06丨链表(上):如何实现LRU缓存淘汰算法
常用的缓存淘汰策略有三种:先进先出策略FIFO(First In, First Out)、最少使用策略(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)。(清理书籍例子帮助记忆)
链表及链表结构
数组和链表的对比
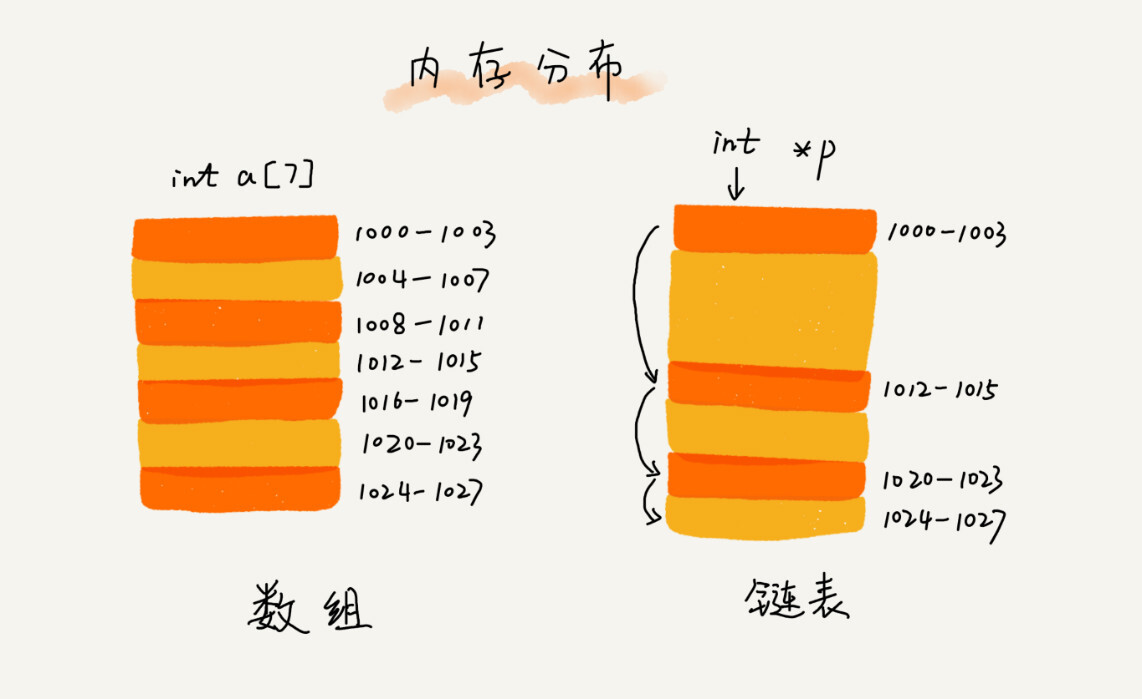
数组需要一组连续的内存空间来存储,链表不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用。我们把内存块称为链表的“结点”。每个结点包括用户自定义的数据和下一个节点的地址(指针)。
性能对比
单链表
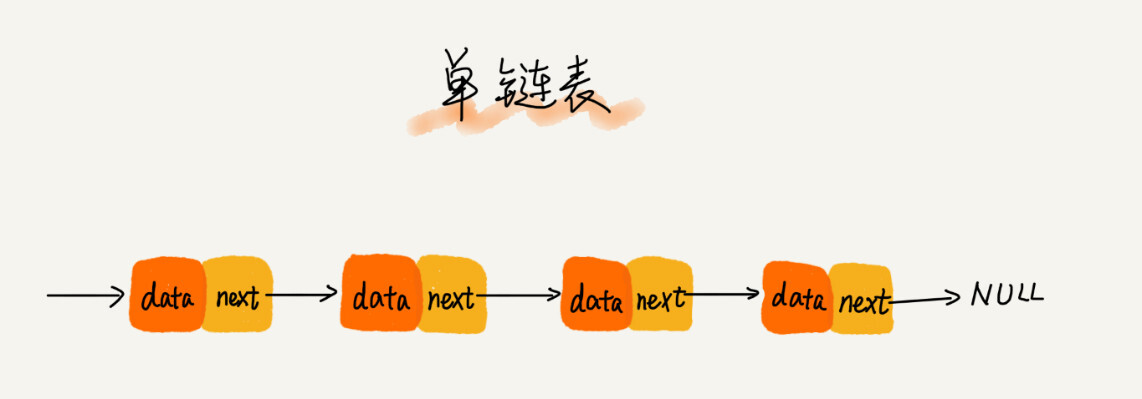
单链表只有一个后继指针next。第一个节点叫头结点,用来记录链表的基地址。最后一个节点叫尾结点,尾结点的指针不是指向下一个节点,而是指向一个空地址NULL,表示这是链表上的最后一个节点。
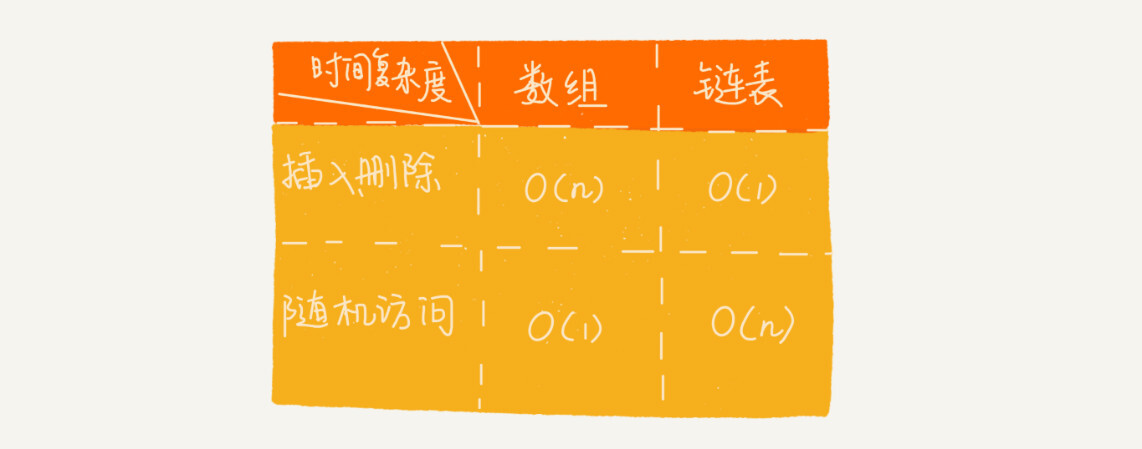
插入、删除时间复杂度为O(1)。
但是链表随机访问时只能一个一个遍历,时间复杂度为O(n)。
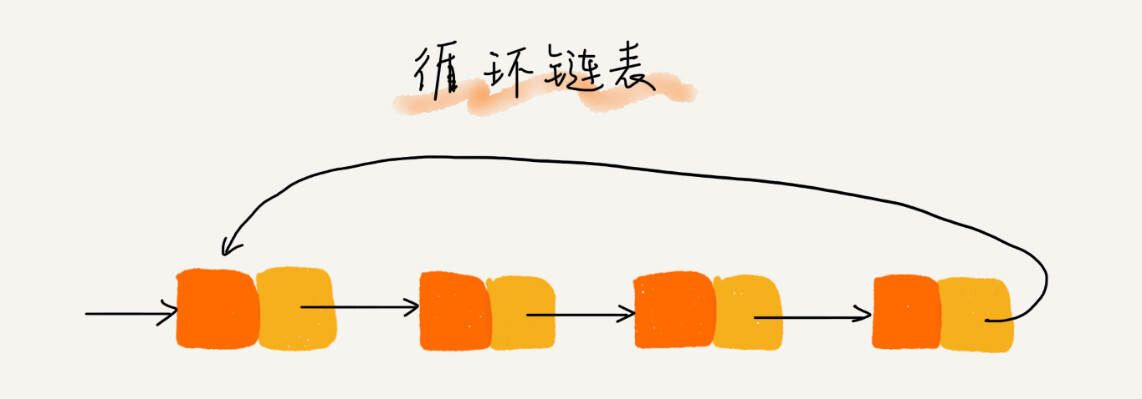
循环链表
循环链表是一种特殊的单链表,它的尾结点指针指向链表的头结点。当要处理的数据具有环形结构的特点时,适合使用循环链表。
双向链表
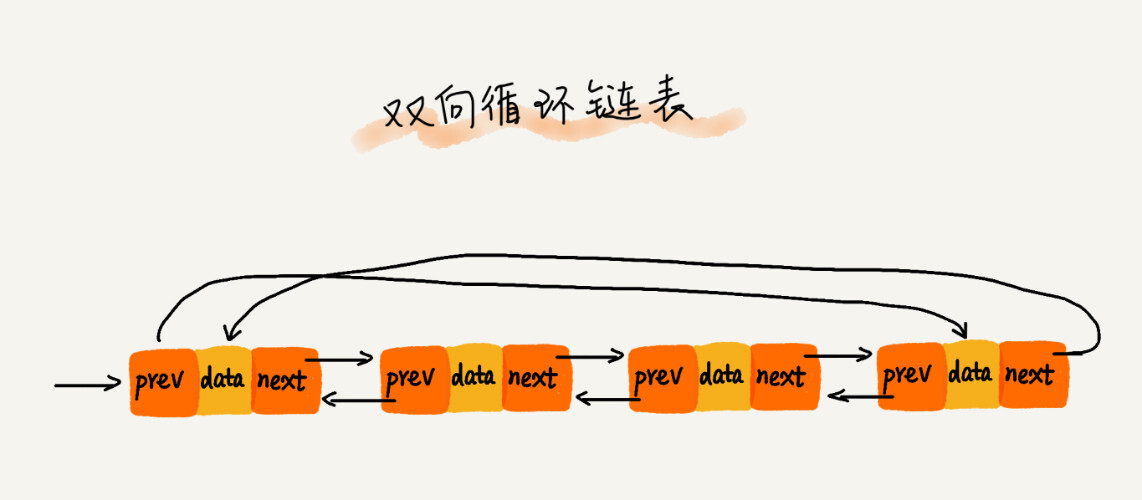
每个节点既有后继指针,又有前驱指针prev。
双向链表优点:
双向链表可以支持 O(1) 时间复杂度的情况下找到前驱结点,所以,双向链表在某些情况下的插入、删除等操作都要比单链表简单、高效。
前面所说的单链表插入、删除的时间复杂度为O(1)是理论情况,实际上是不准确的。
删除操作:
在实际的软件开发中,从链表中删除一个数据无外乎这两种情况:
-
删除结点中“值等于某个给定值”的结点;
- 删除给定指针指向的结点。
第一种情况,要找到相等的值,都需要遍历,所以时间复杂度都为O(n)。
第二种情况,删除某个结点 q需要知道其前驱结点,单链表组要遍历(O(n)),双向链表直接保存有(O(1))。
在指定结点前插入操作同理,需要知道前驱指针。
双向循环链表
LRU缓存,链表实现:
1. 如果此数据之前已经被缓存在链表中了,我们遍历得到这个数据对应的结点,并将其从原来的位置删除,然后再插入到链表的头部。
2. 如果此数据没有在缓存链表中,又可以分为两种情况:
-
如果此时缓存未满,则将此结点直接插入到链表的头部;
-
如果此时缓存已满,则链表尾结点删除,将新的数据结点插入链表的头部。
07丨如何轻松写出正确的链表代码
几个写链表代码的技巧:
1、理解指针或引用的含义
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,
指向了这个变量,通过指针就能找到这个变量。
2、警惕指针丢失和内存泄漏(单链表)
① 内存泄漏:由于疏忽或错误造成程序未能释放已经不再使用的内存。
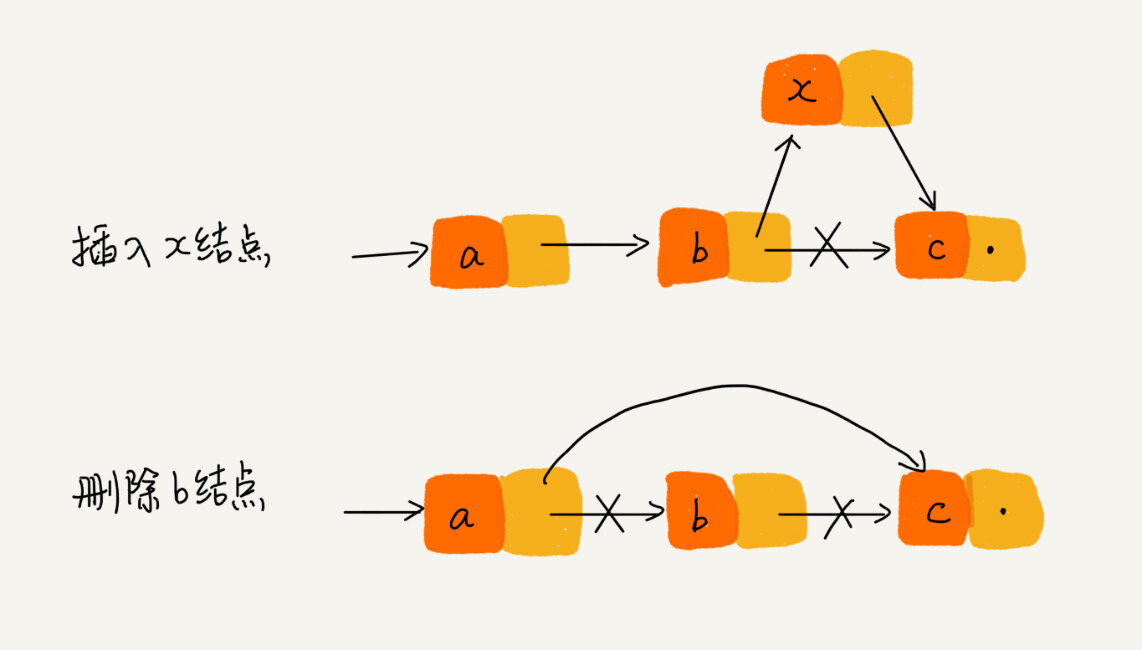
② 插入节点时,要注意操作的顺序。
在节点a和节点b之间插入节点x,b是a的下一节点,p指针指向节点a,若代码如下,则指针丢失。
p->next = x; // 将 p 的 next 指针指向 x 结点;
x->next = p->next; // 将 x 的结点的 next 指针指向 b 结点;
③ 删除链表节点时,记得手动释放内存空间。
3、利用哨兵简化实现难度
哨兵是解决“边界问题“”的,不直接参与业务逻辑。在任何时候,不管链表是不是空,head 指针(表示头结点指针)都会一直指向这个哨兵结点。我们也把这种有哨兵结点的链表叫带头链表。相反,没有哨兵结点的链表就叫作不带头链表。
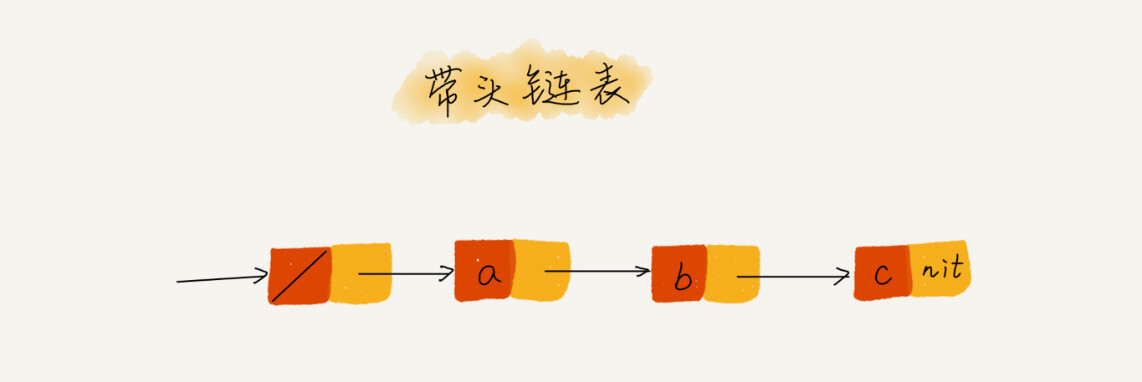
例:
① 在结点 p 后面插入一个新的结点,代码如下:
new_node->next = p->next;
p->next = new_node;
若要想一个空链表中插入第一个节点,则代码错误。若加入哨兵,节点为s,则代码为:
new_node->next = s->next;
s->next = new_node;
② 删除p的后继节点,代码如下:
p->next = p->next->next;若删除的是链表中的最后一个节点,则代码错误。若在链表最后加入哨兵结点,节点为s,则上述代码正确。
4、重点留意边界条件处理
检查链表代码是否正确的边界条件:
-
如果链表为空时,代码是否能正常工作?
-
如果链表只包含一个结点时,代码是否能正常工作?
-
如果链表只包含两个结点时,代码是否能正常工作?
-
代码逻辑在处理头结点和尾结点的时候,是否能正常工作?
5、举例画图,辅助思考
6、多写多练,没有捷径
5个常见链表操作:
-
单链表反转
-
链表中环的检测
-
两个有序的链表合并
-
删除链表倒数第 n 个结点
-
求链表的中间结点