打开淘宝,我们搜索手机,返回以下界面
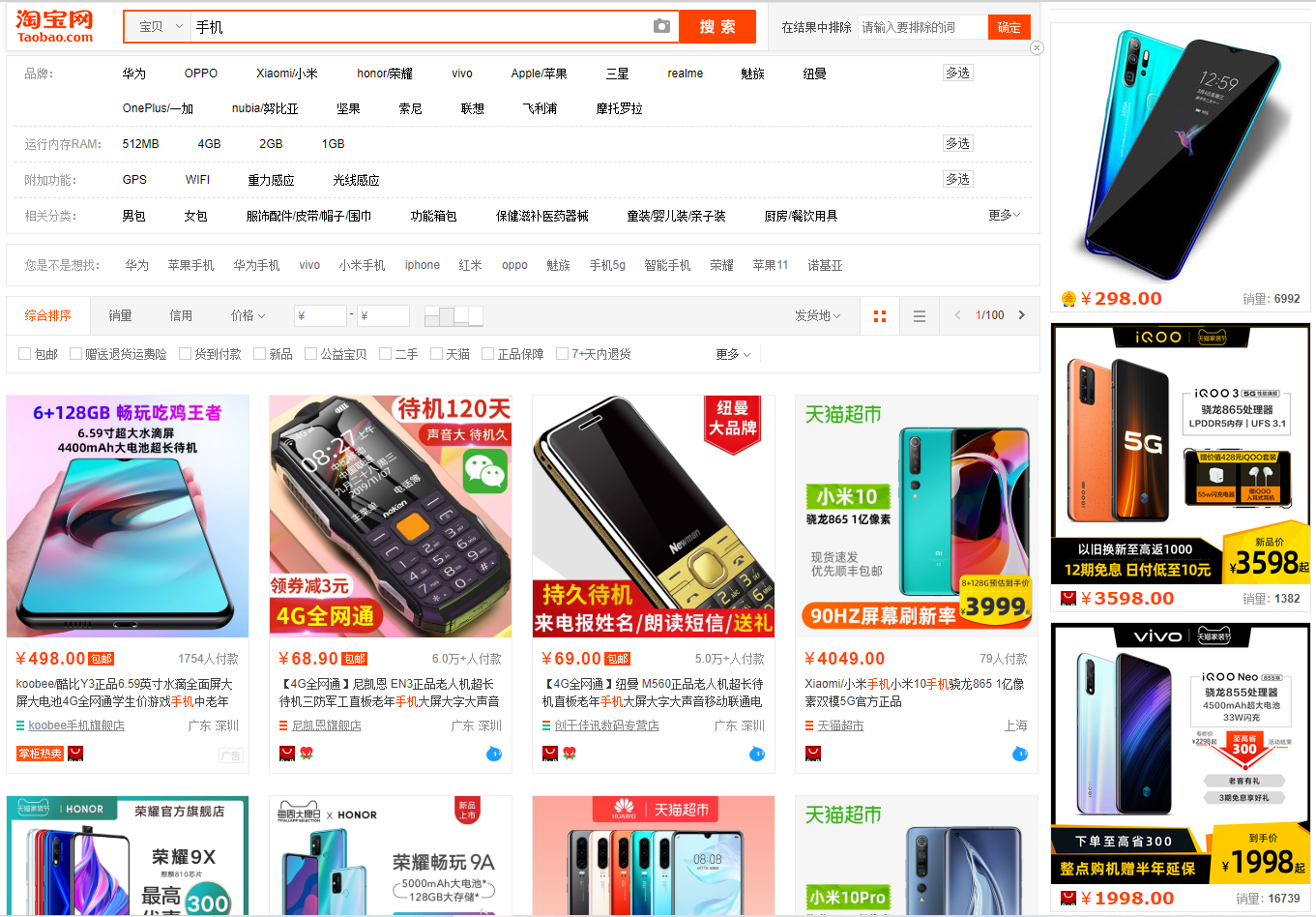
接下来我们来爬取这些数据

第一步我们先获取网页html
html = requests.get(url,headers=headers) print(html.text)
将结果打印后发现所需要的信息在网页代码中没有,所以它应该是动态加载的,这里再network中一个一个找,找到它返回的json文件,就是这样的。

最后可以发现内容都在一个json文件中,到这里接下来的就很简单了,我们只需要解析json找我我们需要的数据就可以了,将这一部分封装起来。
def get_data(url):
html = requests.get(url,headers=headers,)
html_text = html.text
starts = html_text.find('{"pageName":"mainsrp"')
end = html_text.find('"shopcardOff":true}}')+len('"shopcardOff":true}}')
json_data = json.loads(html_text[starts:end])
get_json_data = json_data['mods']['itemlist']['data']['auctions']
for data in get_json_data:
title = data['title']
item_loc = data['item_loc']
view_sales = data['view_sales']
nick = data['nick']
view_price = data['view_price']
pic_url = data['pic_url']
pic_url = parse.urljoin('http:',pic_url)
print(title,'\n',item_loc,'\n',view_sales,'店铺:',nick,"价格:",view_price)
download(pic_url)
print('-'*80)
结果如下
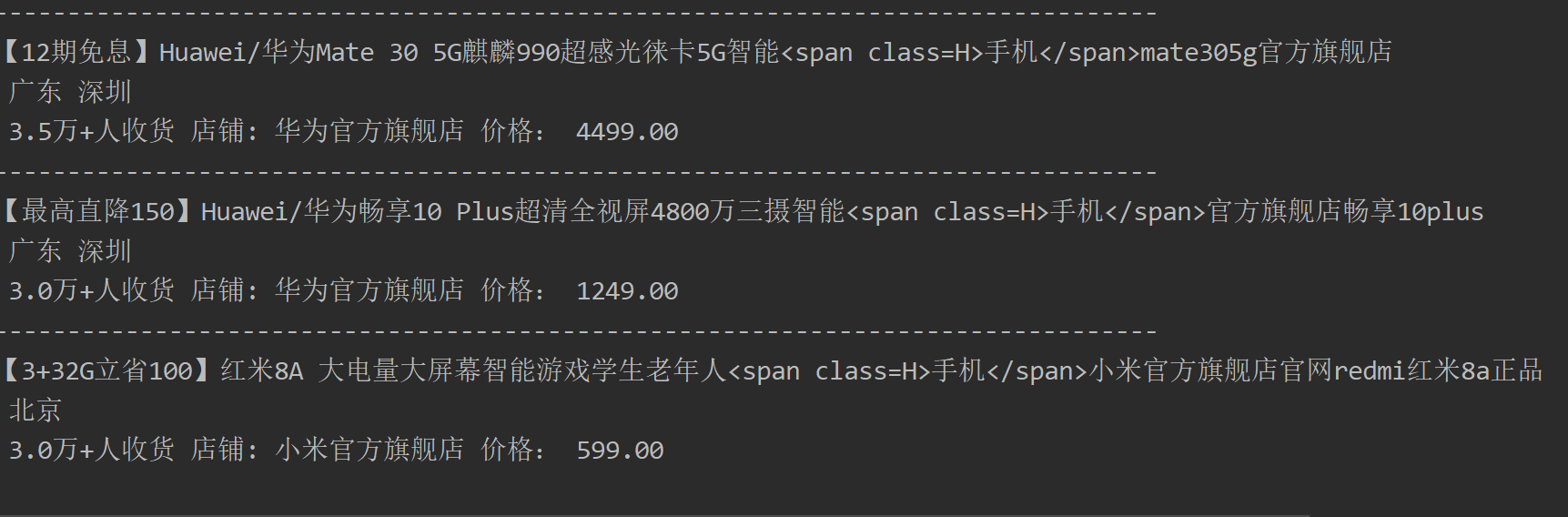
这里我们就将一页的爬完了,这里我们尝试将所有的都爬下来,这里我们点击第二页
可以看到下一页的url为上一页中s+44这样我们就可以爬下一页了
1 for each in range(0,1000,44): 2 url = 'https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&sort=sale-desc&bcoffset=0&p4ppushleft=%2C44&s={}'.format(each)
OK全部解决
完整代码如下:
1 import requests,json,lxml,os 2 from lxml import etree 3 from urllib import parse 4 from uuid import uuid4 5 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36 Edg/80.0.361.69' 6 ,'cookie':自己的cookie 7 } 8 def get_data(url): 9 html = requests.get(url,headers=headers,) 10 html_text = html.text 11 starts = html_text.find('{"pageName":"mainsrp"') 12 end = html_text.find('"shopcardOff":true}}')+len('"shopcardOff":true}}') 13 json_data = json.loads(html_text[starts:end]) 14 get_json_data = json_data['mods']['itemlist']['data']['auctions'] 15 for data in get_json_data: 16 title = data['title'] 17 item_loc = data['item_loc'] 18 view_sales = data['view_sales'] 19 nick = data['nick'] 20 view_price = data['view_price'] 21 pic_url = data['pic_url'] 22 pic_url = parse.urljoin('http:',pic_url) 23 print(title,'\n',item_loc,'\n',view_sales,'店铺:',nick,"价格:",view_price) 24 download(pic_url) 25 print('-'*80) 26 27 def download(url): 28 response = requests.get(url) 29 img = response.content 30 with open('文件路径{}.jpg'.format(uuid4()),'wb') as f: 31 f.write(img) 32 33 34 if __name__ == '__main__': 35 for each in range(0,1000,44): 36 url = 'https://s.taobao.com/search?q=%E6%89%8B%E6%9C%BA&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&sort=sale-desc&bcoffset=0&p4ppushleft=%2C44&s={}'.format(each) 37 38 get_data(url)