Deep Q Network(DQN)是一种结合了CNN和Q learning的深度强化学习方法,下面将从背景、DL与RL结合挑战等方面对该方法进行讨论。
一、背景
从高维感知输入(如视觉、语音)直接学习如何控制agent对强化学习(RL)来说是一大挑战。之前很多RL算法依赖于手工选取的特征以及一个线性值函数或者一个线性策略表达式。这些系统都依赖于特征的选取质量。
深度学习(DL)可以很好的提取高维特征,那么我们很自然的想到是否可以将其应用于强化学习(RL)上?
二、DL和RL结合的挑战
- 成功的深度学习应用大多都具备很好的数据集标签(labels),而RL没有明确的标签,只能通过一个有延迟的reward来学习。
- 另外,深度学习一般假设其样本都是独立同分布的,但在RL中,通常会遇到一段相关度很高的状态量(state),且状态的分布也不相同。
- 过往的研究表明,使用非线性网络表示值函数时出现网络不稳定,收敛困难等问题。
三、DQN的解决方案
DQN将卷积神经网络(CNN)与Q学习结合起来,通过以下方法,对DL与RL的结合问题进行解决:
- 采用Q learning的目标值函数来构造DL的标签,从而构造DL的loss function;
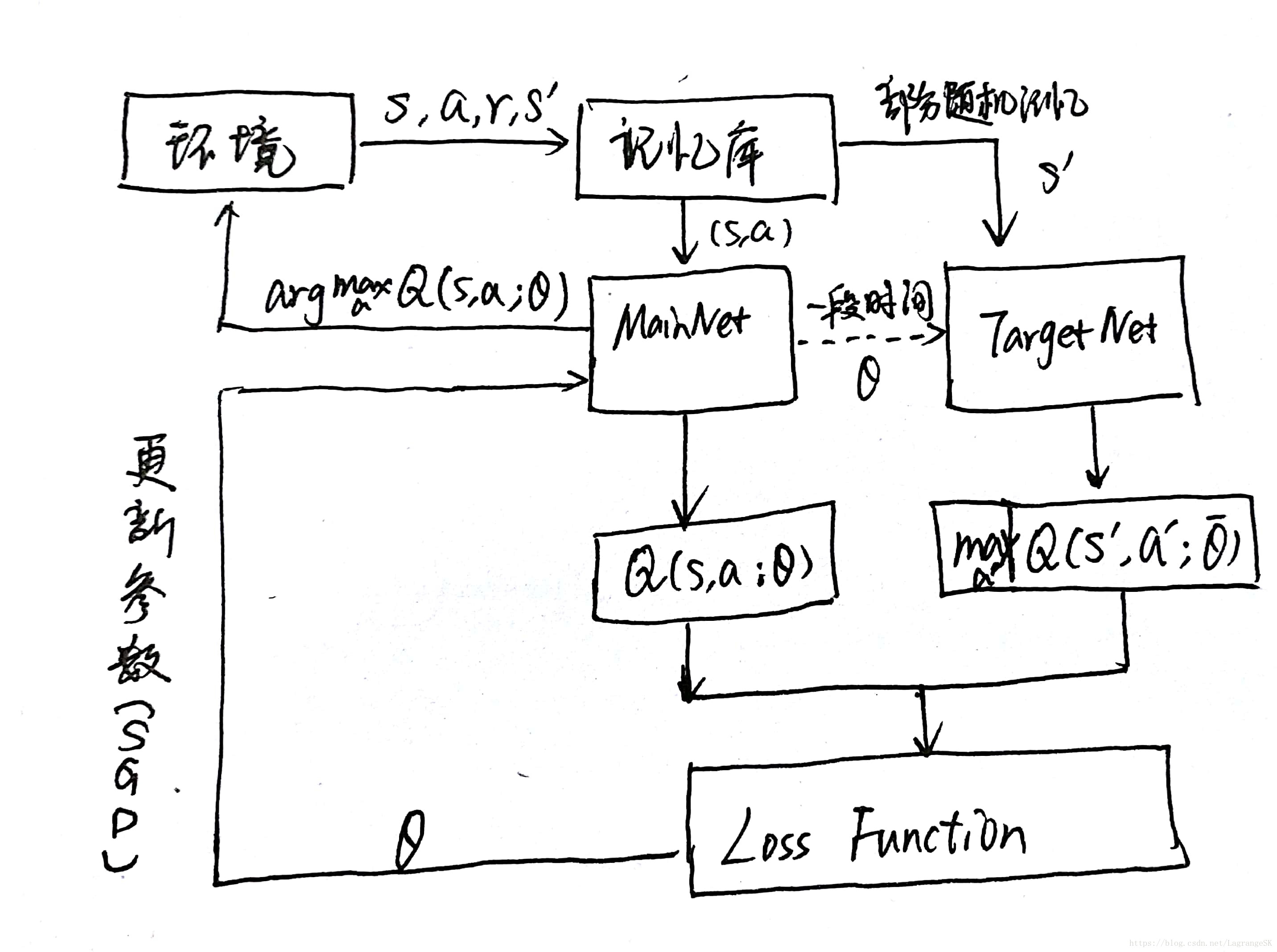
- .采用了记忆回放(experience replay mechanism) 来解决数据关联性问题;
- 使用一个CNN(MainNet)产生当前Q值,使用另外一个CNN(Target)产生Target Q值。(在2015年改进的DQN中)
loss function 构造
RL原理此不赘述,Q learning的更新方程如下:
DQN的loss function为:
目标函数为:
其中, 为神经网络的参数。
Loss Function是基于Q-Learning更新公式的第二项确定的,两个公式都是使当前的Q值逼近Target Q值。
接下来,求 关于 的梯度,使用随机梯度下降(SGD)等方法更新网络参数 。
记忆回放(experience replay mechanism)
为了让RL的数据(关联性不独立分布的数据)更接近DL所需要的数据(独立同分布数据),在学习过程中建立一个“记忆库”,将一段时间内的state、action、state_(下一时刻状态)以及reward存储在记忆库里,每次训练神经网络时,从记忆库里随机抽取一个batch的记忆数据,这样就打乱了原始数据的顺序,将数据的关联性减弱。
目标网络
为了使得算法性能更稳定,建立两个结构一样的神经网络:一直在更新神经网络参数的网络(MainNet)和用于更新Q值(TargetNet)。
- .初始时刻将MainNet的参数赋值给TargetNet,
- 然后MainNet继续更新神经网络参数,而TargetNet的参数固定不动。
- 再过一段时间将MainNet的参数赋给TargetNet,如此循环往复。
这样使得一段时间内的目标Q值是稳定不变的,从而使得算法更新更加稳定。
四、算法伪代码

以上代码为2015年更新版本的DQN。
五、算法流程
六、算法评价
解决的问题:
- 解决了Q学习的QTable高维度灾难问题,使得Q值连续化
- 将DL和RL数据集不兼容问题解决(记忆库、固定目标值函数网络)
存在问题:
- action依然是从最大的Q值中选取,无法用于action连续的问题
- 只能处理只需短时记忆问题,无法处理需长时记忆问题;
- CNN不一定收敛,需精良调参。
参考文献:
https://blog.csdn.net/u013236946/article/details/72871858
Human-level Control Through Deep Reinforcement Learning
Playing Atari with Deep Reinforcement Learning