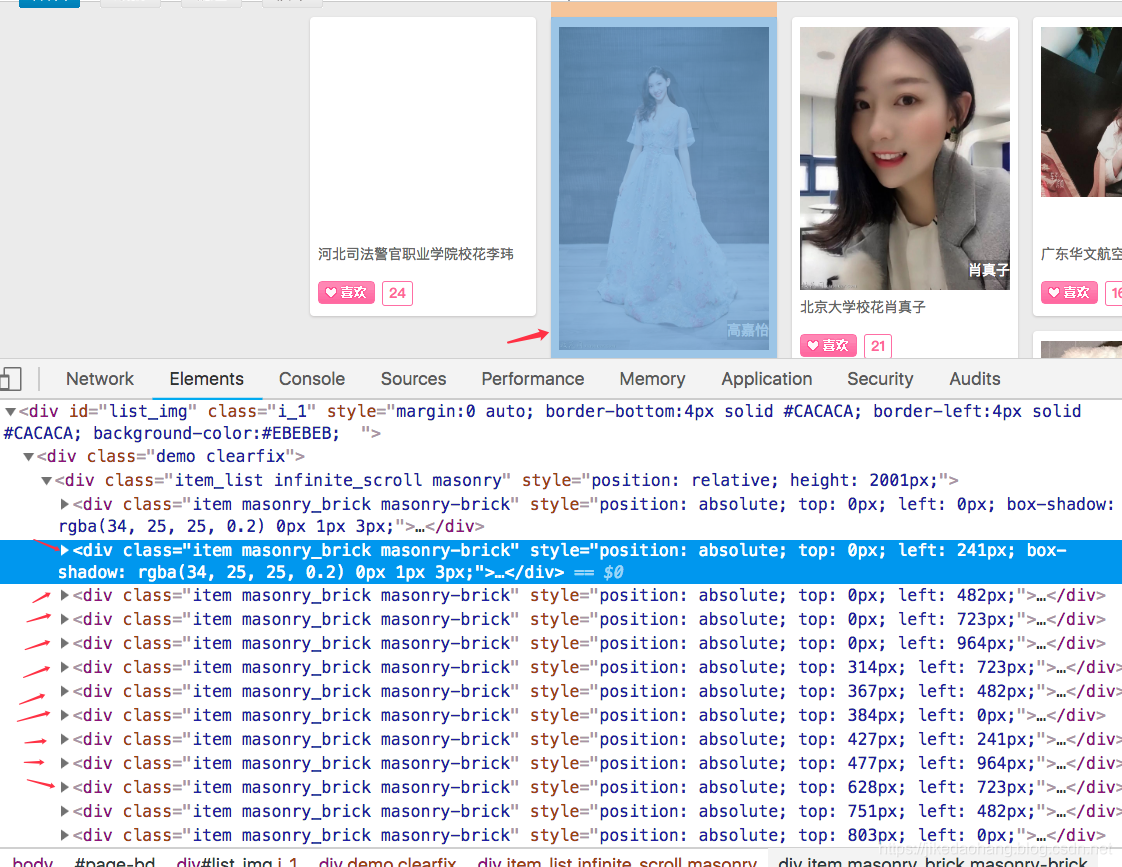
我们随便点一个div,看看里面的标签,从每个div里面我们可以取出下面这些信息。那么详细信息我们去哪取,对,校花的详细信息在详情链接,我们要把详情链接取出来,在去里面看看有什么?
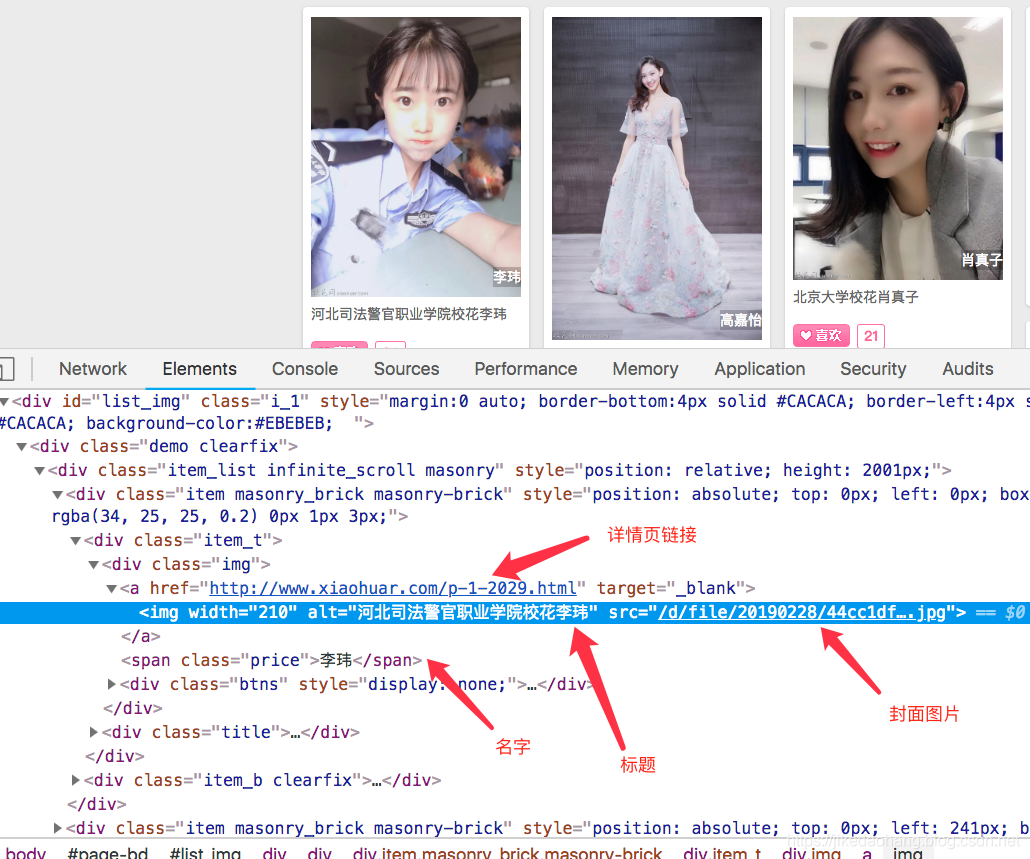
打开详细链接,我们可以看到如下信息,是我们想要的,有些信息确实没有,那也没办法了。
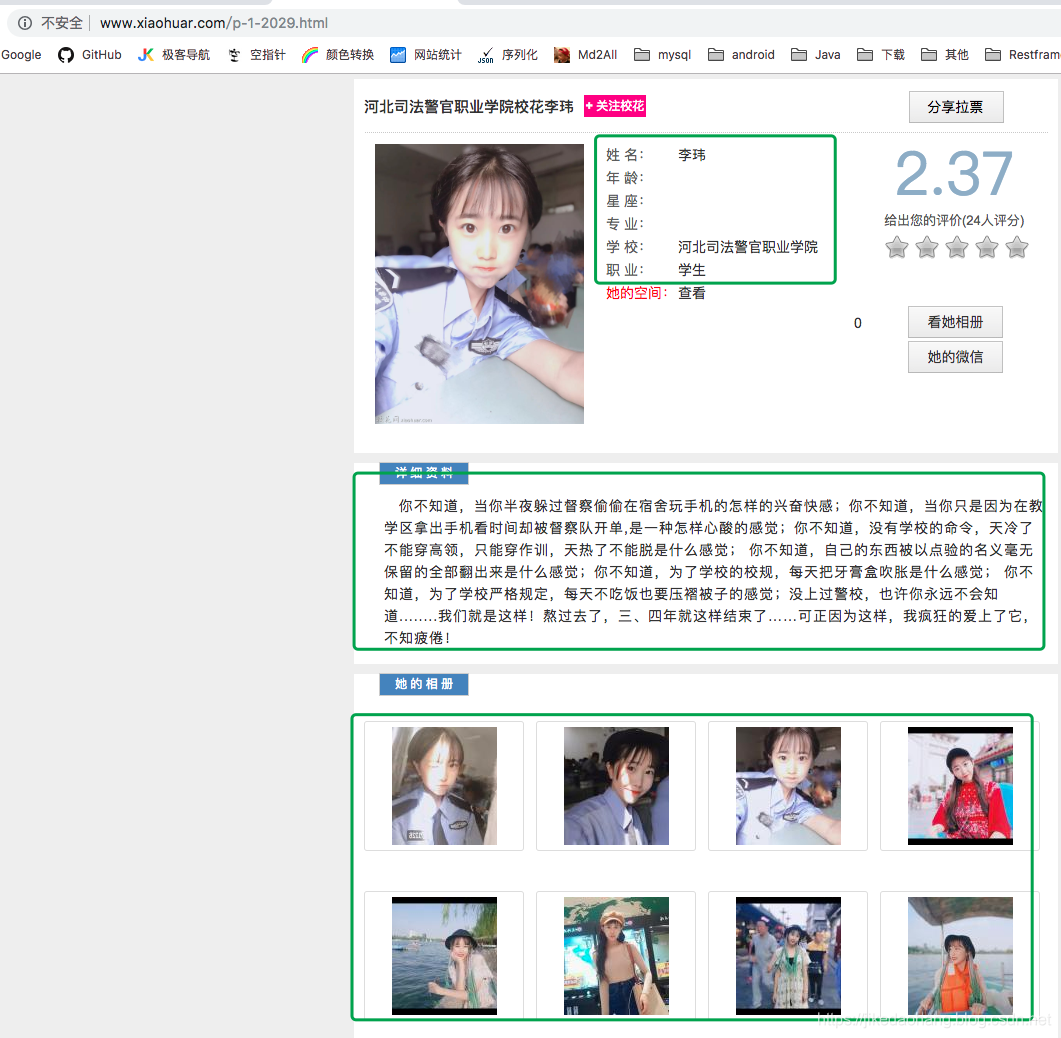
先分析到这,详情页的信息,我们先不管在哪个标签下,先把我们目前想要的这些信息获取出来在说。
四、首页提取
我们用xpath插件先简单定位一下,xpath有个特别好用的功能,就是模糊定位,我们发现想要的div标签class属性都包含一个一样的样式名字。
- 注意: 一定确保只是你想要的内容包括的样式。如果下面这个包含的是item属性,就会取出126个,这肯定是不对的。功能虽好,但是一定要慎重使用。
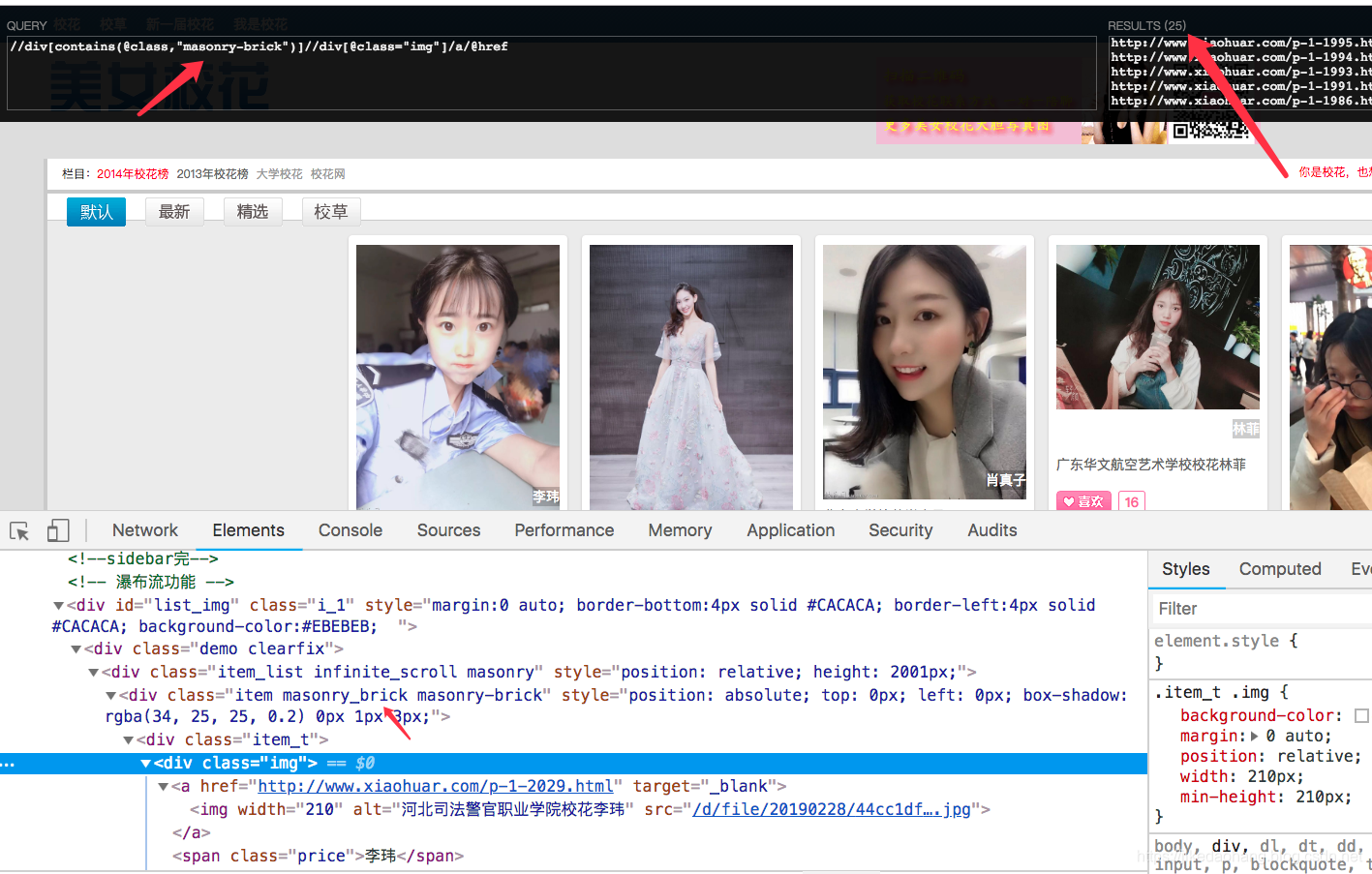
我们已经把最重要的信息详情地址爬取下来了,剩下的就是代码实现,代码跟上一篇的斗图啦项目的逻辑差不多。
import requests
from lxml import etree
import os
class XHSpider():
def __init__(self):
# 默认第一页开始
self.pn = 0
# 默认URL
self.url = 'http://www.xiaohuar.com/list-1-{0}.html'
# 添加请求头,模拟浏览器
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
# 发起请求
def loadpage(self):
# 拼接请求地址
req_url = self.url.format(self.pn) # http://www.xiaohuar.com/list-1-0.html
print(req_url)
# 发起请求
reponse = requests.get(url=req_url, headers=self.headers)
# 取返回的内容
content = reponse.text
'''
注意:如果发现用xpath插件在浏览器上能取到标签,但是在代码里面取不到
最好把请求下来的源代码保存到代码,分析一下为什么取不到,有时候
浏览器里面的源代码跟你在代码里面请求的源码可能稍微不一样。
'''
with open('xiaohua.html','w') as f:
f.write(content)
# 构造xpath解析对象
html = etree.HTML(content)
# 先取出这个页面所有div标签
div_list = html.xpath('//div[contains(@class,"masonry_brick")]')
for div in div_list:
# 从从每个div标签取出详情页链接 .代表当前位置
desc_url = div.xpath('.//div[@class="img"]//a/@href')[0]
# 标题
img_title = div.xpath('.//div[@class="img"]//img/@alt')[0]
# 封面图片地址
img_url= div.xpath('.//div[@class="img"]//img/@src')[0]
print(desc_url)
if __name__ == "__main__":
xhs = XHSpider()
xhs.loadpage()
#打印
http://www.xiaohuar.com/p-1-1997.html
http://www.xiaohuar.com/p-1-1995.html
http://www.xiaohuar.com/p-1-1994.html
http://www.xiaohuar.com/p-1-1993.html
http://www.xiaohuar.com/p-1-1991.html
http://www.xiaohuar.com/p-1-1986.html
......
上面有大家两个注意的地方
- 网站的编码格式
可以通过查看源码看到网站编码格式,可以看到这个网站并不是UTF-8的编码格式,我们可以直接用reponse.text让它自己东西编码解析。

- 代码里面请求网站源代码是否和浏览器的源代码是否一致
如果没出现取不到的情况,可以忽略这个问题。如果出现了,可以考虑一下是否是这出现的影响,在代码里面有注释。
五、详情页分析
- 资料
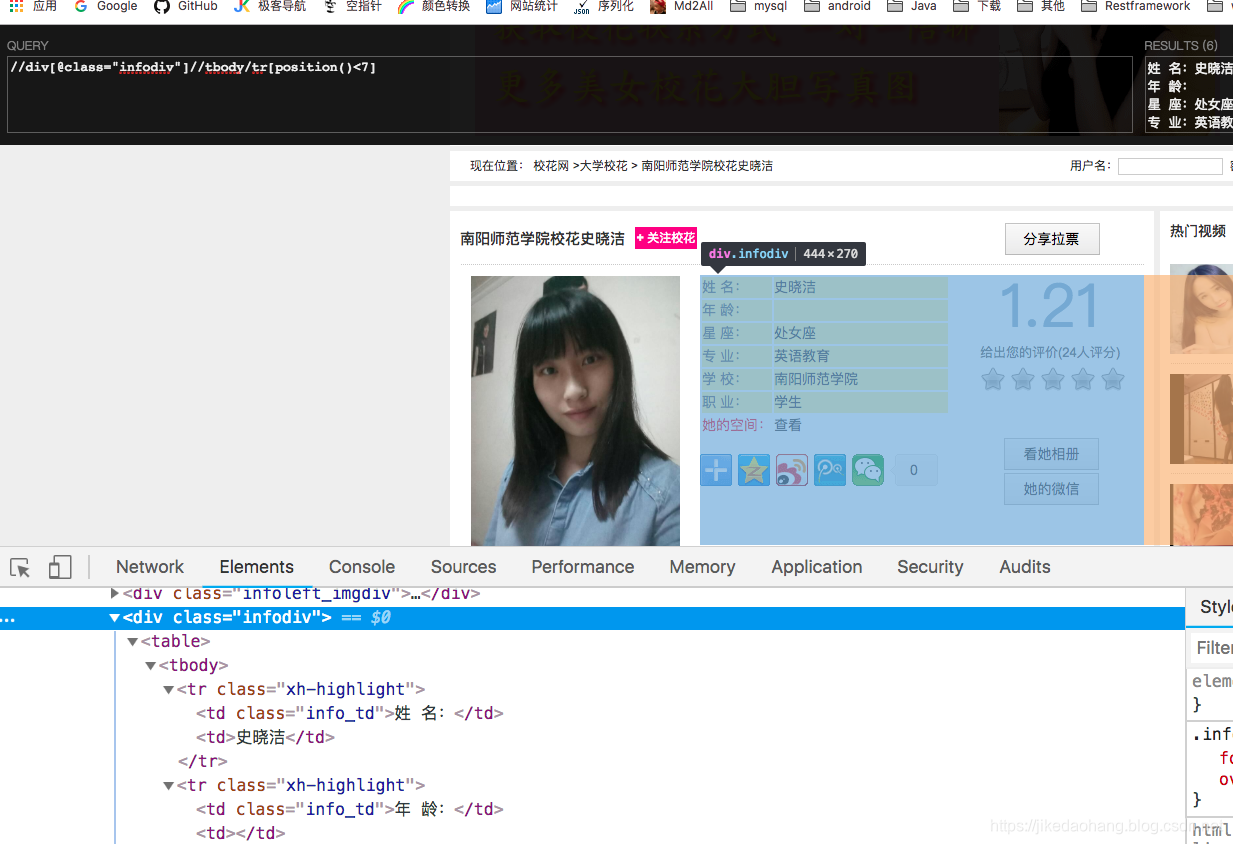
随便点开一个详情页地址,先取出资料信息,取前7个tr标签,最后一个标签不取。暂时看了几个网页,好像都是这几个,后面如果遇到问题,在做容错处理。
- 详细资料
详细资料比较好取,但是有需要注意的地方,有的校花没有详细资料。所以得做判空处理,有的详细资料标签不一样,所有咱们取父级div里面所有的文本就行。
特别提醒我这里面使用的//代表父标签任意的地方的文本。
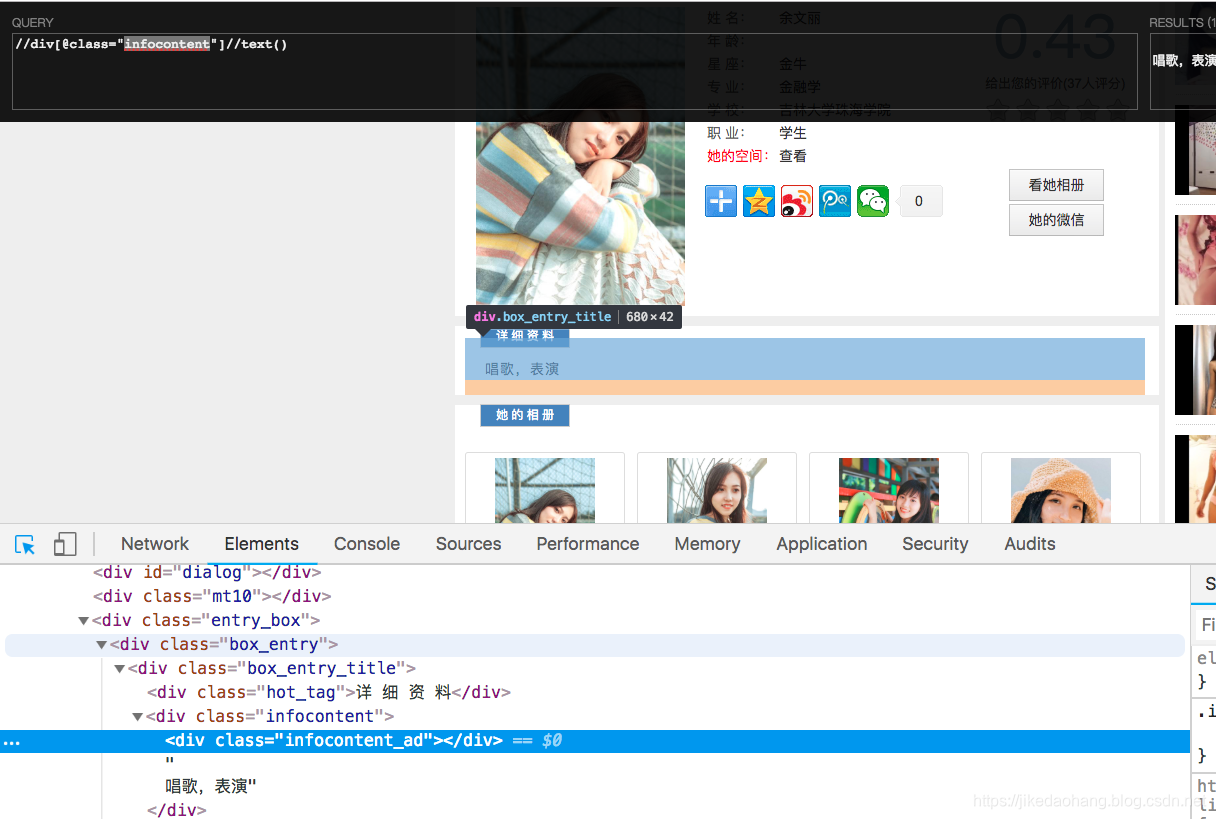
看起来直接取父亲标签下所有的内容应该是没问题。
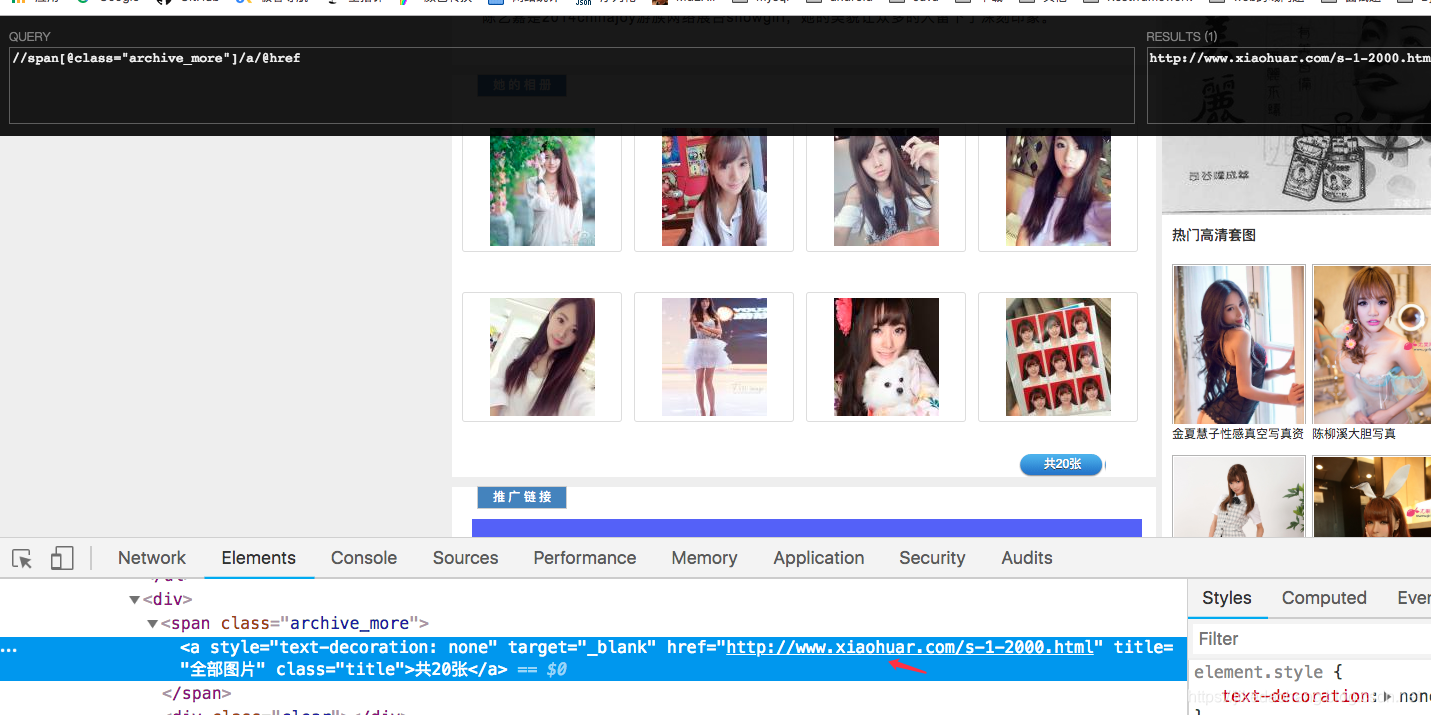
- 相册
我们相册都是小图,这不能是我们忍受的,我们要高清大图,但是要高清图片还要进入她的空间取获取。所以在相册这,我们只要获取到校花的空间地址就可以了。
这详情页基本上我们就需要取这些字段,去用代码一点一点爬下来。
import requests
from lxml import etree
import os
class XHSpider():
def __init__(self):
# 默认第一页开始
self.pn = 0
# 默认URL
self.url = 'http://www.xiaohuar.com/list-1-{0}.html'
# 添加请求头,模拟浏览器
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
# 发起请求
def loadpage(self):
# 拼接请求地址
req_url = self.url.format(self.pn) # http://www.xiaohuar.com/list-1-0.html
print(req_url)
# 发起请求
reponse = requests.get(url=req_url, headers=self.headers)
# 取返回的内容
content = reponse.text
'''
注意:如果发现用xpath插件在浏览器上能取到标签,但是在代码里面取不到
最好把请求下来的源代码保存到代码,分析一下为什么取不到,有时候
浏览器里面的源代码跟你在代码里面请求的源码可能稍微不一样。
'''
with open('xiaohua.html', 'w') as f:
f.write(content)
# 构造xpath解析对象
html = etree.HTML(content)
# 先取出这个页面所有div标签
div_list = html.xpath('//div[contains(@class,"masonry_brick")]')
for div in div_list:
# 从从每个div标签取出详情页链接 .代表当前位置
desc_url = div.xpath('.//div[@class="img"]//a/@href')[0]
# 标题
img_title = div.xpath('.//div[@class="img"]//img/@alt')[0]
# 封面图片地址
img_url = div.xpath('.//div[@class="img"]//img/@src')[0]
print(desc_url)
self.loaddescpage(desc_url)
#详情页
def loaddescpage(self, desc_url):
# 发起请求
reponse = requests.get(url=desc_url, headers=self.headers)
# 取返回的内容
content = reponse.text
# 构造xpath解析对象
html = etree.HTML(content)
# 取出资料的前6个,她的空间这个栏目不要
tr_list = html.xpath('//div[@class="infodiv"]//tbody/tr[position()<6]')
info = ""
for tr in tr_list:
info += " ".join(tr.xpath('./td/text()')) # 把每个取出来的列表拼接成字符串
info += "\n"
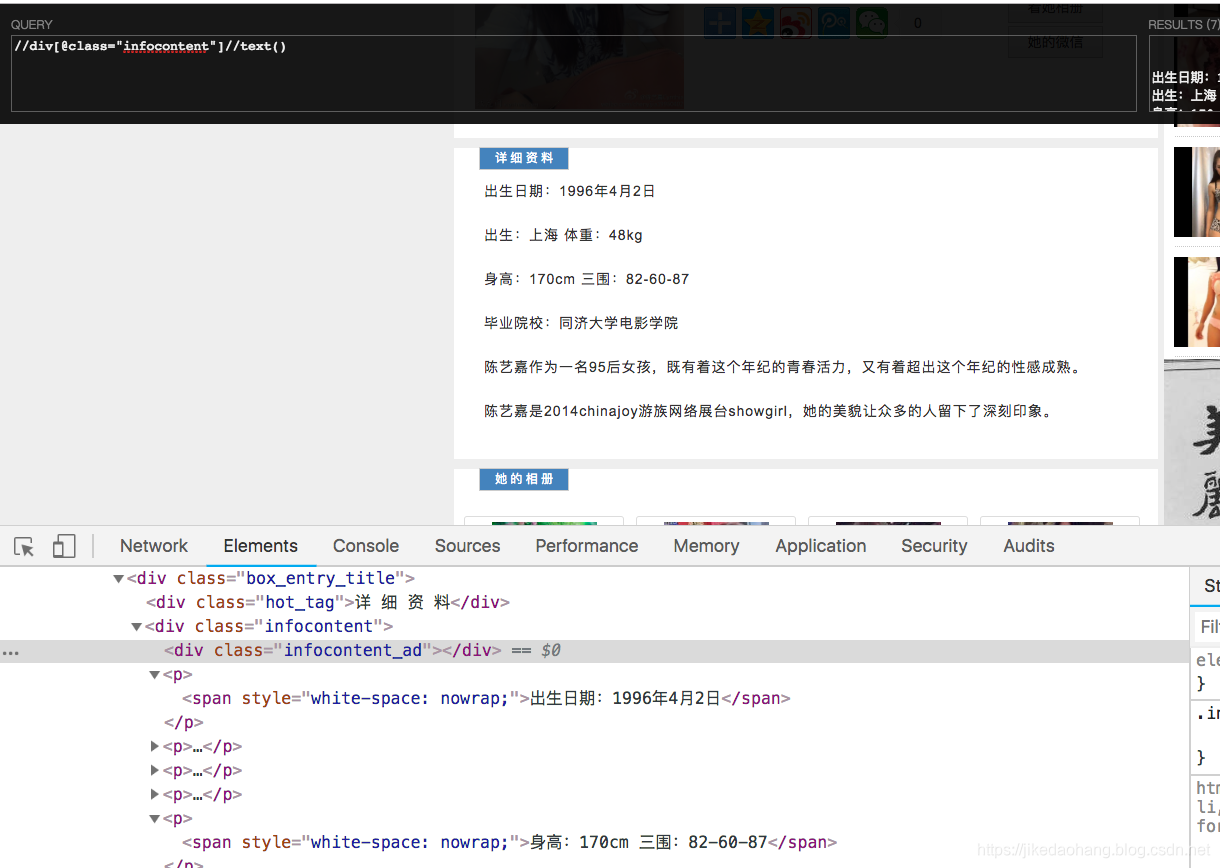
# 取出详细资料。注意的有点资料会有空的,做判空处理
content = html.xpath('//div[@class="infocontent"]//text()')
if content: # 假如不为空
content = "".join(content) # 把详细资料拼接成字符串
# 校花空间地址
more = html.xpath('//span[@class="archive_more"]/a/@href')[0]
print(info)
print(content)
print(more)
if __name__ == "__main__":
xhs = XHSpider()
xhs.loadpage()
#打印
姓 名: 李玮
年 龄:
星 座:
专 业:
学 校: 河北司法警官职业学院
你不知道,当你半夜躲过督察偷偷在宿舍玩手机的怎样的兴奋快感;你不知道,当你只没有学校的命令,天冷了不能穿高领,只能穿作训,天热了不能脱是什么感觉; 你不知道校规,每天把牙膏盒吹胀是什么感觉; 你不知道,为了学校严格规定,每天不吃饭也要压去了,三、四年就这样结束了……可正因为这样,我疯狂的爱上了它,不知疲倦!
http://www.xiaohuar.com/s-1-2029.html
六、高清大图
这个页面我们最重要的就是把高清大图的链接找到,链接加上域名就是完整的大图地址。
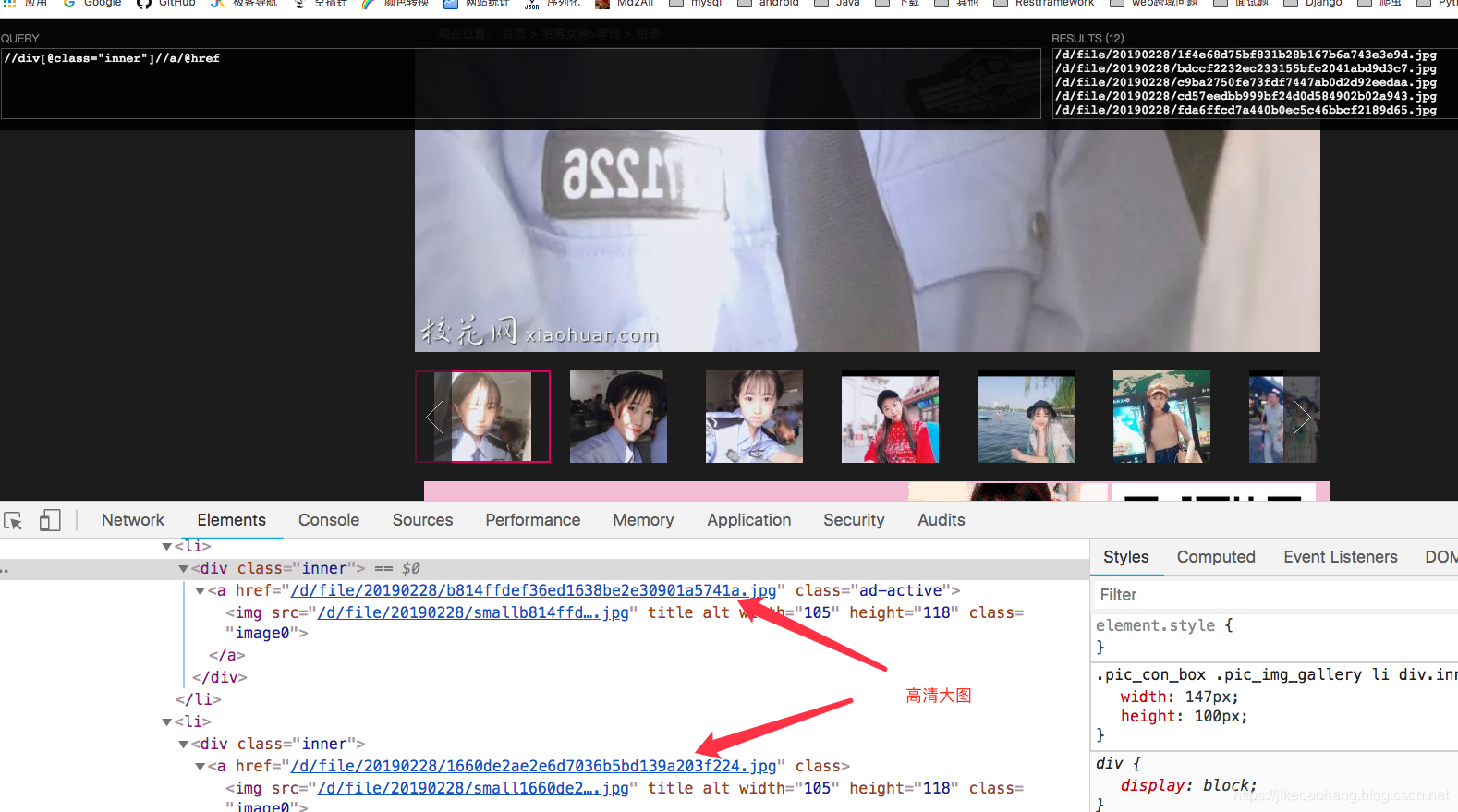
在爬的过程中,我们发现有的图片是以Http开头,有的不是,并且的有是错误的图片地址,所有我们需要做容错处理。
import requests
from lxml import etree
import os
class XHSpider():
def __init__(self):
# 默认第一页开始
self.pn = 0
# 默认URL
self.url = 'http://www.xiaohuar.com/list-1-{0}.html'
# 添加请求头,模拟浏览器
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
# 发起请求
def loadpage(self):
# 拼接请求地址
req_url = self.url.format(self.pn) # http://www.xiaohuar.com/list-1-0.html
print(req_url)
# 发起请求
reponse = requests.get(url=req_url, headers=self.headers)
# 取返回的内容
content = reponse.text
'''
注意:如果发现用xpath插件在浏览器上能取到标签,但是在代码里面取不到
最好把请求下来的源代码保存到代码,分析一下为什么取不到,有时候
浏览器里面的源代码跟你在代码里面请求的源码可能稍微不一样。
'''
with open('xiaohua.html', 'w') as f:
f.write(content)
# 构造xpath解析对象
html = etree.HTML(content)
# 先取出这个页面所有div标签
div_list = html.xpath('//div[contains(@class,"masonry_brick")]')
for div in div_list:
# 从从每个div标签取出详情页链接 .代表当前位置
desc_url = div.xpath('.//div[@class="img"]//a/@href')[0]
# 标题
img_title = div.xpath('.//div[@class="img"]//img/@alt')[0]
# 封面图片地址
img_url = div.xpath('.//div[@class="img"]//img/@src')[0]
print(desc_url)
self.loaddescpage(desc_url)
# 详情页
def loaddescpage(self, desc_url):
# 发起请求
reponse = requests.get(url=desc_url, headers=self.headers)
# 取返回的内容
content = reponse.text
# 构造xpath解析对象
html = etree.HTML(content)
# 取出资料的前6个,她的空间这个栏目不要
tr_list = html.xpath('//div[@class="infodiv"]//tbody/tr[position()<6]')
info = ""
for tr in tr_list:
info += " ".join(tr.xpath('./td/text()')) # 把每个取出来的列表拼接成字符串
info += "\n"
# 取出详细资料。注意的有点资料会有空的,做判空处理
content = html.xpath('//div[@class="infocontent"]//text()')
if content: # 假如不为空
content = "".join(content) # 把详细资料拼接成字符串
# 校花空间地址
more = html.xpath('//span[@class="archive_more"]/a/@href')[0]
print(info)
print(content)
print(more)
self.loadzone(more)
# 校花空间提取
def loadzone(self, more):
# 发起请求
reponse = requests.get(url=more, headers=self.headers)
# 取返回的内容
content = reponse.text
# 构造xpath解析对象
html = etree.HTML(content)
#取图片的地址列表
big_imgs = html.xpath('//div[@class="inner"]//a/@href')
#做图片地址容错处理
for big_img in big_imgs:
if big_img.startswith('http') or big_img.endswith('.jpg'):
if big_img.startswith('http'):
self.download(big_img)
else:
self.download("http://www.xiaohuar.com" + big_img)
# 图片下载
def download(self, big_img):
print('正在下载', big_img)
# 发起请求
reponse = requests.get(url=big_img, headers=self.headers)
#读取二进制内容
content = reponse.content
#保存到本地
with open(big_img[-20::],'wb') as f:
f.write(content)
if __name__ == "__main__":
xhs = XHSpider()
xhs.loadpage()
先暂时下载一些,为了九牛二虎之力,终于可以看到点比较喜欢的校花了。先来预览一张高清大图吧

还不错。但是我们需要重新整理一下代码,我们根据校花的名字创建文件夹,然后把校花的资料、详细信息、空间相册的图片全下载进去。方便我们以后管理。又到我们考虑问题的时候了
- 文件夹的命名
我们在首页提取的标题字段可以做文件夹的名字 - 图片的名字
图片的名字可以拿图片地址后多少位进行命名 - 个人信息命名
个人信息的名字也可以拿首页的标题
那么开始实现吧,在每个函数实现创建文件夹的操作。还是实现多页下载。
全部代码:
import requests
from lxml import etree
import os
class XHSpider():
def __init__(self):
# 默认第一页开始
self.pn = 0
# 默认URL
self.url = 'http://www.xiaohuar.com/list-1-{0}.html'
# 目录
self.dir = '校花/'
#刚开始就创建一个目录
if not os.path.exists(self.dir): # 如果文件夹不存在
os.mkdir(self.dir) # 创建文件夹
# 添加请求头,模拟浏览器
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
# 发起请求
def loadpage(self):
# 拼接请求地址
req_url = self.url.format(self.pn) # http://www.xiaohuar.com/list-1-0.html
print(req_url)
# 发起请求
reponse = requests.get(url=req_url, headers=self.headers)
# 取返回的内容
content = reponse.text
'''
注意:如果发现用xpath插件在浏览器上能取到标签,但是在代码里面取不到
最好把请求下来的源代码保存到代码,分析一下为什么取不到,有时候
浏览器里面的源代码跟你在代码里面请求的源码可能稍微不一样。
'''
with open('xiaohua.html', 'w') as f:
f.write(content)
# 构造xpath解析对象
html = etree.HTML(content)
# 先取出这个页面所有div标签
div_list = html.xpath('//div[contains(@class,"masonry_brick")]')
for div in div_list:
# 从从每个div标签取出详情页链接 .代表当前位置
desc_url = div.xpath('.//div[@class="img"]//a/@href')[0]
# 标题
img_title = div.xpath('.//div[@class="img"]//img/@alt')[0]
# 封面图片地址、这个地址好像没用。发现相册里面有这种图片
img_url = div.xpath('.//div[@class="img"]//img/@src')[0]
print(desc_url)
#创建每个校花的文件夹
folder = self.dir + img_title
if not os.path.exists(folder): # 如果文件夹不存在
os.mkdir(folder) # 创建文件夹
#开始请求详情页,把标题传过去,后面有用
self.loaddescpage(desc_url, img_title)
# 详情页
def loaddescpage(self, desc_url, img_title):
# 发起请求
reponse = requests.get(url=desc_url, headers=self.headers)
# 取返回的内容
content = reponse.text
# 构造xpath解析对象
html = etree.HTML(content)
# 取出资料的前6个,她的空间这个栏目不要
tr_list = html.xpath('//div[@class="infodiv"]//tbody/tr[position()<6]')
info = ""
for tr in tr_list:
info += " ".join(tr.xpath('./td/text()')) # 把每个取出来的列表拼接成字符串
info += "\n"
# 取出详细资料。注意的有点资料会有空的,做判空处理
content = html.xpath('//div[@class="infocontent"]//text()')
if content: # 假如不为空
content = "".join(content) # 把详细资料拼接成字符串
# 校花空间地址
more = html.xpath('//span[@class="archive_more"]/a/@href')[0]
print(info)
print(content)
print(more)
# 个人信息
info_dir = self.dir + img_title + "/" + img_title + "个人信息.txt"
with open(info_dir, 'w') as f:
f.write(info)
f.write(content)
#开始请求校花空间
self.loadzone(more, img_title)
# 校花空间提取
def loadzone(self, more, img_title):
# 发起请求
reponse = requests.get(url=more, headers=self.headers)
# 取返回的内容
content = reponse.text
# 构造xpath解析对象
html = etree.HTML(content)
# 取图片的地址列表
big_imgs = html.xpath('//div[@class="inner"]//a/@href')
# 做图片地址容错处理
for big_img in big_imgs:
if big_img.startswith('http') or big_img.endswith('.jpg'):
if big_img.startswith('http'):
self.download(big_img, img_title)
else:
self.download("http://www.xiaohuar.com" + big_img, img_title)
# 图片下载
def download(self, big_img, img_title):
print('正在下载', big_img)
# 发起请求
reponse = requests.get(url=big_img, headers=self.headers)
# 读取二进制内容
content = reponse.content
#图片地址
img_dir = self.dir + img_title + "/" + big_img[-20::]
# 保存到本地
with open(img_dir, 'wb') as f:
f.write(content)
if __name__ == "__main__":
xhs = XHSpider()
#这正确的逻辑应该自动提取下一页,然后自动加载,不过数据量不大。可以简单通过循环提取。
for i in range(0, 44):
print('爬取第%d页' % i)
xhs.pn = i # 把每页赋值给pn
xhs.loadpage()
最终我们在本地看到有如下的文件夹:
我只爬取了第一页,大家有兴趣的可以多爬取几页。还有一个问题,大家可以自己处理,就是把代码简单的封装一下,比如发起网络请求可以单独封装一个方法。
七、总结
我们又通过一个例子,对爬虫有了一定的理解,在爬取的过程还是会遇到很多问题的,有些问题我们可能前期就能想到,而有的问题可能在运行代码的时候才会发现。不过既然是问题,就有解决办法。所有在打算爬取一个网站的时候,还要简单分析:
- 我们要提取哪些信息
- 网页地址的URL变化
- 信息应该在哪个页面提取,有的页面信息重复
- 多爬取一些信息,每个网页的结构可能不一样
- 请求的网站源代码跟浏览器里面的源代码是否有区别(以请求下来的源码为准)
好了,反正不管如何,我们把校花图片爬下来了,妈妈在也不会担心我们不给她发女朋友的照片了。
- 此项目仅供学习,请勿用于商业用途
- 源码
欢迎关注我的公众号,我们一起学习。
