一、逻辑回归
逻辑回归也称作logistic回归分析,是一种广义的线性回归分析模型,属于机器学习中的监督学习。其推导过程与计算方式类似于回归的过程,但实际上主要是用来解决二分类问题(也可以解决多分类问题)。通过给定的n组数据(训练集)来训练模型,并在训练结束后对给定的一组或多组数据(测试集)进行分类。
二、算法原理介绍
逻辑回归,是一种“回归”的线性分类器,其本质是由线性回归变化而来的,一种广泛应用于分类问题中的回归算法。我们都知道线性回归是预测连续性标签值,计算方法如下:
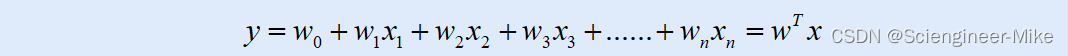
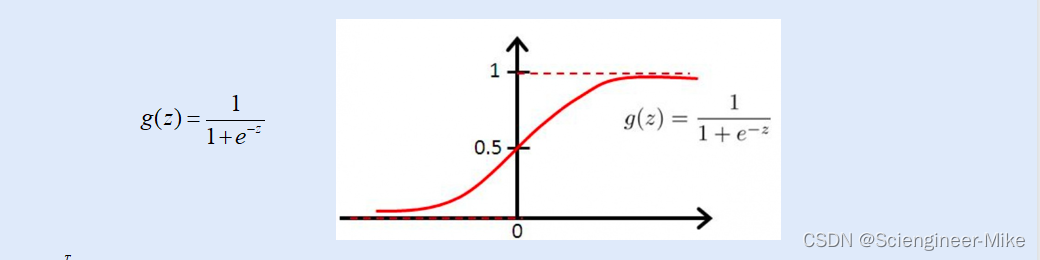
通过函数y,线性回归使用输入的特征矩阵x来输出一组连续的标签值y_pred,以完成连续性变量的预测(比如预测产品销量,预测股价等等)。那如果我们的标签量是离散型变量,尤其是,如果满足0-1分布的离散型变量,我们要该怎么办呢?我们可以通过引入“联系函数”,见连续性变量转换为离散型变量。而逻辑回归的“联系函数”为sigmoid函数。sigmoid函数当x趋于负无穷时,函数值趋近于0;当x趋于正无穷时,函数值趋近于1。很好的将连续性变量映射到0-1之间。
通过线性回归函数和sigmoid函数,可以得到如下:
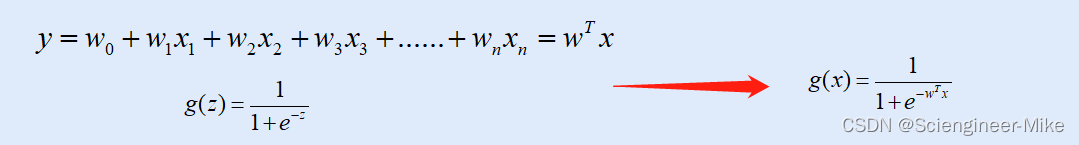
通过以上,可以很容易得到以下的等式(g(x)和1-g(x)分别为0和1对应的概率):
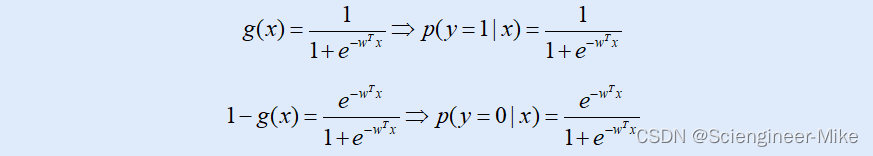
得到了对应标签值的概率值,借助log距离作为逻辑回归的损失函数,损失函数具体结果可以写作:
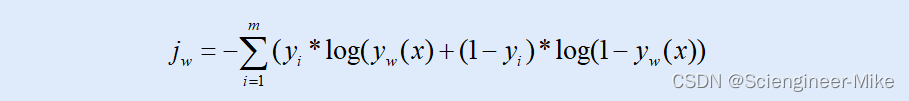
为此,求损失函数的极小值对应的参数w,即是我们要求的结果。原理介绍到这里,接下来,我们通过代码实现逻辑回归分类。
三、代码实现
3.1 sklearn-API介绍
正则化是用来防止过拟合的过程。sklearn中的逻辑回归API也通过正则化来防止模型过拟合。常用的由L1正则化和L2正则化两种选项。分别通过在损失函数后面加上参数w的L1范式和L2范式。如下:
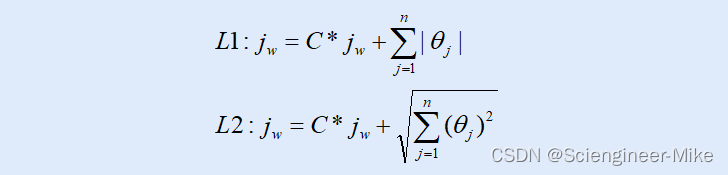
class sklearn.linear_model.LogisticRegression(penalty=‘l2’, *, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver=‘lbfgs’, max_iter=100, multi_class=‘auto’, verbose=0, warm_start=False, n_jobs=None, l1_ratio=None)
重要参数:
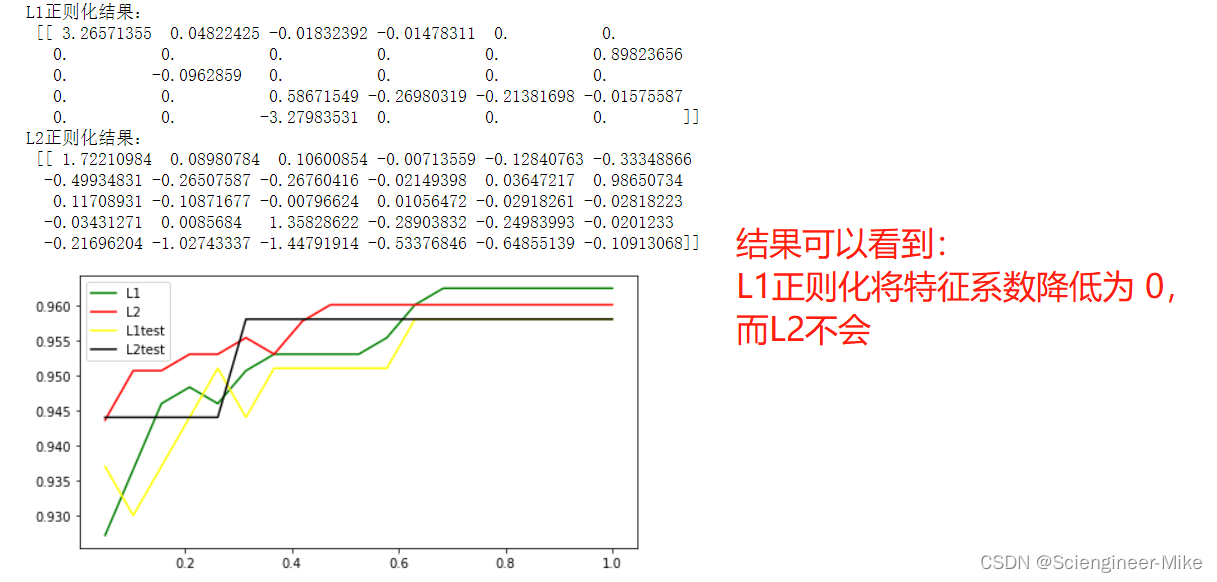
penalty:选择L1或L2来指定正则化方式,默认L2。注意L1正则化会将w参数压缩为0。
C:正则化强度的倒数,默认1.0,即默认正则化和损失函数的比值为1。C越小,损失函数越小,模型对损失函数的惩罚越重,正则化效力越强。
max_iter:逻辑回归是采用梯度下降法求取最优参数的w,该值为迭代的次数,默认100。
solver:求解器对应求解方式。
class_weght:通过赋予权重解决样本不平衡的问题。
3.2 sklearn-代码实现
我们将sklearn自带数据集load_breast_cancer,作为我们的分析数据进行建模学习,代码如下
# 导入需要的包
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# load dataset
X,y =load_breast_cancer(return_X_y=True)
# 划分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=0)
# build model
l1,l2,l1test,l2test = [],[],[],[]
for i in np.linspace(0.05,1,19):
lrl1 = LogisticRegression(penalty="l1",solver="liblinear",C=i,max_iter=1000)
lrl2 = LogisticRegression(penalty="l2",solver="liblinear",C=i,max_iter=1000)
lrl1 = lrl1.fit(X_train,y_train)
l1.append(accuracy_score(lrl1.predict(X_train),y_train))
l1test.append(accuracy_score(lrl1.predict(X_test),y_test))
lrl2 = lrl2.fit(X_train,y_train)
l2.append(accuracy_score(lrl2.predict(X_train),y_train))
l2test.append(accuracy_score(lrl2.predict(X_test),y_test))
print("L1正则化结果:\n",lrl1.coef_,"\nL2正则化结果:\n",lrl2.coef_)
result = [l1,l2,l1test,l2test]
color = ["green","red","yellow","black"]
label = ["L1","L2","L1test","L2test"]
# 结果展示
plt.figure(figsize=(8,4))
for i in range(4):
plt.plot(np.linspace(0.05,1,19),result[i],color[i],label=label[i])
plt.legend()
plt.show()
结果展示:
3.3 python手写代码实现
代码如下:
import numpy as np
from sklearn.datasets import load_breast_cancer
# 创建一个类
class LogisticRegression():
#初始化参数
def __init__(self,X,y,num_iter,learning_rate):
self.X = X
self.y = y
self.num_iter = num_iter
self.learning_rate = learning_rate
# sigmod函数,即得分函数,
def sigmoid(self,x):
return 1 / (1 + np.exp(-x))
# 定义损失函数的计算方式
def cost(self,x,y):
return -y * np.log(x) - (1-y) * np.log(1 - x)
# 梯度下降的实现
def gradient(self,current_para,X,y):
sample_gradient = np.zeros(X.shape[1])
for i in range(X.shape[0]):
current_X = X[i]
current_y = y[i]
current_x = np.asarray(current_X)
sample_gradient += (self.sigmoid(np.dot(current_para, current_X)) - current_y) * current_X
new_para = current_para - self.learning_rate * sample_gradient
return new_para
# 误差计算
def caculate_error(self,para, X, y):
sample_error = 0
for i in range(X.shape[0]):
current_X = X[i]
current_y = y[i]
xx = self.sigmod(np.dot(para, current_X)) # LR算法
if cost(xx, current_y) > 0.5: # 进一步计算损失
sample_error += 1
return sample_error / X.shape[0]
# 训练
def train(self,initial_para):
X = np.asarray(self.X)
y = np.asarray(self.y)
para = initial_para
for i in range(self.num_iter + 1):
para = self.gradient(para, X, y) # 梯度下降法
return para
# 逻辑回归
def logistic(self):
initial_para = np.ones(self.X.shape[1])# 初始系数为1
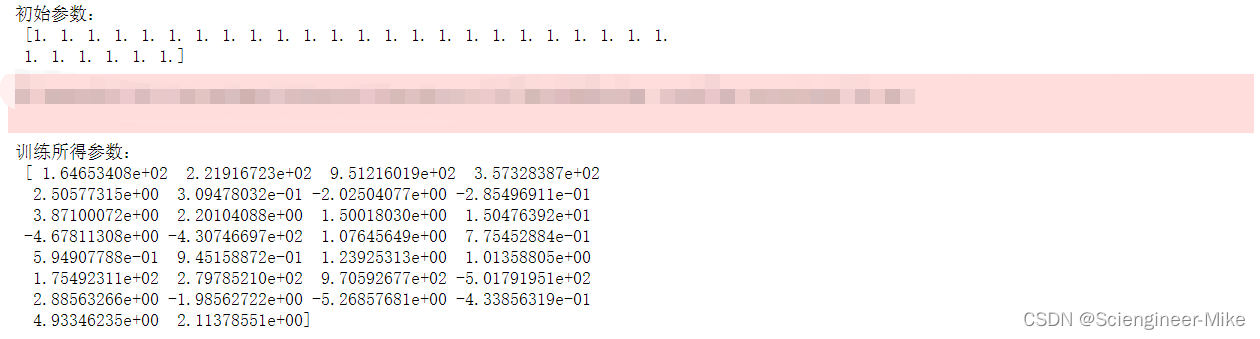
print("初始参数:\n", initial_para)
para = self.train(initial_para)
print("训练所得参数:\n", para)
return para
# 输入数据和定义参数
X,y =load_breast_cancer(return_X_y=True)
learning_rate = 0.001 #学习率为0.001
num_iter = 1000 # 训练步数
# 实例化,开启训练
LR = LogisticRegression(X,y,num_iter=num_iter,learning_rate=learning_rate)
result_para = LR.logistic()
结果展示:
通过以上训练,我们得到了模型的参数W。下面将其带入模型,验证原始数据的准确率。
如下:
from sklearn.metrics import accuracy_score
# 通过所得模型参数获取预测值
test_result = []
for i in range((X.shape[0])):
if np.dot(X[i],result_para)>0: # w*x=预测值
result = 1
else:
result = 0
test_result.append(result)
#计算准确率
accuracy_score(y,test_result)

四、总结
逻辑回归是工作中使用最广泛的算法之一,主要是因为结构简单(通过本篇介绍了逻辑回归实现原理,模型的损失函数如何获取就可以看出),实现简单,可解释性强,从特征的权重可以看到不同特征对最后结果的影响,并且训练快,训练时间取决于特征数目的大小,且输出结果为概率,可以很好的利用概率值进行分类。希望对大家有所帮助。
五、算法系列
链接: 【机器学习之集成算法】RandomForest和XGboost原理介绍与代码实现
链接: 【机器学习之特征工程】数据预处理、特征选择、降维及不平衡处理
链接: 【机器学习之聚类算法】KMeans原理及代码实现
链接: 【机器学习之线性回归】多元线性回归模型的搭建+Lasso回归的特征提取
链接: 【机器学习之决策树】决策树原理介绍及代码实现sklearn