原文地址:
https://www.cnblogs.com/pinard/p/9778063.html
-----------------------------------------------------------------------------------------------
在强化学习(九)Deep Q-Learning进阶之Nature DQN中,我们讨论了Nature DQN的算法流程,它通过使用两个相同的神经网络,以解决数据样本和网络训练之前的相关性。但是还是有其他值得优化的点,文本就关注于Nature DQN的一个改进版本: Double DQN算法(以下简称DDQN)。
本章内容主要参考了ICML 2016的deep RL tutorial和DDQN的论文<Deep Reinforcement Learning with Double Q-learning>。
1. DQN的目标Q值计算问题
在DDQN之前,基本上所有的目标Q值都是通过贪婪法直接得到的,无论是Q-Learning, DQN(NIPS 2013)还是 Nature DQN,都是如此。比如对于Nature DQN,虽然用了两个Q网络并使用目标Q网络计算Q值,其第j个样本的目标Q值的计算还是贪婪法得到的,计算入下式:
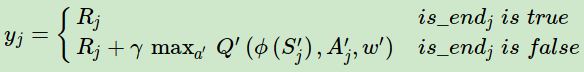
使用max虽然可以快速让Q值向可能的优化目标靠拢,但是很容易过犹不及,导致过度估计(Over Estimation),所谓过度估计就是最终我们得到的算法模型有很大的偏差(bias)。为了解决这个问题, DDQN通过 解耦 目标Q值动作的选择和目标Q值的计算这两步,来达到消除过度估计的问题。
2. DDQN的算法建模
DDQN和Nature DQN一样,也有一样的两个Q网络结构。在Nature DQN的基础上,通过解耦目标Q值动作的选择和目标Q值的计算这两步,来消除过度估计的问题。
在上一节里,Nature DQN对于非终止状态,其目标Q值的计算式子是:
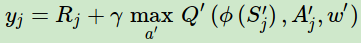
在DDQN这里,不再是直接在目标Q网络里面找各个动作中最大Q值,而是先在当前Q网络中先找出最大Q值对应的动作,即
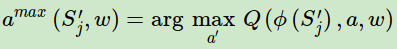
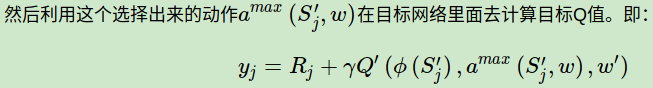
综合起来写就是:
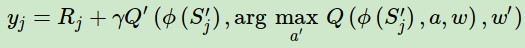
除了目标Q值的计算方式以外,DDQN算法和Nature DQN的算法流程完全相同。
3. DDQN算法流程
这里我们总结下DDQN的算法流程,和Nature DQN的区别仅仅在步骤2.f中目标Q值的计算。