2019-04-08 13:25:17
在实践中,很少有人从头开始训练整个卷积网络(随机初始化),因为拥有足够大小的数据集是相对罕见的。相反,通常在非常大的数据集(例如ImageNet,其包含具有1000个类别的120万个图像)上预先训练ConvNet,然后使用预训练好的ConvNet作为感兴趣的任务的参数初始化或固定特征提取器。目前主要有种种Transfer Learning方案如下:
- 将ConvNet作为固定的特征提取器
在ImageNet上预先训练一个ConvNet,删除最后一个完全连接的层(该层的输出是ImageNet等不同任务的1000个类别分数),然后将其余的ConvNet视为新数据集的固定特征提取器。
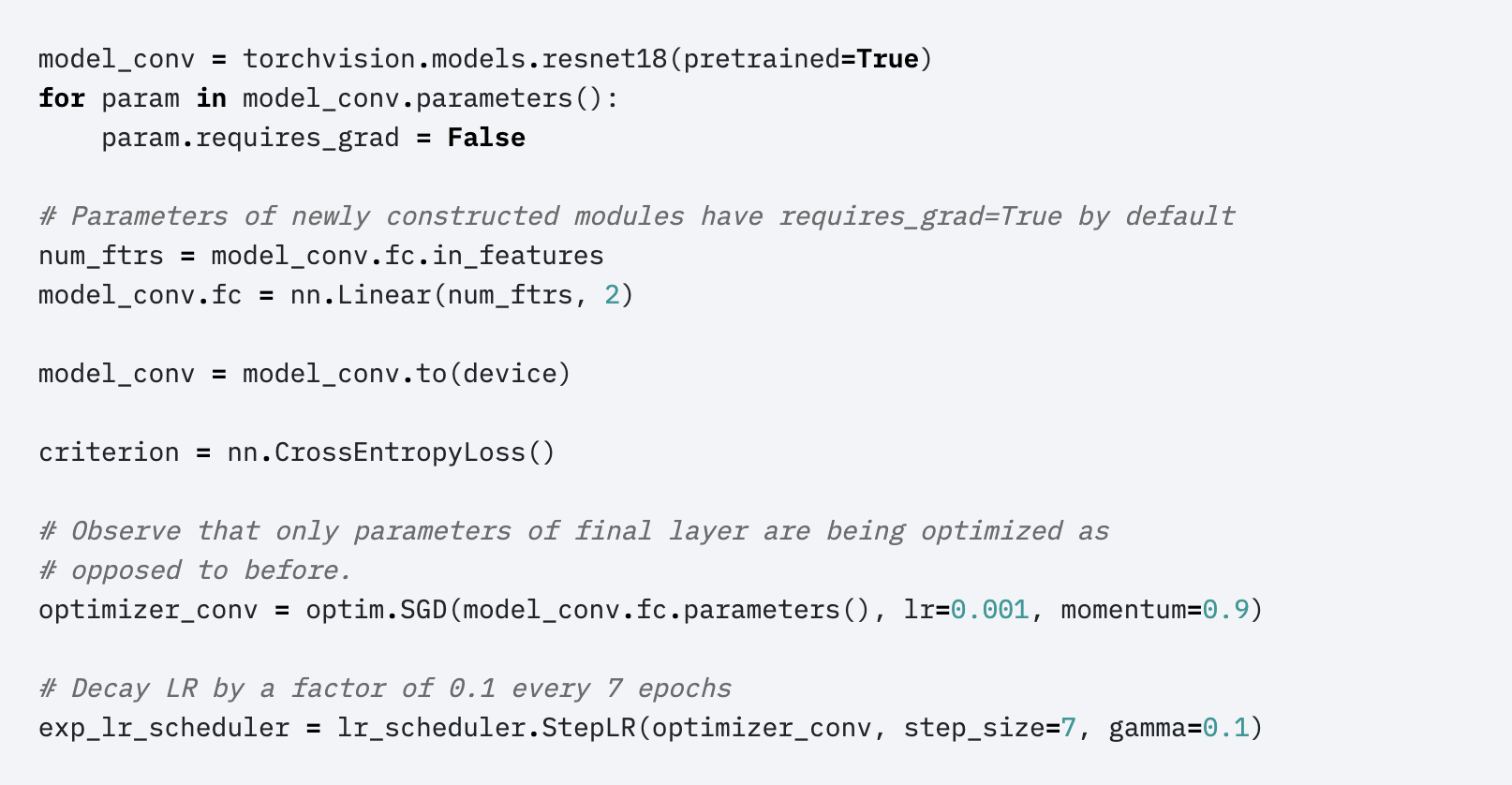
- 微调ConvNet
我们使用预训练网络初始化网络,而不是随机初始化,就像在imagenet 1000数据集上训练的网络一样。 其余训练看起来像往常一样。
具体来说不仅在新数据集上替换和重新训练ConvNet之上的分类器,而且还通过继续反向传播来微调预训练网络的权重。 可以微调ConvNet的所有层,或者可以保留一些早期层(由于过度拟合问题)并且仅微调网络的某些更高级别部分。 这是因为观察到ConvNet的早期特征包含更多通用特征(例如边缘检测器或颜色斑点检测器),这些特征应该对许多任务有用,但后来的ConvNet层逐渐变得更加特定于类的细节。 包含在原始数据集中。 例如,对于包含许多犬种的ImageNet,ConvNet的代表性功能的很大一部分可以用于特定于区分狗品种的特征。