开篇
做论文的时候,最多接触的就是标准的数据集,几乎不需要太多的结构化处理,下载下来就是可以直接加载使用的数据,课题是有关评论分析的,但是论文针对的都是英文数据,而国内电商平台其实积累了大量的评论数据,没有办法通过官方渠道获取,那么我们就写个爬虫自己爬吧,我没有系统地学过爬虫,所以挑了一个比较好爬的网站。
获取评论存储的地址
首先我们选择一个想要爬取的商品,打开它的网址,这边我选择的是iphone8的手机评论
这里最好使用谷歌浏览器,接下来就是需要我们去获取评论的存储网页啦,我们右击网页,点击检查,这时候会出现京东网页的代码。
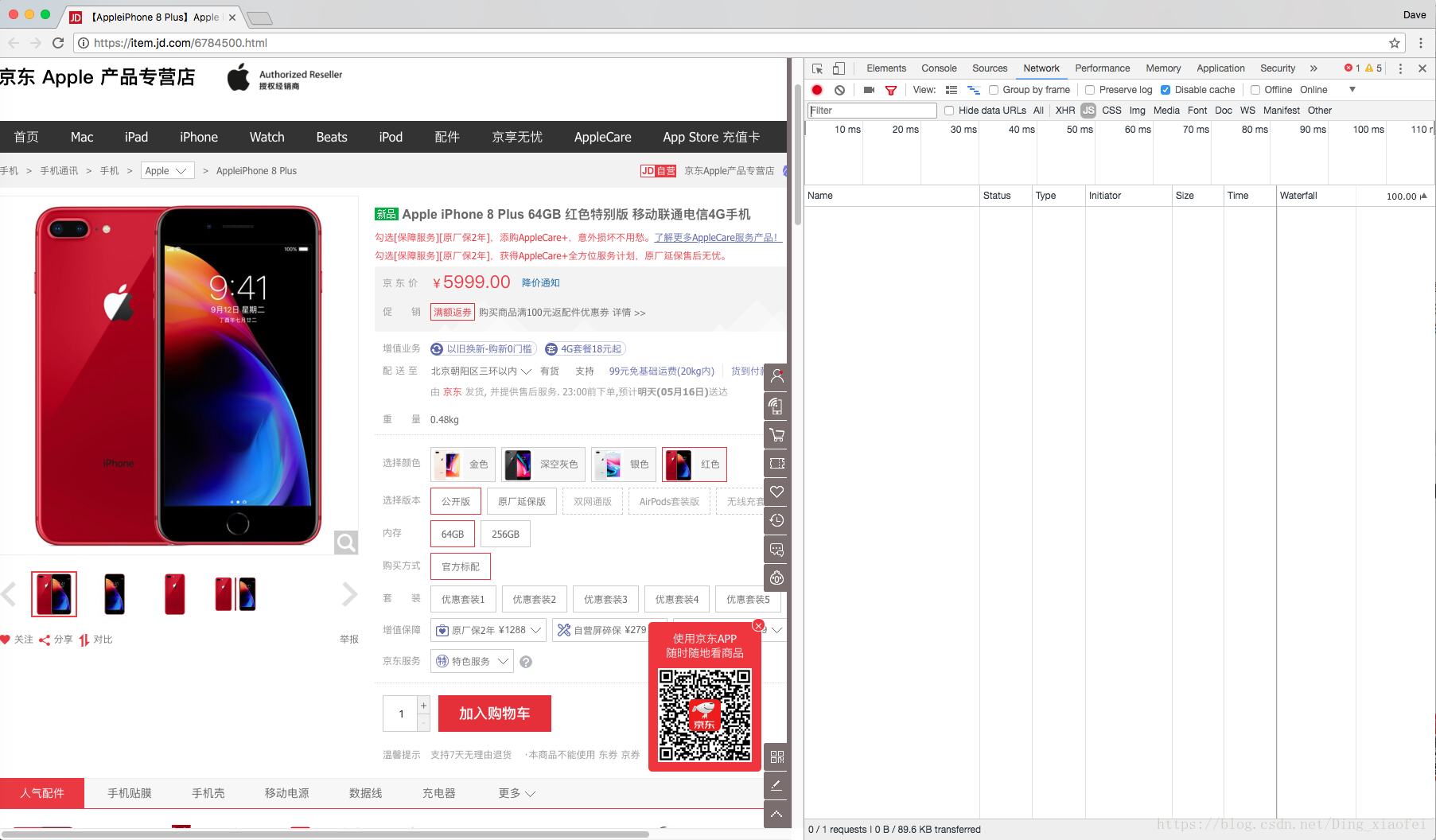
点击network,将disable cache选上,我们主要要查找js网页,所以点上js,这时候你查找什么网页都没有,所以刷新一下网页
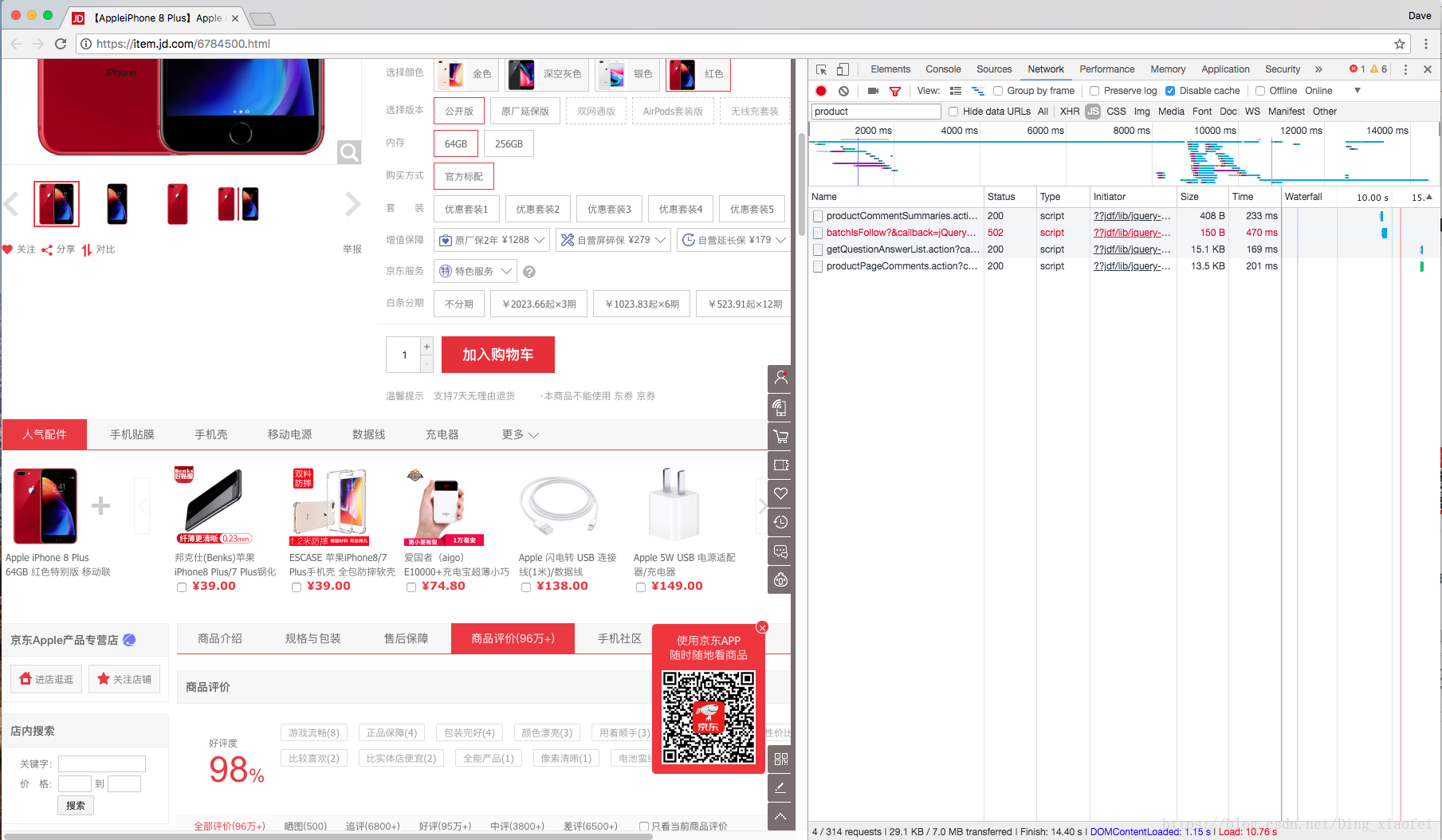
这时候嵌套的网页就全出来了,这时候你输入product
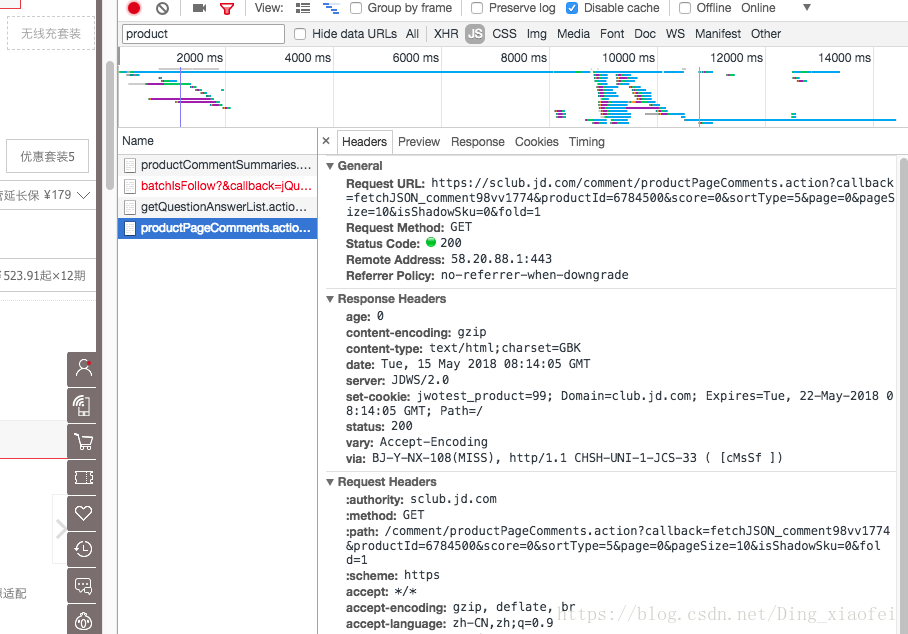
这下就找到我们要爬取的网页了。复制它的request url的地址放到地址栏里面打开。

网页打开后就是这样的,这就是我们需要爬取的内容,里面囊括了我们需要的评论信息,是以json的格式存储的。有了地址我们就可以用python把它们一个个抓下来。下面是代码
# -*- coding: utf-8 -*-
import urllib.request
import json
import time
import random
def crawlProductComment(url):
#读取原始数据(注意选择gbk编码方式)
html = urllib.request.urlopen(url).read().decode('gbk')
#从原始数据中提取出JSON格式数据(分别以'{'和'}'作为开始和结束标志)
jsondata = html[27:-2]
#print(jsondata)
data = json.loads(jsondata)
#print(data['comments'])
#print(data['comments'][0]['content'])
#遍历商品评论列表
comments = data['comments']
return comments
data = []
for i in range(0,350):
#iphone8评论链接,通过更改page参数的值来循环读取多页评论信息
url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv89597&productId=5001175&score=0&sortType=5&page=' + str(i) +'&pageSize=10&isShadowSku=0&fold=1'
comments = crawlProductComment(url)
data.extend(comments)
#设置休眠时间
time.sleep(random.randint(31,33))
print('-------',i)
with open('xiaomi_note_3.json','w') as f:
json.dump(data,f)