爬取APP数据流程:
1、使用抓包工具;
2、手机使用代理;
3、获取并分析接口;
4、反编译apk获取key;
5、突破反爬限制。
工具:
1、夜神模拟器
2、Fiddler
实现过程:
1、下载夜神模拟器模拟手机,也可用真机;
2、下载Fiddler抓包工具,抓取手机APP数据包;
3、分析接口;
4、使用Python实现爬虫程序。
Fiddler安装配置过程:
1、下载并安装Fiddler;
2、设置Fiddler (配置完后记得重启Fiddler):
打开Fiddler,点击Tools(工具)->选中 Fiddler Options(选项…)->选中”Decrpt HTTPS traffic(解密HTTPS通信)”, Fiddler就可以截获HTTPS请求->选中“Ignore server certificate errors(忽略服务器证书错误),会导致浏览器显示不安全。”(如无此项,则点击Actions动作->Reset All Certificates重置所有证书)->选中”Allow remote computers to connect(允许远程计算机连接)”,是允许别的机器把HTTP/HTTPS请求发送到Fiddler上来。
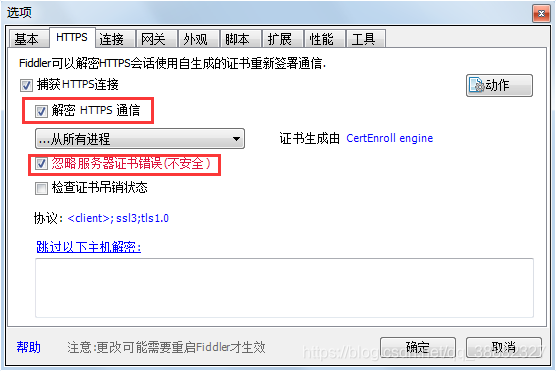
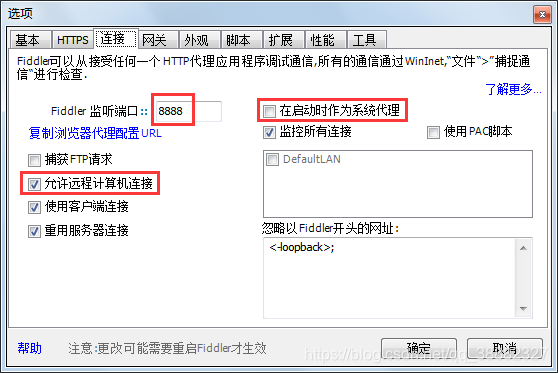
记住端口号是:8888
夜神模拟器安装配置过程:
1、下载安装夜神模拟器;
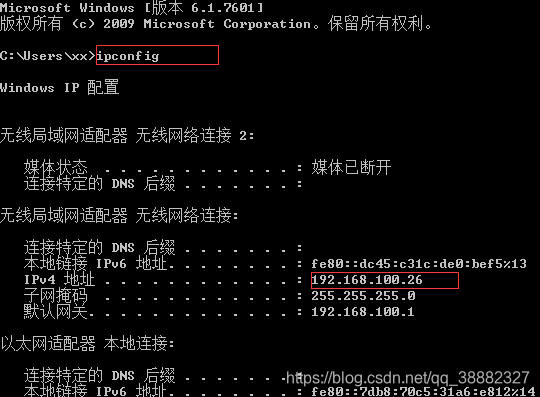
2、配置代理:
打开cmd,输入ipconfig查看本机IP(每次启动电脑都不一样):
进入夜神模拟器 –>打开设置 –>打开WLAN:
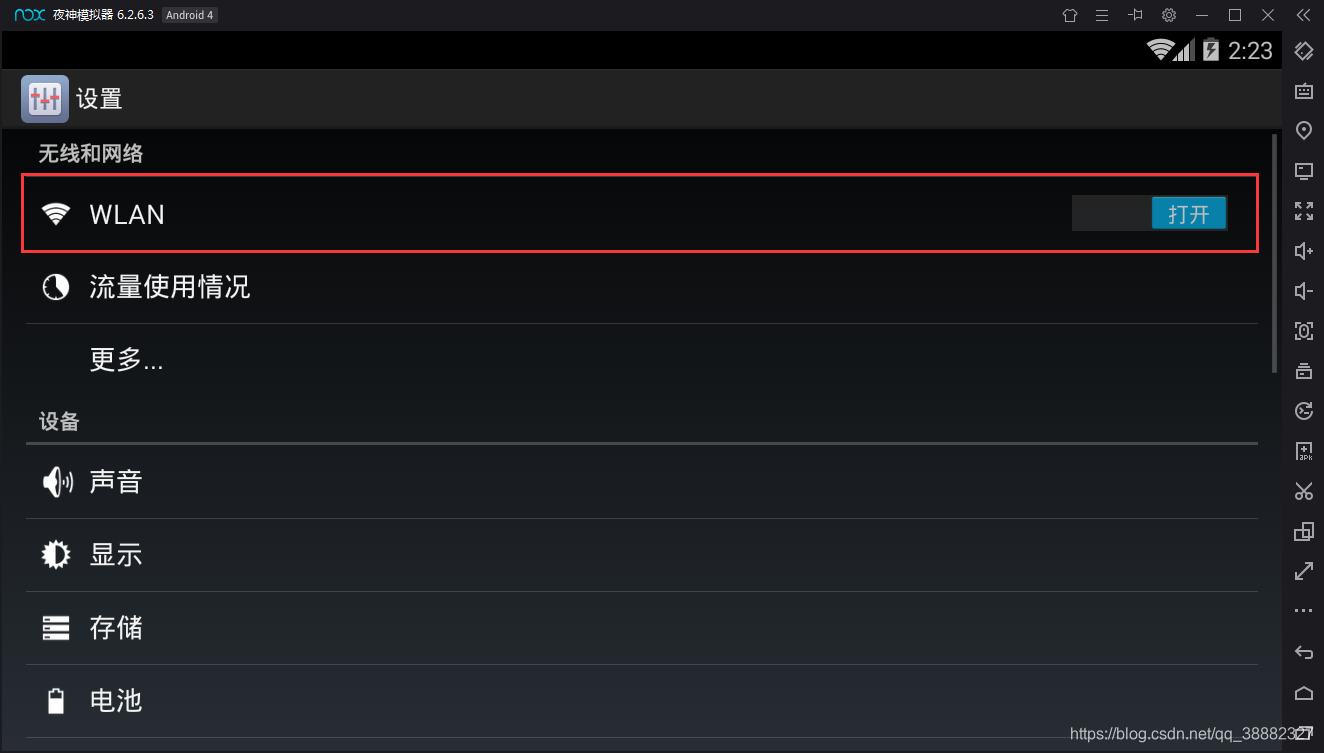
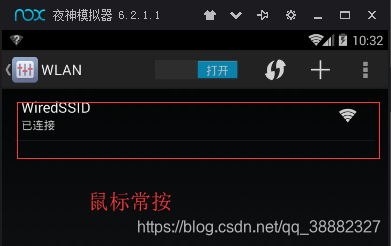

点击修改网络,点击显示高级选项前的框:
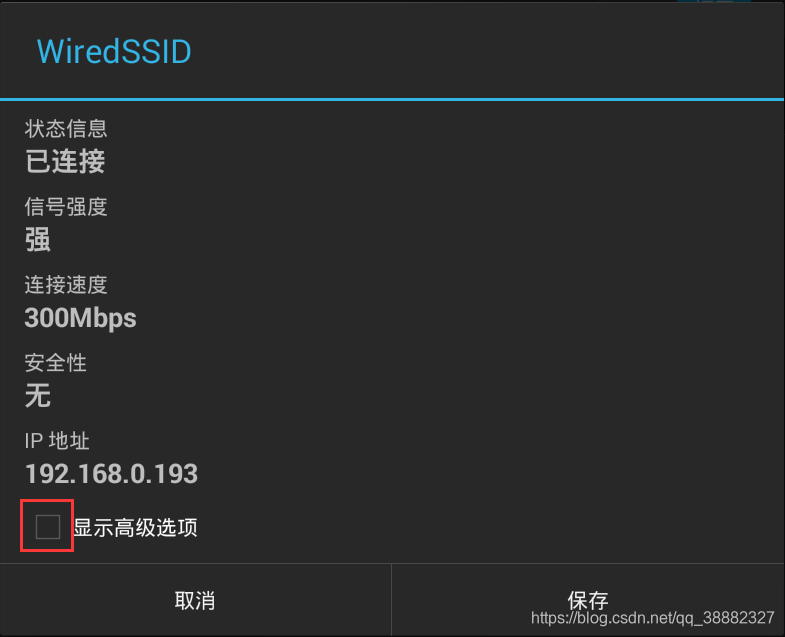
显示代理及IP设置(如未显示,可重启程序),代理模式选手动:
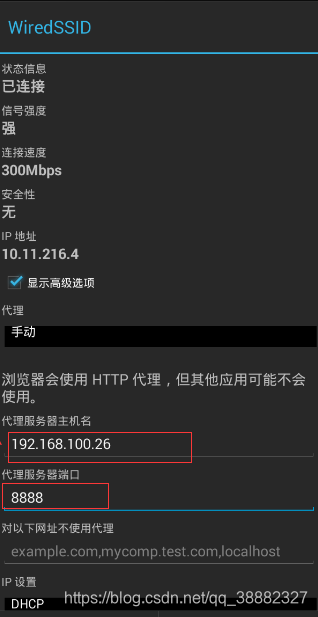
配置完后保存即可(每次重启电脑都需重新设置代理服务器主机名,因为重启后本机IPv4地址都会改变),到这里就设置好所有的配置了。
3、安装Fiddle证书(如需安装证书则操作此步)
在模拟器中的浏览器输入 http://ipv4.fiddler:8888,下载安装证书
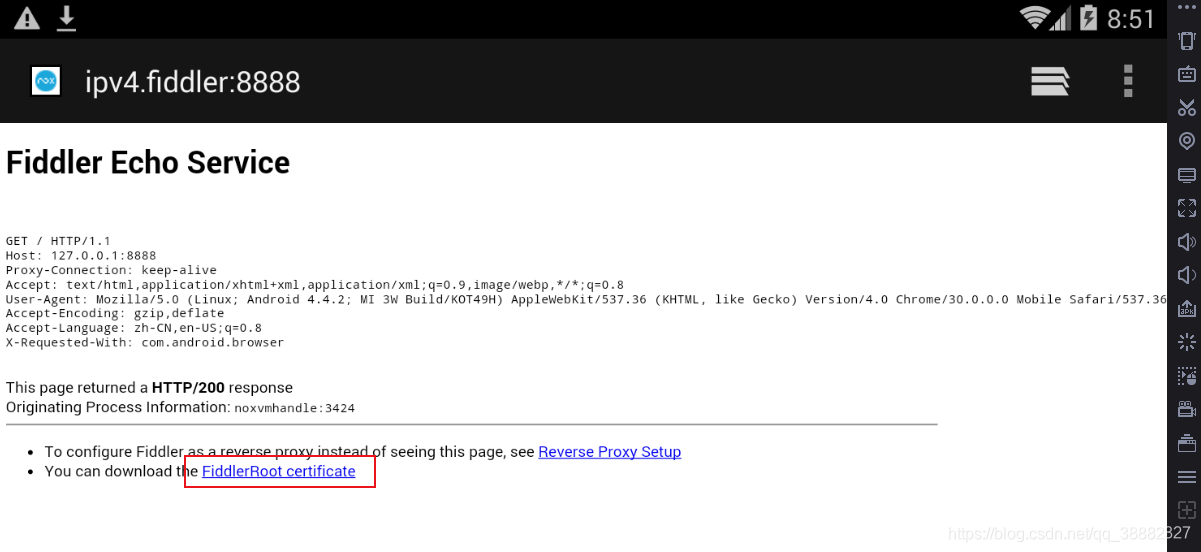

4、在夜神模拟器中安装待爬取的APP,使用Fiddler抓包分析api,最后用python爬取。
爬取老子搜书APP完整代码:
#!/usr/bin/env python
# -*-coding=utf-8-*-
"""
爬取老子搜书,老子搜书用的是追书神器
"""
import requests
import json
import urllib.parse #url编码、解码
import re
# 搜书及书目的消息头
headers = {
'Host':'api.zhuishushenqi.com',
'Connection':'Keep-Alive',
'Accept-Encoding':'gzip',
'User-Agent':'okhttp/3.6.0'
}
# 查看内容详情的消息头
headers2 = {
'Host':'chapter2.zhuishushenqi.com',
'Connection':'Keep-Alive',
'Accept-Encoding':'gzip',
'User-Agent':'okhttp/3.6.0'
}
# 搜书并返回书的id列表
def search(name):
url = 'http://api.zhuishushenqi.com/book/fuzzy-search?query={0}'.format(name)
html = requests.get(url, headers=headers)
content = html.content.decode('utf-8')
con = json.loads(content)['books'] #字符串转换成json,并获取books键的值
book_list = [] #搜索结果id列表
a = 0 #初始化书号
for i in con:
a += 1
aid = i['_id']
title = i['title']
author = i['author']
body = str(a) + '、 ' + title + ' ' + author
book_list.append(aid)
print(body) #打印显示书号、书名、作者
return book_list
# 查看目录并返回章节标题及链接字典列表
def chapters(aid):
url = 'http://api.zhuishushenqi.com/mix-atoc/{0}?view=chapter'.format(aid)
html = requests.get(url, headers=headers)
content = html.content.decode('utf-8')
con = json.loads(content)['mixToc']['chapters']
chapter_list = []
a = 0
for i in con:
a += 1
title = i['title']
link = i['link']
body = str(a) + '、 ' + title
chapter_list.append({title:link}) #将章节标题及链接组成字典并添加到列表
print(body) #打印显示章节号、标题
return chapter_list
# 查看内容
def look(title, url):
new_url = 'http://chapter2.zhuishushenqi.com/chapter/' + urllib.parse.quote(url) #需要url编码,否则路径错误
html = requests.get(new_url, headers=headers2)
content = html.content.decode('utf-8')
con = json.loads(content)['chapter']['body']
print('\n' + title + '\n')
print(con)
if __name__ == '__main__':
while True: #确保书名输入正确
name = input('请输入书名:').strip()
reg = r'[\u4e00-\u9fa5A-Za-z]+.*' #以汉字或字母开头的正则
name_reg = re.compile(reg)
res = name_reg.match(name) #从字符串起始位置匹配
if res:
book_id = search(name) #获取搜书结果id列表
length = len(book_id) #获取搜书结果数量
break
else:
print('输入错误!书名必须以汉字或字母开头!')
while True: #确保书号输入正确
book = input('请选择书号:').strip()
if book.isdigit():
if int(book) > 0 and int(book) <= length:
aid = book_id[int(book)-1] #获取选择的书id
chapter_id = chapters(aid) #获取标题、链接字典列表
length2 = len(chapter_id) #获取章节数
break
else:
print('输入错误!没有该书号!')
else:
print('输入错误!请输入数字!')
while True: #确保章节号输入正确
chapter = input('请选择章节号:').strip()
if chapter.isdigit():
chapter2 = int(chapter)
if chapter2 > 0 and chapter2 <= length2:
while True: #翻页
chap = chapter_id[chapter2-1] #获取当前选择章节的标题、链接字典
title = list(chap)[0] #获取章节标题
url = list(chap.values())[0] #获取章节链接
look(title, url) #查看章节内容
while True: #按键操作
next = input('\n\n\n输入x键进入下一章,q键退出:').strip()
if next == 'x':
chapter2 += 1 #下一页章节号
break
elif next == 'q': #退出按键操作
break
else:
print('输入错误!请重新输入。')
if next == 'q': #退出翻页
break
else:
print('输入错误!没有该章节号!')
else:
print('输入错误!请输入数字!')
if next == 'q': #退出章节,结束程序
print('已退出程序!')
break
总结:
app里的数据比web端更容易抓取,反爬虫也没那么强,大部分也都是http/https协议,返回的数据类型大多数为json。