前言
现在很多的数据都来自移动端的app,很多的数据获取经过处理之后也是十分有用的,这次就爬取最近比较热的王者荣耀中的英雄们的图片,下载到本地。
技术准备
环境:windows/linux
语言:python
版本:3.7
模块/框架:scrapy,os
流程:
1.使用抓包工具Fidder对手机app进行数据的抓取,至于说Fidder如何配置和使用,网上有一大把的资料大家供大家可以使用。
2.从抓包工具中中查看url
3.获取页面代码
4.分离数据
5.获取图片信息并且保存
实现代码
1.创建工程
scrapy startproject King_Fight这里没有说明创建路径,是我在提前建立好的文件夹下面,打开powershell中操作的
然后再spiders文件中建立新的.py文件命名为spider
2.打开抓包工具
注意手机和PC必须在同一个网段下,然后打开Fidder,然后打开app中的英雄界面,Fidder配置正确的情况下,会看到对应的数据的刷新,然后点开对应的信息,查看URL,我这边获取的URL是‘
start_urls = ['http://gamehelper.gm825.com/wzry/hero/list?channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=13.0.4.0&version_code=13040&cuid=8025FD949C93FC66D1DDB6BAC65203D7&ovr=8.0.0&device=Xiaomi_MI+6&net_type=1&client_id=&info_ms=&info_ma=xA9SDhIYZnQ7DOL9HYU%2FDTmfXcpNZC9piF6I%2BbRM5q4%3D&mno=0&info_la=jUm4EMrshA%2BjgQriNYPOaw%3D%3D&info_ci=jUm4EMrshA%2BjgQriNYPOaw%3D%3D&mcc=0&clientversion=13.0.4.0&bssid=9XEEdN1xCIRfdgHQ8NQ4DlZl%2By%2BL8gXiWPRLzJYCKss%3D&os_level=26&os_id=0d62e3f861713d92&resolution=1080_1920&dpi=480&client_ip=192.168.1.61&pdunid=bbbb5488']
’
读者也可以直接使用我的接口。
3.在item.py中写需要获取的数据
import scrapy
class WangzSpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()4.编写爬虫获取页面内容
import scrapy
from scrapy import Request
import json
import os
from WangZ_Spider.items import WangzSpiderItem
class SpiderSpider(scrapy.Spider):
name = 'spider'
#allowed_domains = ['wanz.com']
start_urls = ['http://gamehelper.gm825.com/wzry/hero/list?channel_id=90009a&app_id=h9044j&game_id=7622&game_name=%E7%8E%8B%E8%80%85%E8%8D%A3%E8%80%80&vcode=13.0.4.0&version_code=13040&cuid=8025FD949C93FC66D1DDB6BAC65203D7&ovr=8.0.0&device=Xiaomi_MI+6&net_type=1&client_id=&info_ms=&info_ma=xA9SDhIYZnQ7DOL9HYU%2FDTmfXcpNZC9piF6I%2BbRM5q4%3D&mno=0&info_la=jUm4EMrshA%2BjgQriNYPOaw%3D%3D&info_ci=jUm4EMrshA%2BjgQriNYPOaw%3D%3D&mcc=0&clientversion=13.0.4.0&bssid=9XEEdN1xCIRfdgHQ8NQ4DlZl%2By%2BL8gXiWPRLzJYCKss%3D&os_level=26&os_id=0d62e3f861713d92&resolution=1080_1920&dpi=480&client_ip=192.168.1.61&pdunid=bbbb5488']
item = WangzSpiderItem()
headers = {
'Accept - Charset': 'UTF-8;',
'Accept - Encoding': 'gzip, deflate',
'Content - type' :'application/ x-www-form-urlencoded',
'X-Requested-With': 'XMLHttpRequest',
'User - Agent': 'Dalvik/2.1.0(Linux;U;Android 8.0.0;MI 6 MIUI/V10.0.2.0.OCACNFH)',
'Host': 'gamehelper.gm825.com',
'Connection': 'Keep - Alive',
}
def parse(self, response):
yield Request(url=self.start_urls[0],headers=self.headers,method='GET',callback=self.get_data)
def get_data(self,response):
print(response.text)先别执行,搞过scrapy的都知道直接在命令行里输入scrapy crawl spider就可以运行,这次我们搞一个点一下就能运行的
4.创建start.py
文件创建在和工程文件的同级目录,错了就不能玩儿了,然后在文件里写一行代码
from scrapy import cmdline
cmdline.execute('scrapy crawl spider'.split())然后点开Run->edit->+->pthon->打开对应的start文件。
然后点击右上角的绿色箭头,就跑起来了,这是侯你应该可以看到页面的输出信息一堆的str数据
5.整理数据
把str的数据转换成json然后转成字典,这样我们获取的时候也很方便,上货
def get_data(self,response):
print(response.text)
result = json.loads(response.text)
print(result)
result = dict(result)
print(result)
result = result["list"]
print(len(result))
ids = [result[id]["cover"] for id in range(0,len(result))]
names = [result[id]["name"] for id in range(0,len(result))]
hero_ids = [result[id]['hero_id'] for id in range(0,len(result))]
print(ids)
print(names)
print(hero_ids)
self.item['image_urls'] = ids
self.item['images'] = names
yield self.item这样爬虫部分也就结束了。
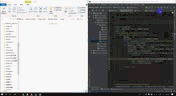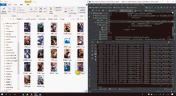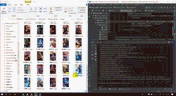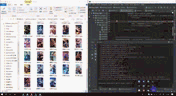
6,图片下载
数据分出来之后,看到的是一堆的http://...........png的东西,其实已经成功了,这个就是图片了,接下来要做的就是把他们下载下来就好了。
首先需要设置下settings.py文件
ITEM_PIPELINES = {
'WangZ_Spider.pipelines.WangzSpiderPipeline': 300,
}
IMAGE_STORE = 'E:/python_project/King_Fight/WangZ_Spider/Image'
IMAGE_URLS_FILE = 'image_urls'
IMAGE_RESULT_FILED = 'images'
IMAGE_THUMBS = {
'small':(80,80),
'big':(240,240),
}然后编写pipline.py将图片下载下来
import requests
from .settings import IMAGE_STORE
import os
class WangzSpiderPipeline(object):
def process_item(self, item, spider):
images = []
dir_path = '{}'.format(IMAGE_STORE)
if not os.path.exists(dir_path) and len(item['src']) != 0:
os.mkdir(dir_path)
for jpg_url, name, num in zip(item['image_urls'], item['images'], range(0, 100)):
file_name = name + str(num)
file_path = '{}//{}'.format(dir_path, file_name)
images.append(file_path)
if os.path.exists(file_path) or os.path.exists(file_name):
continue
with open('{}//{}.png'.format(dir_path, file_name), 'wb') as f:
req = requests.get(url=jpg_url)
f.write(req.content)
return item
接下来结果展示