原文地址:
https://www.cnblogs.com/pinard/p/9756075.html
-------------------------------------------------------------------------------------------------------
在强化学习(八)价值函数的近似表示与Deep Q-Learning中,我们讲到了Deep Q-Learning(NIPS 2013)的算法和代码,在这个算法基础上,有很多Deep Q-Learning(以下简称DQN)的改进版,今天我们来讨论DQN的第一个改进版Nature DQN(NIPS 2015)。
本章内容主要参考了ICML 2016的deep RL tutorial和Nature DQN的论文。
1. DQN(NIPS 2013)的问题
在上一篇我们已经讨论了DQN(NIPS 2013)的算法原理和代码实现,虽然它可以训练像CartPole这样的简单游戏,但是有很多问题。这里我们先讨论第一个问题。
注意到DQN(NIPS 2013)里面,我们使用的目标Q值的计算方式:
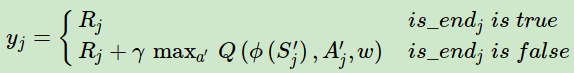

因此,一个改进版的DQN: Nature DQN尝试用两个Q网络来减少目标Q值计算和要更新Q网络参数之间的依赖关系。下面我们来看看Nature DQN是怎么做的。
2. Nature DQN的建模
Nature DQN使用了两个Q网络,一个当前Q网络QQQQ用来选择动作,更新模型参数,另一个目标Q网络Q′用于计算目标Q值。目标Q网络的网络参数不需要迭代更新,而是每隔一段时间从当前Q网络QQ复制过来,即延时更新,这样可以减少 目标Q值和当前的Q值 相关性。
要注意的是,两个Q网络的结构是一模一样的。这样才可以复制网络参数。
Nature DQN和上一篇的DQN相比,除了用一个新的相同结构的目标Q网络来计算目标Q值以外,其余部分基本是完全相同的。
3. Nature DQN的算法流程
下面我们来总结下Nature DQN的算法流程, 基于DQN NIPS 2015:

注意,上述第二步的f步和g步的Q值计算也都需要通过Q网络计算得到。另外,实际应用中,为了算法较好的收敛,探索率εϵ需要随着迭代的进行而变小。