最近对迁移学习比较感兴趣,连续读了几篇和迁移学习相关的文章。本次博客首先来总结几篇迁移学习在NLP领域的应用。
NIPS(美国高级研究计划局)2005年给迁移学习一个比价有代表性的解释:transfer learning emphasizes the transfer of knowledge across domains, tasks, and distributions that are similar but not the same。总的来说,我感觉迁移学习更像是一种思想,所谓“迁移”的含义,就是使用其他领域(也叫做source领域)的知识来帮助目标领域(也叫做target领域)的学习。根据迁移学习具体不同的实现方法,迁移学习可以分为:1 基于样本的学习;2 基于特征的学习;3 基于参数的学习;4 基于相关性的学习。
一般来说,在NLP领域最常用的方法就是基于参数的学习,即在不同的任务领域中共享网络结构。最简单的迁移学习就是pre-training策略(比方说word2vec),即把无监督生成的词向量直接迁移到其他的有监督的任务中去,包括之前博客中提到的multi-task方法,其实都运用到了迁移学习的思想。
今天要介绍的第一篇paper题目叫做《Universal Language Model Fine-tuning for Text Classification》来自于2018年的ACL。整个模型如下图所示:
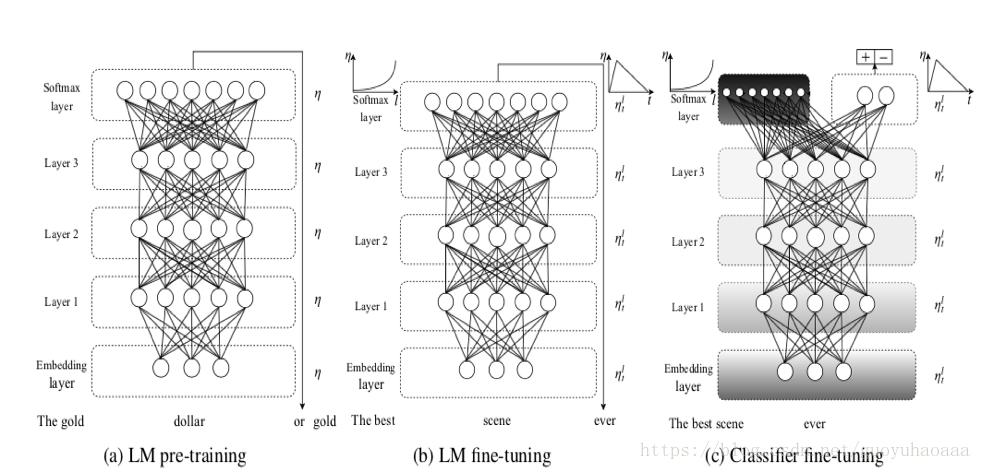
其中的LM指代的就是Language Model,其实就是简单的多层LSTM网络(图中的实例是三层)。这个论文所说的迁移学习体现在两个方面:1 不同任务的迁移学习(LM和Classification);2 不同domain数据的迁移学习(图中的LM pre-training 和 LM fine-tuning)
可以看出整个模型框架分为了三个阶段:
a) LM pre-training。在该阶段就是使用不同domain中的数据进行预训练;
b) LM fine-tuning。在该阶段就是是使用目标domain中的数据进行整个网络的fine-tuning操作,但是作者在该阶段fine-tuning的时候采用了2种策略:
1 Discriminative fine-tuning,即对layer1,layer2和layer3采用不同的学习速率,layer3是最后一层学习速率为
,那么layer2 的学习速率就是
,layer3的学习速率就是
;
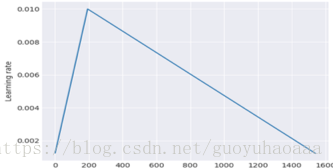
2 Slanted triangular learning rates,因为神经网络的训练都是以epoch为单位进行的,这种方法就是每一个epoch都会对学习速率有一个修正,具体的修正公式如下:
其中,T是总的迭代次数,t是当前的迭代次数,
是转折比例,
是最大的学习速率。整个学习速率的图像如下所示:
c) Classifier fine-tuning。可以看出,在该阶段就是使用domain中的有标注数据进行分类器的训练,就是把layer3的LSTM的输出变量进行一系列的变换操作,最后输入分类器的形式就是
,
就是最后一时刻的输出向量,那么在对分类器进行训练的时候,除了Discriminative fine-tuning和Slanted triangular learning rates技术。为了避免全部fine-tuning导致网络对之前学到的general知识的遗忘,还使用了一种被称之为Gradual unfreezing的方法,从后往前(从layer3到layer1方向)以epoch为单位进行逐步的添加。第一个epoch只把最后一层解冻,接下来每过一个epoch就把一个多余的网络层加入到解冻集合中去。由于后面的网络更多的是specific信息,前面的网络包含的更多general信息,这样的方式可以最大的幅度保存(a)、(b)阶段学习到的信息。
其实整个模型是比价简单、清晰的,作者最大的贡献在于其提出了Discriminative fine-tuning、Slanted triangular learning rates和Gradual unfreezing这三种训练技巧。
第二篇介绍的论文题目叫做《Learned in Translation: Contextualized Word Vectors》,发表在了2017年的NIPS上。它也运用到了迁移学习思想,整个思想模式如下所示:
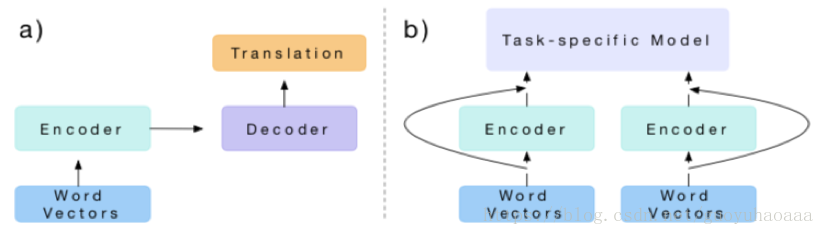
其实思想很简单,主要运用到了不同任务的迁移方法,a图代表的是source任务,b代表的是target任务。从图中就可以看到a图就是一个机器翻译的模型,b图利用了a任务下训练出来的encoder进行进一步的task-specific的训练。
下面先来讲一下a任务的具体方法,假设源句子序列为
,目标句子序列
,使用
代表
词序列的Glove向量表示,在encoder使用的是2层的bi-LSTM称之为MT-LSTM,即
。在decoder中使用的是2层单向的LSTM,其预测计算公式如下:
那么对于t时刻目标的输出就是:
。
当使用机器翻译场景的数据预训练出encoder-decoder的模型参数后,使用encoder对原始句子的词向量重新进行编码,即CoVe(w)=MT-LSTM(GloVe(w)),然后把CoVe(w)和GloVe(w)向量拼接构成输入task-specific的词向量,即[GloVe(w);CoVe(w)]。
接下来的所有各种task-specific任务都是基于task-specfic生成的拼接词向量,这就是构词了迁移学习的参数共享部分。
第三篇介绍的论文叫做《Deep contextualized word representations》,发表在了2018年的ACL会议上。其实这个论文和第一篇介绍的有点相似,都是把在语言模型中训练出度模型参数迁移到其他的下游任务中。整个模型的结构就是多层的双向LSTM,对应的两个方向的语言模型公式如下所示:
由于两个方向的LSTM是独立的参数,因此在优化模型的时候采用联合优化的方式:
从公式中可以看出,前后两个方向上的词向量表征和最后预测输出的softmax的参数是共享的,当预训练好之后。每一个词,就会对应1+2L个向量表征(1是本身,L是LSTM的层数,2则代表了2个方向)。令
表征第k个词在第j层的对应的两个LSTM输出的拼接,作者给那么这个词k对应所有L层的词向量起了一个名字叫做
。把这个词向量抽出来作为词k的表征,运用到其他的下游具体任务中去,实验证明能取得不错的效果。
其实上面这三篇迁移学习在词向量中应用的paper思想是非常一致的,相对于仅仅使用传统的一层的word embedding方法(word2vec、Glove等),在这些场景中迁移的参数是比较多的。Sebastian Ruder提到“词嵌已死,语言模型当立”,也就是说以后我们在NLP领域预训练迁移的参数不仅仅是词向量这些简单的参数了,可以把训练过程中用到的语言模型建模部分的参数也迁移过来。这个就像是ImageNet在图像处理领域中的地位一样,其他所有在图像领域的任务都可以用ImageNet作为预训练参数的数据集,这样所有其他任务模型在训练的时候,初始参数就不再是从随机开始了,而是从一些有意义的值开始。
第四篇介绍的论文叫做《How transferable are features in deep neural networks?》,发表在了2014年的NIPS会议上。这篇paper主要目的就是为了探究在图像识别领域中,迁移学习在网络中的特征到底是如何从general变成specific的,这个变化是渐变的还是突变的。整个对比实验的模型如下所示:
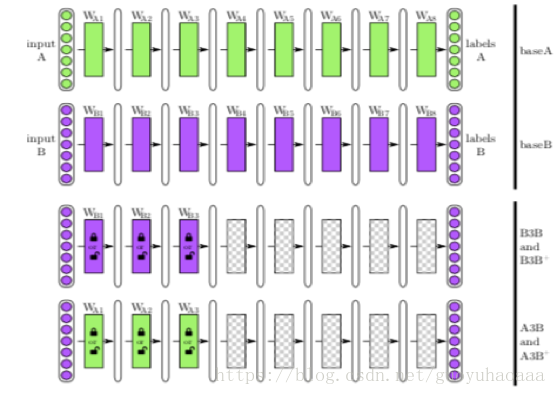
整个实验在A和B两个数据集上进行验证,第一行和第二行就是直接使用模型对A和B分别进行训练;第三行指的是针对同一数据集进行部分网络的迁移测试,即把A数据训练好的x模型中的前三层,直接初始化给另一个网络y,然后对y再使用A数据进行训练,而迁移过去的前三层网络参数在模型y的训练保持固定或者随着模型一起训练;第四行和第三行操作方式非常相似,只不过在进行模型y训练的时候用的数据是B数据。得到的结果如下所示:
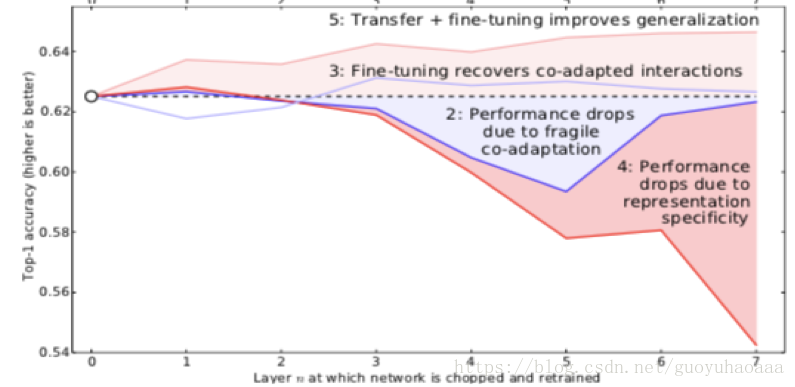
虚线是baseline,深红代表AB+,浅红代表AB,深蓝代表BB,浅蓝代表BB+。有+代表了fine-tuning,反之则代表了固定,横轴代表了迁移的层数。
通过上述的对比实验,就可以验证出在迁移学习场景下,模型到底是如何进行训练的。最终通过大量的实验,作者得出了如下结论:
1 一个网络结构的预测结果其实是网络中所有参数相互作用的结果,如果强行固定网络中的一部分参数,这样就会破坏了参数之间的相互协作,不利于准确率的提升;(在第三行的实验中发现,即使同一份数据B固定前n层参数训练下的y性能相比x都会下降,说明网络中的参数确实存在相互作用);
2 网络前半部分学到的是general信息,后半部分学的是specific信息,中间会逐渐转换;
3 即使target数据集足够大,不会产生过拟合现象,合理的使用source数据依然能够对最终准确率的提升有帮助。