版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u011310942/article/details/88257205
本文同步发表于我的微信公众号,扫一扫文章底部的二维码或在微信搜索 极客导航 即可关注,每个工作日都有文章更新。
一、概况
前两篇我们把网络库Requests大概的用法学了一遍,把网站上的每页数据请求下来是爬虫的第一步,接下来我们就需要把每页上对我们有用数据进行提取。提取数据的方式有很多,比如说正则、xpath、bs4等,我们今天就来学一下xpath的语法。
二、Xpath
- 什么是xpath?
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。 - 什么是xml?W3School
- XML 指可扩展标记语言(EXtensible Markup Language)
- XML 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
- XML 标签没有被预定义。您需要自行定义标签。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准
- XML和 HTML 的区别
| 数据格式 | 描述 | 作用 |
|---|---|---|
| XML | 可扩展标记语言 | 用来传输和存储数据 |
| HTML | 超文本标记语言 | 用来显示数据 |
三、准备
pip3 install lxml
四、用法
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
| 表达式 | 含义 |
|---|---|
| / | 从根节点开始 |
| // | 从任意节点 |
| . | 从当前节点 |
| … | 从当前节点的父节点 |
| @ | 选取属性 |
| text() | 选取文本 |
案例
from lxml import etree
data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1" id="1" ><a href="link4.html">fourth item</a></li>
<li class="item-0" data="2"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html = etree.HTML(data)#构造了一个XPath解析对象。etree.HTML模块可以自动修正HTML文本。
li_list = html.xpath('//ul/li')#选取ul下面的所有li节点
#li_list = html.xpath('//div/ul/li')#选取ul下面的所有li节点
a_list = html.xpath('//ul/li/a')#选取ul下面的所有a节点
herf_list = html.xpath('//ul/li/a/@href')#选取ul下面的所有a节点的属性herf的值
text_list = html.xpath('//ul/li/a/text()')#选取ul下面的所有a节点的值
print(li_list)
print(a_list)
print(herf_list)
print(text_list)
#打印
[<Element li at 0x1015f4c48>, <Element li at 0x1015f4c08>, <Element li at 0x1015f4d08>, <Element li at 0x1015f4d48>, <Element li at 0x1015f4d88>]
[<Element a at 0x1015f4dc8>, <Element a at 0x1015f4e08>, <Element a at 0x1015f4e48>, <Element a at 0x1015f4e88>, <Element a at 0x1015f4ec8>]
['link1.html', 'link2.html', 'link3.html', 'link4.html', 'link5.html']
['first item', 'second item', 'third item', 'fourth item', 'fifth item']
我们发现最后打印的值都是一个列表对象,如果想取值就可以遍历列表了。
选取未知节点 XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 含义 |
|---|---|
| * | 选取任何元素节点 |
| @* | 选取任何属性的节点 |
案例
from lxml import etree
data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1" id="1" ><a href="link4.html">fourth item</a></li>
<li class="item-0" data="2"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html = etree.HTML(data)
li_list = html.xpath('//li[@class="item-0"]')#选取class为item-0的li标签
text_list = html.xpath('//li[@class="item-0"]/a/text()')#选取class为item-0的li标签 下面a标签的值
li1_list = html.xpath('//li[@id="1"]')#选取id属性为1的li标签
li2_list = html.xpath('//li[@data="2"]')#选取data属性为2的li标签
print(li_list)
print(text_list)
print(li1_list)
print(li2_list)
#打印
[<Element li at 0x101dd4cc8>, <Element li at 0x101dd4c88>]
['first item', 'fifth item']
[<Element li at 0x101dd4d88>]
[<Element li at 0x101dd4c88>]
谓语的一些路径表达式
| 表达式 | 含义 |
|---|---|
| [?] | 选取第几个节点 |
| last() | 选取最后一个节点 |
| last()-1 | 选取倒数第二个节点 |
| position()-1 | 选取前两个 |
案例
from lxml import etree
data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1" id="1" ><a href="link4.html">fourth item</a></li>
<li class="item-0" data="2"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html = etree.HTML(data)
li_list = html.xpath('//ul/li[1]') # 选取ul下面的第一个li节点
li1_list = html.xpath('//ul/li[last()]') # 选取ul下面的最后一个li节点
li2_list = html.xpath('//ul/li[last()-1]') # 选取ul下面的最后一个li节点
li3_list = html.xpath('//ul/li[position()<= 3]') # 选取ul下面前3个标签
text_list = html.xpath('//ul/li[position()<= 3]/a/@href') # 选取ul下面前3个标签的里面的a标签里面的href的值
print(li_list)
print(li1_list)
print(li2_list)
print(li3_list)
print(text_list)
#打印
[<Element li at 0x1015d3cc8>]
[<Element li at 0x1015d3c88>]
[<Element li at 0x1015d3d88>]
[<Element li at 0x1015d3cc8>, <Element li at 0x1015d3dc8>, <Element li at 0x1015d3e08>]
['link1.html', 'link2.html', 'link3.html']
五、函数
| 表达式 | 含义 |
|---|---|
| starts-with | 选取以什么开头的元素 |
| contains | 选取包含一些信息的元素 |
| and | 并且的关系 |
| or | 或者的关系 |
案例
from lxml import etree
data = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1" id="1" ><a href="link4.html">fourth item</a></li>
<li class="item-0" data="2"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html = etree.HTML(data)
li_list = html.xpath('//li[starts-with(@class,"item-1")]')#获取class包含以item-1开头的li标签
li1_list = html.xpath('//li[contains(@class,"item-1")]')#获取class包含item的li标签
li2_list = html.xpath('//li[contains(@class,"item-0") and contains(@data,"2")]')#获取class为item-0并且data为2的li标签
li3_list = html.xpath('//li[contains(@class,"item-1") or contains(@data,"2")]')#获取class为item-1或者data为2的li标签
print(li_list)
print(li1_list)
print(li2_list)
print(li3_list)
#打印
[<Element li at 0x101dcac08>, <Element li at 0x101dcabc8>]
[<Element li at 0x101dcac08>, <Element li at 0x101dcabc8>]
[<Element li at 0x101dcacc8>]
[<Element li at 0x101dcac08>, <Element li at 0x101dcabc8>, <Element li at 0x101dcacc8>]
以上是Xpath一些常用用法,如果想了解更多的语法可以参考W3School
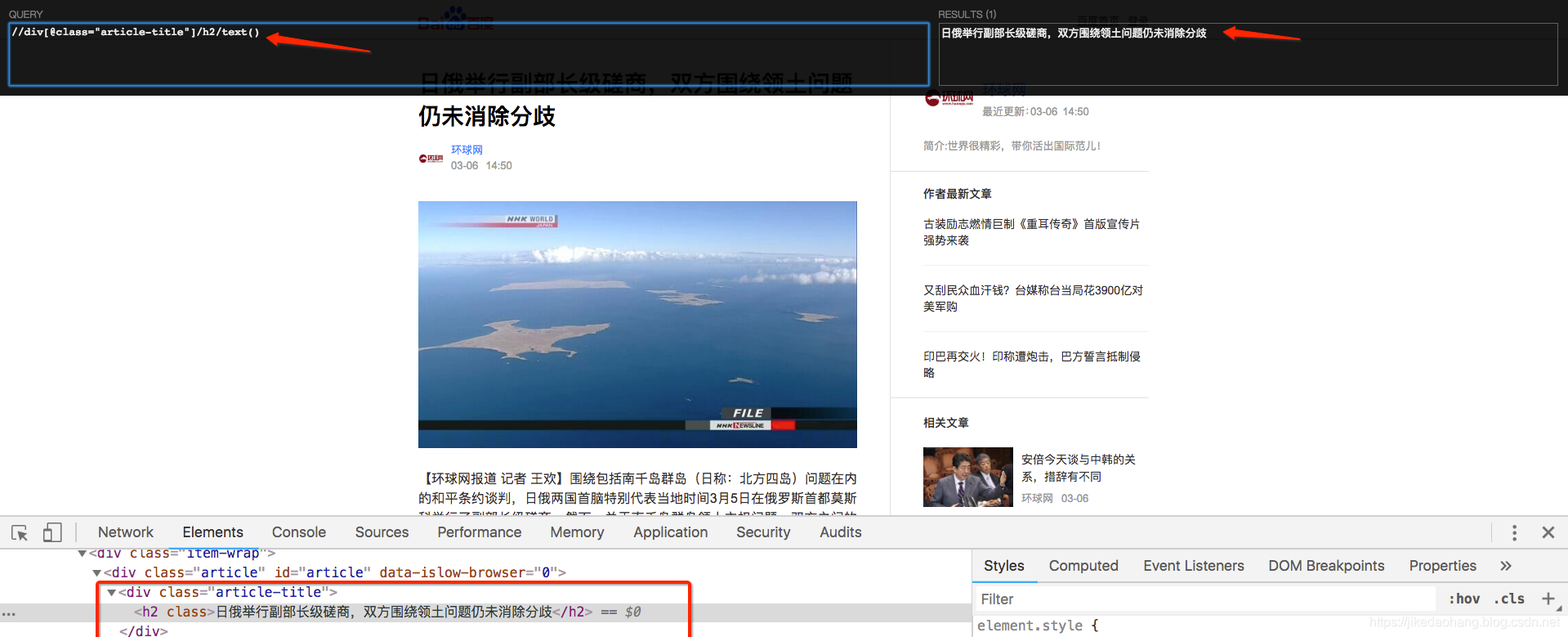
六、浏览器插件
我们可以在浏览器安装一些xpath插件,方便我们进行解析数据。
- Chrome插件 XPath Helper
- Firefox插件 XPath Checker
去浏览器扩展下载这些插件,会在浏览器左上角看到图标,如下

大概使用方法:
七、总结
我们把网络库、解析库,接下来我们就可以开始真正的爬虫之旅,后续的文章打算用Requests和Xpath爬取几个网站。
欢迎关注我的公众号,我们一起学习。
