学习内容来自前Google工程师—王争专栏
- 广义讲数据结构就是存储数据的结构。算法是操作数据的一组方法
- 数据结构为算法服务,数据结构有特定的算法
- 孤立存在的数据结构没有用
- 是什么,为什么,怎么做
- 首先要掌握一个数据结构与算法中最重要的概念——复杂度分析。
- 所以,如果你只掌握了数据结构和算法的特点、用法,但是没有学会复杂度分析,那就相当于只知道操作口诀,而没掌握心法。只有把心法了然于胸,才能做到无招胜有招!
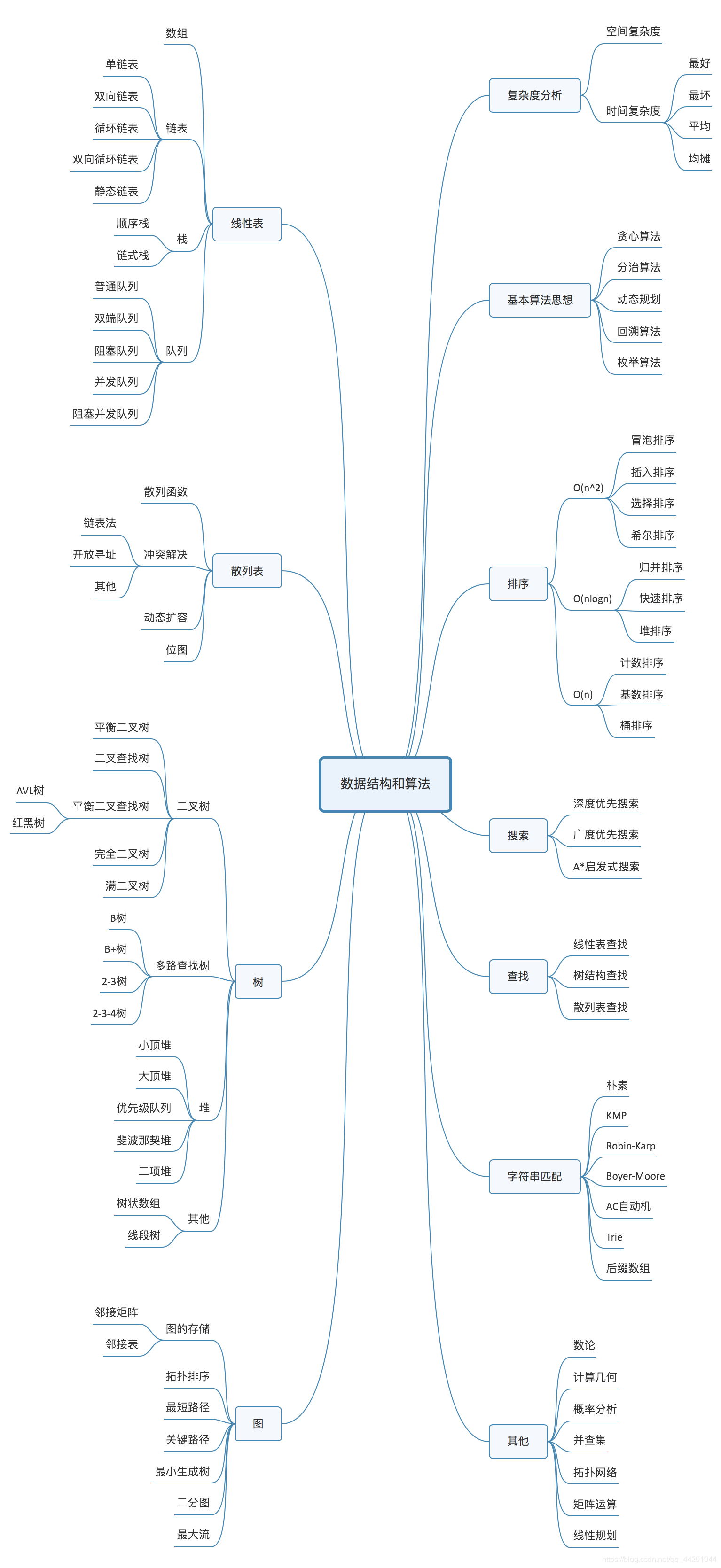
10个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie树;10个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法。
- 写代码的时候就会不由自主地考虑到很多性能方面的事情,时间复杂度、空间复杂度非常高的垃圾代码出现的次数就会越来越少。你的编程内功就真正得到了修炼。
- 学习知识的过程是反复迭代,不断沉淀的过程
- 复杂度分析很重要
- 为什么需要复杂度分析:测试结果非常依赖测试环境,数据的规模不一样
- 小规模的排序插入排序比快排还要快
- 大O时间复杂度实际上并不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以,也叫作渐进时间复杂度(asymptotic time complexity),简称时间复杂度。
- 嵌套法则:乘法
- 归并排序、快速排序的时间复杂度都是O(nlogn)。
- 渐进时间复杂度,渐进空间复杂度
- 空间复杂度比较简单
- 复杂度又叫渐进复杂度
时间复杂度空间复杂度分析
- 最好时间复杂度,最坏时间复杂度,平均时间复杂度
为什么数组都是从0 开始编号的
- 什么是数组呢?是一种线性表,连续的内存空间存储相同的类型数据
- 链表 队列 栈 都是线性表结构
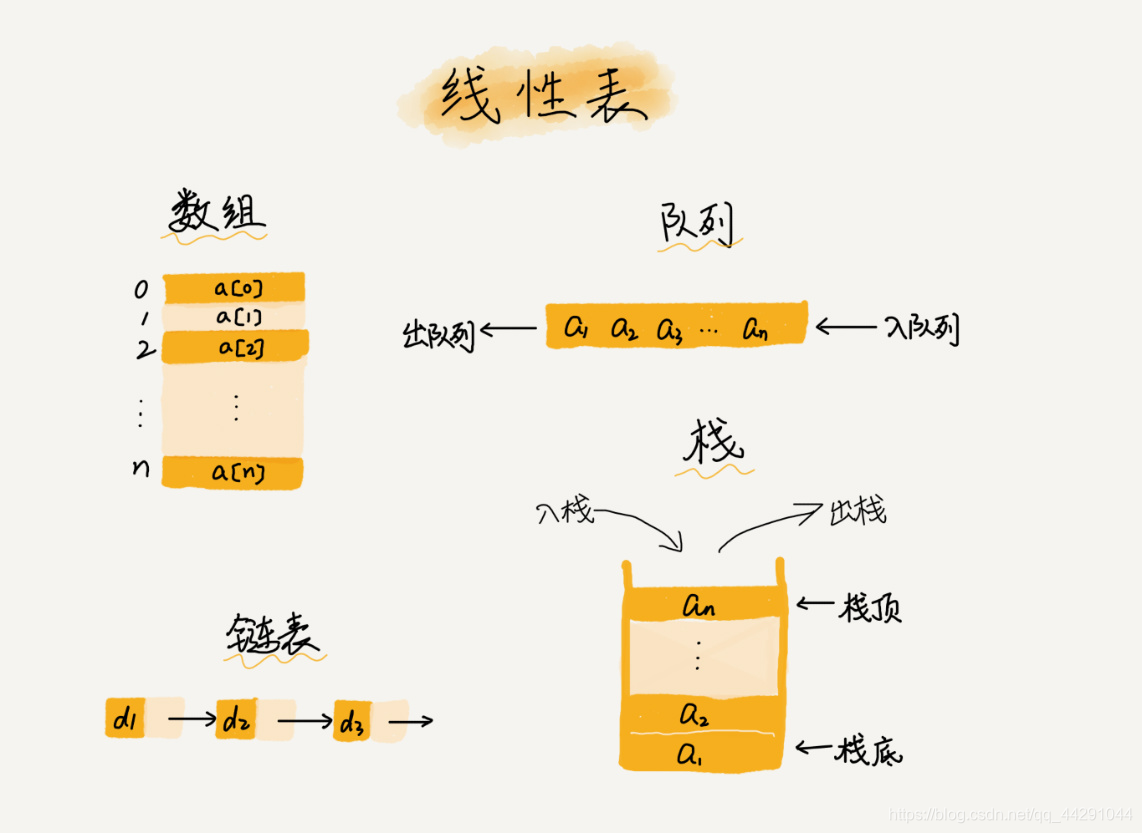
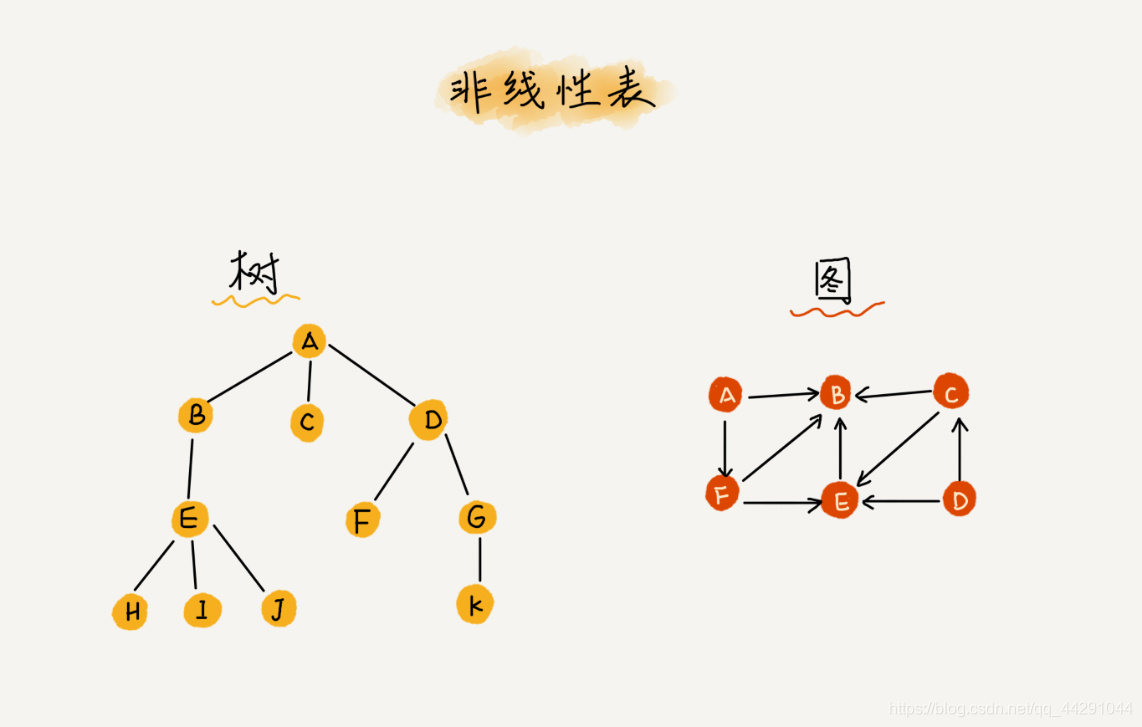
- 非线性表
-
数组支持随机访问,根据下标的时间复杂度为O(1)
-
警惕数组越界问题
-
为了避免d,e,f,g,h这几个数据会被搬移三次,我们可以先记录下已经删除的数据。每次的删除操作并不是真正地搬移数据,只是记录数据已经被删除。当数组没有更多空间存储数据时,我们再触发执行一次真正的删除操作,这样就大大减少了删除操作导致的数据搬移。
-
如果你了解JVM,你会发现,这不就是JVM标记清除垃圾回收算法的核心思想吗?没错,数据结构和算法的魅力就在于此,很多时候我们并不是要去死记硬背某个数据结构或者算法,而是要学习它背后的思想和处理技巧,这些东西才是最有价值的。如果你细心留意,不管是在软件开发还是架构设计中,总能找到某些算法和数据结构的影子。
-
数组的内存空间固定,所以基于数组进行扩展
-
关注性能就用数组,表示多维数组比较直观
-
业务开发几乎不要求极致的性能,但是对于服务器底层的开发,性能就很关键了
-
因为底层的就是从0开始。matlab不是从0开始的
-
函数体内的局部变量存在栈上,且是连续压栈。在Linux进程的内存布局中,栈区在高地址空间,从高向低增长。变量i和arr在相邻地址,且i比arr的地址大,所以arr越界正好访问到i。当然,前提是i和arr元素同类型,否则那段代码仍是未决行为。
-
例子中死循环的问题跟编译器分配内存和字节对齐有关 数组3个元素 加上一个变量a 。4个整数刚好能满足8字节对齐 所以i的地址恰好跟着a2后面 导致死循环。。如果数组本身有4个元素 则这里不会出现死循环。。因为编译器64位操作系统下 默认会进行8字节对齐 变量i的地址就不紧跟着数组后面了。
-
无限循环的问题,我认为内存分配是从后往前分配的。例如,在Excel中从上往下拉4个格子,变量i会先被分配到第4个格子的内存,然后变量arr往上数分配3个格子的内存,但arr的数据是从分配3个格子的第一个格子从上往下存储数据的,当访问第3索引时,这时刚好访问到第4个格子变量i的内存。
-
寻址公式
a[i]_address = base_address + i * data_type_size
链表的LRU缓存淘汰算法
- 缓存淘汰策略:FIFO(先进先出),LFU(最少使用),LRU(最近最少使用)
- 数组需要一块连续的内存空间来存储,对内存的要求比较高。如果我们申请一个100MB大小的数组,当内存中没有连续的、足够大的存储空间时,即便内存的剩余总可用空间大于100MB,仍然会申请失败。
- 链表就不需要连续
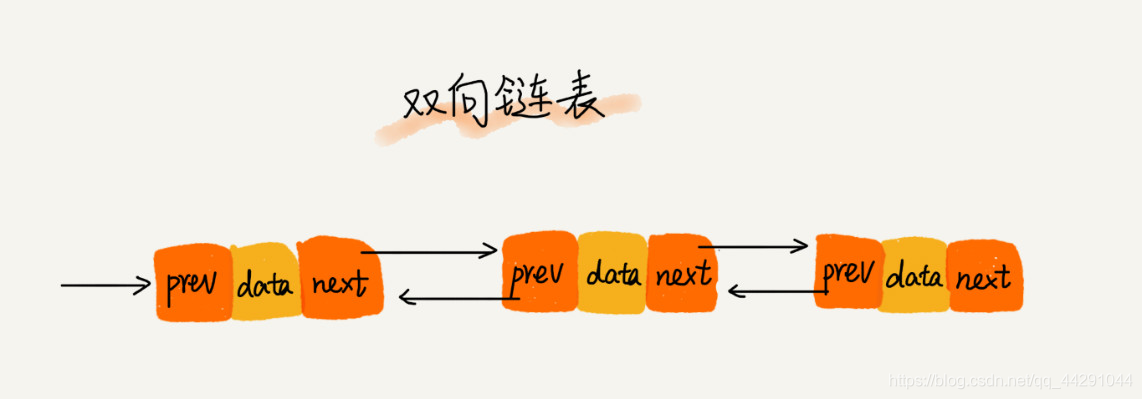
- 链表的头节点存储的基地址,就可以遍历得到整个链表,尾节点指向空
- 空间换时间的思想
- 手机内存大时可以用空间换时间,加快响应的速度
- 在往动态扩容的数据结构中,当空间不够时会动态申请内存空间,比较耗时
轻松的写出链表反转的代码
-
java和python是引用,都是存储对象的内存地址
-
删除链表结点时,也一定要记得手动释放内存空间,否则,也会出现内存泄漏的问题。
-
用虚拟机自动管理内存就不用考虑内存泄漏的问题
-
哨兵解决边界问题
如何实现浏览器的前进后退功能
- 当你依次访问完一串页面a-b-c之后,点击浏览器的后退按钮,就可以查看之前浏览过的页面b和a。当你后退到页面a,点击前进按钮,就可以重新查看页面b和c。但是,如果你后退到页面b后,点击了新的页面d,那就无法再通过前进、后退功能查看页面c了。
- 用数组实现的栈叫顺序栈,链表实现的栈叫链式栈
- 数组实现的栈是制定大小的栈,如何实现动态扩容的栈
- 对于动态扩容的栈,入栈为O(1),当空间不够了就是O(n)
- 函数调用用栈来保存临时变量,为什么用栈呢?先进先出
09-队列:队列在线程池等有限资源池中的应用
- 线程池实现的实现原理就是队列
- 栈和队列的操作都很简单,入栈和出栈,入队和出队
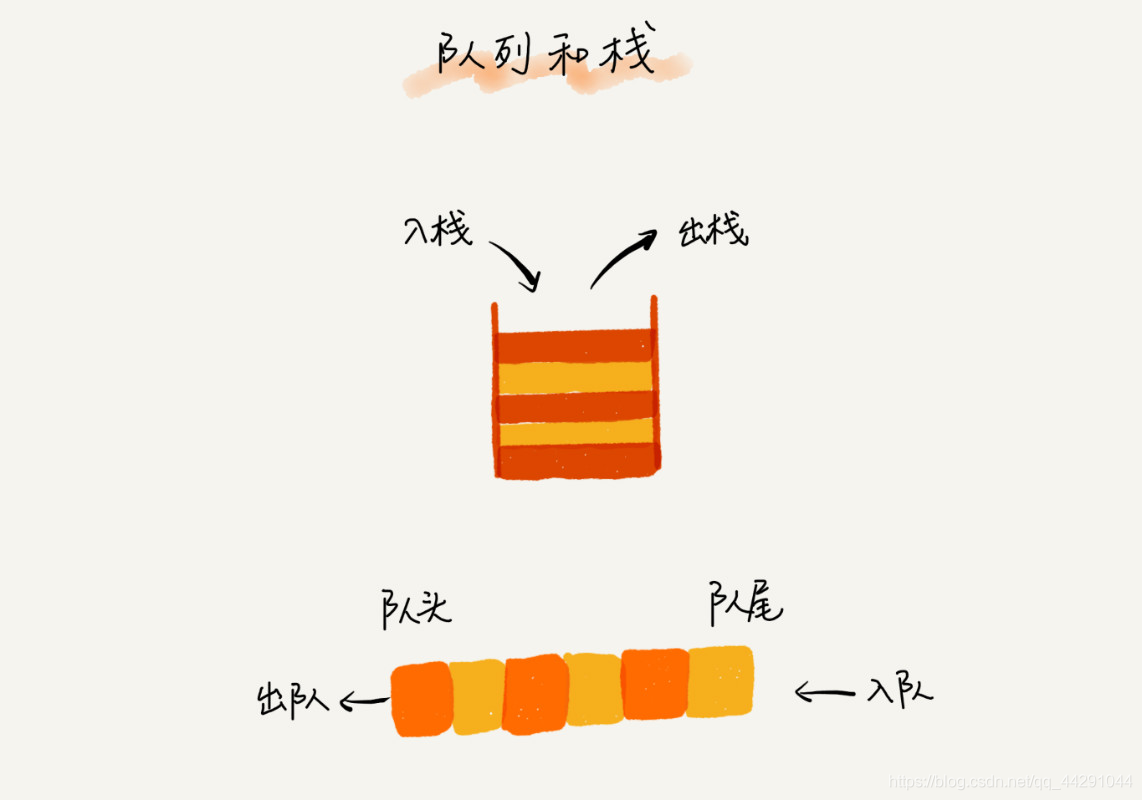
- 用数组实现的队列叫顺序队列
- 用链表实现的队列叫链式队列
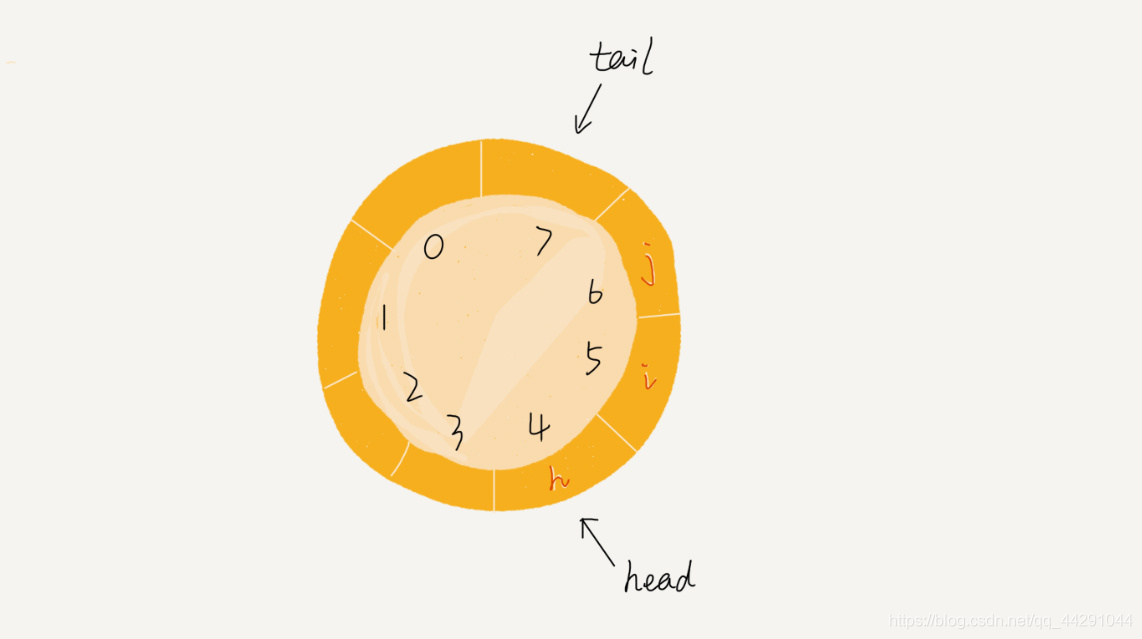
循环队列
阻塞队列和并发队列
- 基于阻塞队列实现生产者消费者模型
- 当生产者数据量过大,消费者来不及的时候,可以让消费者等待。最好是增加消费者的数量
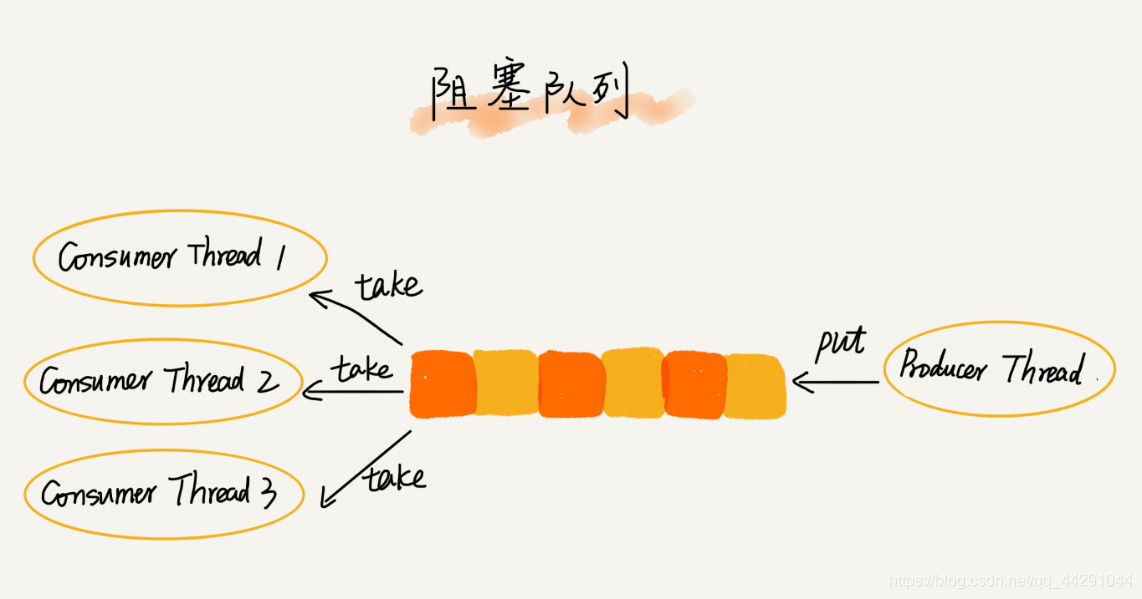
- 在多线程的情况下会有多个线程同时操作队列,这个时候就会存在线程安全的问题,如何实现一个安全的额队列?
- 线程安全的 队列又叫做并发队列。最简单的实现是在入队和出队的时候加锁。
- 事实上用循环队列比链式队列效率更高。
线程池是用数组实现的队列还是链表实现的队列呢?
- 用链表实现的队列是无界队列,当生产者数据量太多时,可能会消费者响应时间过长,显然不适合线程池的场景
- 用数组实现的有界队列是池类技术常用的手段,当生产者数量过大对返回异常让其等待,选定池子的大小也是有讲究的。
- 在资源有限的场景都可以通过队列让其排队
思考:如何实现无锁并发队列
10-递归:如何用三行代码找到“最终推荐人”?
- 业务场景:推荐、注册、返佣金
- 用户A推荐用户B推荐用户C
两大重要的概念:递归和动态规划
- 后面的很多数据结构与算法都用到了递归
- DFS、前中后序二叉树遍历
- 去的过程叫做“递”,回来的过程叫做“归”
f(n)=f(n-1)+1 其中,f(1)=1
int f(int n) {
if (n == 1) return 1;
return f(n-1) + 1;
}
- 经典的青蛙跳台阶问题
def f(n):
if n == 1:
return 1
elif n == 2:
return 2
return f(n-1)+f(n-2)
res = f(30)
print(res)
- 递归容易造成堆栈溢出,为什么呢?
- 因为函数的调用在没返回的时候会压入栈,直到返回之后才出栈
- 当规模很大,数据很多就会造成堆栈溢出,可以控制代码递归的深度
- 但是递归的深度和栈的剩余空间大小有关,无法实时监控,如果实时监控代码过于复杂,增加了代码的可读性
def memosize(f):
memo = {}
def helper(x):
if x not in memo:
memo[x] = f(x)
return memo[x]
return helper
# func = memosize(func)
@memosize
def func(n):
if n == 1:
return 1
elif n == 2:
return 2
return func(n - 1) + func(n - 2)
res = func(500)
print(res)
- 递归都要优化,否则会重复调用函数
代码分析:用装饰器memosize装饰函数,被装饰的func传入f,helper也是func,n是x,闭包里返回的东西也是func返回的。拦截器的作用。
- 优化的本质是:用内存维护一个数组或map当做缓存
递归调试的问题
- 我们平时调试代码喜欢使用IDE的单步跟踪功能,像规模比较大、递归层次很深的递归代码,几乎无法使用这种调试方式。对于递归代码,你有什么好的调试方法呢?
调试递归:
1.打印日志发现,递归值。
2.结合条件断点进行调试。
11-排序(上):为什么插入排序比冒泡排序更受欢迎?
- 排序算法的稳定性:当出现数值相等的两个数,相等的元素之间原有的顺序保持不变
- 算法的执行效率、内存消耗、算法的稳定性。
- 排序算法在不同的时间负载读的表现
- 选择排序不稳定
- 插入排序和冒泡排序:都是固定的值
- 插入排序的优化:希尔排序
12-排序(下):如何用快排思想在O(n)内查找第K大元素?
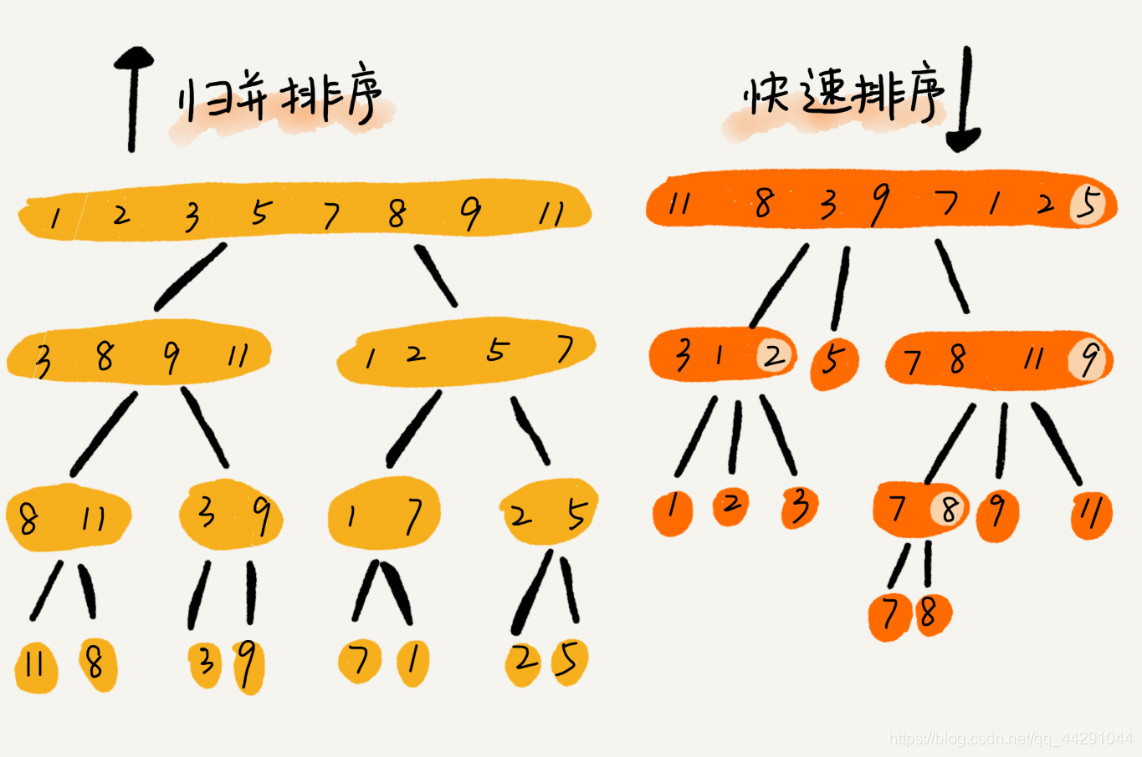
- 归并排序和快速排序都用了分治和分区的思想,归并排序不是原地排序,空间复杂度高,所以没有快排应用广泛。快排几乎很少情况下空间复杂度会退化到n²,只要合理选择指针的位置
13-线性排序:如何根据年龄给100万用户数据排序?
- 桶排序:O(n),当桶排序中的桶越多时间复杂度越低,但是需要的数据条件比较苛刻,首先桶可以排序,数据要均匀
- 桶排序适用于在外部排序(不在内存中排序)
- 所谓的外部排序就是数据存储在外部磁盘中,数据量比较大,内存有限,无法将数据全部加载到内存中。

- 计数排序:高考考生问题排序
- 基数排序:电话号码
14-排序优化:如何实现一个通用的、高性能的排序函数?
- 几乎所有的编程语言都会提供排序函数,比如C语言中qsort(),C++ STL中的sort()、stable_sort(),还有Java语言中的Collections.sort()。在平时的开发中,我们也都是直接使用这些现成的函数来实现业务逻辑中的排序功能。那你知道这些排序函数是如何实现的吗?底层都利用了哪种排序算法呢?
- 如何实现通用的高性能的排序函数
- java中默认为堆排序,c语言默认为快排
- 快排的优化:三点取中法、随机法
- 快排默认用递归实现,递归要防止堆栈溢出
- 归并,插入和快排:哨兵机制,数据量小时会退化为插入排序
- O(n2)时间复杂度的算法并不一定比O(nlogn)的算法执行时间长:数学画图可以看出,小规模数据的排序
- Glibc中的qsort()函数:qsort()会优先使用归并排序来排序输入数据:
所以对于小数据量的排序,比如1KB、2KB等,归并排序额外需要1KB、2KB的内存空间,这个问题不大。现在计算机的内存都挺大的,我们很多时候追求的是速度。还记得我们前面讲过的用空间换时间的技巧吗?这就是一个典型的应用。
- 但如果数据量太大,就跟我们前面提到的,排序100MB的数据,这个时候我们再用归并排序就不合适了。所以,要排序的数据量比较大的时候,qsort()会改为用快速排序算法来排序。
- 那qsort()是如何选择快速排序算法的分区点的呢?如果去看源码,你就会发现,qsort()选择分区点的方法就是“三数取中法”。
- 递归太深会导致堆栈溢出的问题,qsort()是通过自己实现一个堆上的栈,手动模拟递归来解决的。
- 在快速排序的过程中,当要排序的区间中,元素的个数小于等于4时,qsort()就退化为插入排序,不再继续用递归来做快速排序,因为我们前面也讲过,在小规模数据面前,O(n2)时间复杂度的算法并不一定比O(nlogn)的算法执行时间长。
- 时间复杂度代表的是一个增长趋势,如果画成增长曲线图,你会发现O(n2)比O(nlogn)要陡峭,也就是说增长趋势要更猛一些。
- 合理选择分区点、避免递归太深等等。最后,我还带你分析了一个C语言中qsort()的底层实现原理
- java1.8中的排序,在元素小于47的时候用插入排序,大于47小于286用双轴快排,大于286用timsort归并排序,并在timesort中记录数据的连续的有序段的的位置,若有序段太多,也就是说数据近乎乱序,则用双轴快排,当然快排的递归调用的过程中,若排序的子数组数据数量小,用插入排序。
- golang标准库中的Sort用的是快排+希尔排序+插排,数据量大于12时用快排,小于等于12时用6作为gap做一次希尔排序,然后走一遍普通的插排(插排对有序度高的序列效率高)。其中快排pivot的选择做了很多工作不是一两句话可以描述出来,是基于首中尾中值的很复杂的变种
1.排序算法一览表
时间复杂度 是稳定排序? 是原地排序?
冒泡排序 O(n^2) 是 是
插入排序 O(n^2) 是 是
选择排序 O(n^2) 否 是
快速排序 O(nlogn) 否 是
归并排序 O(nlogn) 是 否
桶排序 O(n) 是 否
计数排序 O(n+k),k是数据范围 是 否
基数排序 O(dn),d是纬度 是 否
2.为什选择快速排序?
1)线性排序时间复杂度很低但使用场景特殊,如果要写一个通用排序函数,不能选择线性排序。
2)为了兼顾任意规模数据的排序,一般会首选时间复杂度为O(nlogn)的排序算法来实现排序函数。
3)同为O(nlogn)的快排和归并排序相比,归并排序不是原地排序算法,所以最优的选择是快排。
二、如何优化快速排序?
导致快排时间复杂度降为O(n)的原因是分区点选择不合理,最理想的分区点是:被分区点分开的两个分区中,数据的数量差不多。如何优化分区点的选择?有2种常用方法,如下:
1.三数取中法
①从区间的首、中、尾分别取一个数,然后比较大小,取中间值作为分区点。
②如果要排序的数组比较大,那“三数取中”可能就不够用了,可能要“5数取中”或者“10数取中”。
2.随机法:每次从要排序的区间中,随机选择一个元素作为分区点。
3.警惕快排的递归发生堆栈溢出,有2中解决方法,如下:
①限制递归深度,一旦递归超过了设置的阈值就停止递归。
②在堆上模拟实现一个函数调用栈,手动模拟递归压栈、出栈过程,这样就没有系统栈大小的限制。
三、通用排序函数实现技巧
1.数据量不大时,可以采取用时间换空间的思路
2.数据量大时,优化快排分区点的选择
3.防止堆栈溢出,可以选择在堆上手动模拟调用栈解决
4.在排序区间中,当元素个数小于某个常数是,可以考虑使用O(n^2)级别的插入排序
5.用哨兵简化代码,每次排序都减少一次判断,尽可能把性能优化到极致
四、思考
1.Java中的排序函数都是用什么排序算法实现的?有有哪些技巧?
