本文同步发表于我的微信公众号,扫一扫文章底部的二维码或在微信搜索 极客导航 即可关注,每个工作日都有文章更新。
一、概况
接着上篇说,如果你真以为Requests网络请求库只有Get请求和Post请求,那就大错特错了。它还一些其他用法,也是爬虫经常需要的,我们一起来看看吧。

二、使用
- Auth验证
不知道小伙伴配置过刚买的路由器没有,刚配置的要进入后台一般都需要浏览器的Auth验证,需要输入用户名和密码,它的原理就是将用户名:密码base64加密后放在http的请求头部,然后发送给后台进行验证。我们的Requests也必然支持这种操作,不过用的相对较少。
import requests
auth=('admin', 'admin')
response = requests.get(
'http://192.168.1.1',
auth = auth
)
print (response.text)
- 代理
使用http或https代理,可能是我们解决反爬比较重要的一个环节。代理是什么?看图:
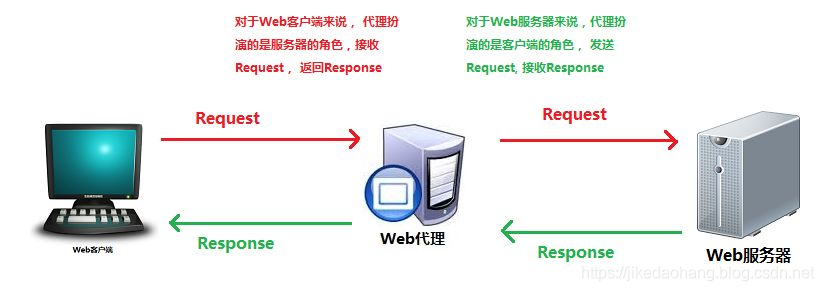
当我们的IP被封时,我们往往会采用代理。相当于我喜欢一个女孩,但是她把我拉入黑名单了,这个时候往往会找她的闺蜜进行操作,我要把对女孩说的话跟她闺蜜说,然后让闺蜜转交给她。闺蜜在把她对我说的话返回给我。如果这个闺蜜也被她拉入黑名单,我们在换一个她的闺蜜。理论上一般我们都会采用闺蜜池,也就是我们所说的IP代理池。需要钱呀!!!!
import requests
# 根据协议类型,选择不同的代理
proxies = {
"http": "http://12.34.56.79:9527",
"https": "http://12.34.56.79:9527",
}
response = requests.get(
"http://www.baidu.com",
proxies = proxies
)
print(response.text)
私密代理:
import requests
# 如果代理需要使用HTTP Basic Auth,可以使用下面这种格式:
proxy = {
"http": "name:[email protected]:11163"
}
response = requests.get(
"http://www.baidu.com",
proxies = proxy
)
print (response.text)
目前市场有很多免费代理和付费代理。比如西次代理、快代理等~
- Cookies
使用python的requests开发爬虫类程序时,经常需要将之前请求返回的set-cookie值,作为下一个请求的cookie发送。比如模拟登录之后的返回的sessionId,就需要作为后续请求的cookie参数。
import requests
response = requests.get("http://www.baidu.com/")
# 返回CookieJar对象:
cookiejar = response.cookies
#打印cookiejar
print (cookiejar)
#下一次访问带上 上一次的cookies
response = requests.get("http://www.baidu.com/", cookies=cookie_jar)
#打印响应内容
print (response.text)
- Session
在 requests里,session是一个比较强大的对象,这个对象代表一次用户会话:从客户端浏览器连接服务器开始,到客户端浏览器与服务器断开,
会话能让我们在跨请求时候保持某些参数。比如在同一个 Session 实例发出的所有请求之间保持 cookie 。
import requests
# 创建session对象,可以保存Cookie值
session = requests.session()
# 添加请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"
}
# post参数
data = {
"email":"xxxx",
"password":"xxxx"
}
# 发送附带用户名和密码的请求,并获取登录后的Cookie值,保存在session里
session.post(
"http://www.jikedaohang.com/login",
data = data
)
# session包含用户登录后的Cookie值,可以直接访问那些登录后才可以访问的页面。
# 比如个人中心页面
response = session.get(
"http://www.jikedaohang.com/1562336754/profile"
)
# 打印响应内容
print (response.text)
- 处理HTTPS请求(SSL证书验证)
在想处理这块知识点,我们需要了解一些东西:
- SSL:安全套接字层。是为了解决HTTP协议是明文,避免传输的数据被窃取,篡改,劫持等。
- TSL:Transport Layer Security,传输层安全协议。TSL其实是SSL标准化后的产物,即SSL/TSL
- HTTPS在传输数据时,会先建立TCP连接,建立起TCP连接后,会建立TSL连接。
- 请求可以为HTTPS请求验证SSL证书,就像web浏览器一样,SSL验证默认是开启的,
如果证书验证失败,请求会抛出SSLError:
SSLError: ("bad handshake: Error([('SSL routines', 'ssl3_get_server_certificate', 'certificate verify failed')],)",)
遇到请求的SSL验证,可以直接跳过不验证,将verify=False设置一下即可。
import requests
response = requests.get("https://www.12306.cn/mormhweb/", verify = False)
print (response.text)
如果验证,那么verify参数可以是传入CA_BUNDLE文件的路径或传入包含可信任CA证书的文件夹路径
import requests
response = requests.get("https://www.12306.cn/mormhweb/", verify = './certfile')
print (response.text)
结果:
1.HTTPS请求进行SSL验证或忽略SSL验证才能请求成功,忽略方式为verify=False。
2.SSL证书是由CA机构颁发的,是需要花钱的。
三、总结
requests网络请求库,暂时我们就写到这里。下面我们会继续学习解析库的学习。
欢迎关注我的公众号,我们一起学习。
