深度学习中在计算机视觉任务和自然语言处理任务中将预训练的模型作为新模型的起点是一种常用的方法,通常这些预训练的模型在开发神经网络的时候已经消耗了巨大的时间资源和计算资源,迁移学习可以将已习得的强大技能迁移到相关的的问题上。
什么是迁移学习?
迁移学习(Transfer Learning)是一种机器学习方法,是把一个领域(源领域)的知识,迁移到另外一个领域(目标领域),使得目标领域能够取得更好的学习效果。
通常,源领域数据量充足,而目标领域数据量较小,这种场景就很适合做迁移学习,例如我们我们要对一个任务进行分类,但是此任务中数据不充足(目标域),然而却又大量的相关的训练数据(源域),但是此训练数据与所需进行的分类任务中的测试数据特征分布不同(例如语音情感识别中,一种语言的语音数据充足,然而所需进行分类任务的情感数据却极度缺乏),在这种情况下如果可以采用合适的迁移学习方法则可以大大提高样本不充足任务的分类识别结果。
为什么需要进行迁移学习?
1. 目标域数据量较小或者数据的标签很难获取,可以通过数据量充足或者容易获取标签且和该任务相似的任务(源域)来迁移学习。
2. 从头建立模型复杂且耗时,通过迁移学习可以加快学习效率。
如何使用迁移学习?
可以在自己预测模型问题上使用迁移学习,常用的2个方法:
1. 开发模型的方法 - 自主训练源模型并将模型迁移应用到其他类似目标任务
(1)选择源任务。你必须选择一个具有丰富数据的相关的预测建模问题,原任务和目标任务的输入数据、输出数据以及从输入数据和输出数据之间的映射中学到的概念之间有某种关系。
(2)开发源模型。然后,你必须为第一个任务开发一个精巧的模型。这个模型一定要比普通的模型更好,以保证一些特征学习可以被执行。
(3)重用模型。然后,适用于源任务的模型可以被作为目标任务的学习起点。这可能将会涉及到全部或者部分使用第一个模型,这依赖于所用的建模技术。
(4)调整模型。模型可以在目标数据集中的输入-输出对上选择性地进行微调,以让它适应目标任务。
2. 预训练模型方法 - 基于别人(权威研究机构)发布的模型迁移到自己的目标任务 (常用)
(1)选择源模型。一个预训练的源模型是从可用模型中挑选出来的。很多研究机构都发布了基于超大数据集的模型,这些都可以作为源模型的备选者。
(2)重用模型。选择的预训练模型可以作为用于第二个任务的模型的学习起点。这可能涉及到全部或者部分使用与训练模型,取决于所用的模型训练技术。
(3)调整模型。模型可以在目标数据集中的输入-输出对上选择性地进行微调,以让它适应目标任务。
其中,第2种类型的迁移学习在深度学习领域比较常用。比如 基于ImageNet的图片分类任务,根据google已经训练好的Inception_v3模型,完全可以迁移到自己的图片分类任务中,比如自定义识别绿萝和吊兰,只需添加少量的有关绿萝和吊兰的图片(不能太少!最好各40张以上),就可以很快的训练出自己的模型,识别准确率95%以上。(只是举个最简单的例子,实际中,“坑”还是有的。。)
传统的机器学习与迁移学习有什么不同呢?
在机器学习的监督学习场景中,如果我们要针对一些任务和域 A 训练一个模型,我们会假设被提供了针对同一个域和任务的标签数据。如下图所示,其中我们的模型 A 在训练数据和测试数据中的域和任务都是一样的。
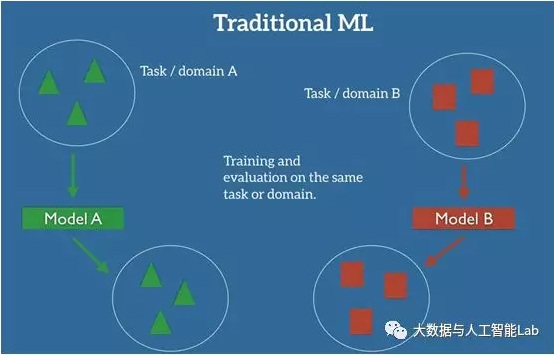
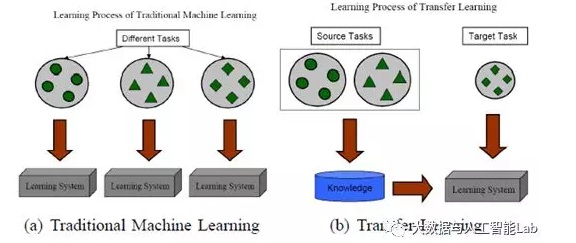
即使是跟迁移学习比较相似的多任务学习,多任务学习是对目标域和源域进行共同学习,而迁移学习主要是对通过对源域的学习解决目标域的识别任务。下图就展示了传统的机器学习方法与迁移学习的区别:
什么适合迁移?
在一些学习任务中有一些特征是个体所特有的,这些特征不可以迁移。而有些特征是在所有的个体中具有贡献的,这些可以进行迁移。
有些时候如果迁移的不合适则会导致负迁移,例如当源域和目标域的任务毫不相关时有可能会导致负迁移。
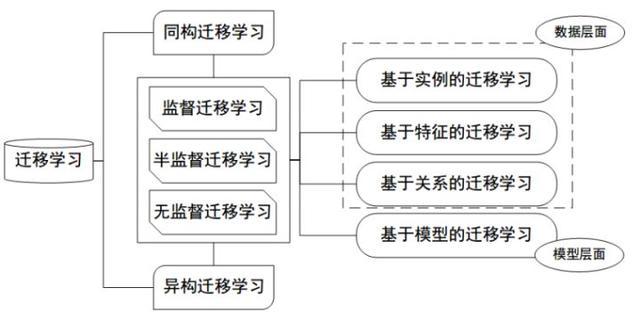
迁移学习的分类
根据 Sinno Jialin Pan 和 Qiang Yang 在 TKDE 2010 上的文章,可将迁移学习算法,根据所要迁移的知识表示形式(即 “what to transfer”),分为四大类:
- 基于实例的迁移学习(instance-based transfer learning):源领域(source domain)中的数据(data)的某一部分可以通过reweighting的方法重用,用于target domain的学习。
- 基于特征表示的迁移学习(feature-representation transfer learning):通过source domain学习一个好的(good)的特征表示,把知识通过特征的形式进行编码,并从suorce domain传递到target domain,提升target domain任务效果。
- 基于参数(模型)的迁移学习(parameter-transfer learning):target domain和source domian的任务之间共享相同的模型参数(model parameters)或者是服从相同的先验分布(prior distribution)。
- 基于关系知识迁移学习(relational-knowledge transfer learning):相关领域之间的知识迁移,假设source domain和target domain中,数据(data)之间联系关系是相同的。
前三类迁移学习方式都要求数据(data)独立同分布假设。同时,四类迁移学习方式都要求选择的source domain与target domain相关,
具体描述如下(按照迁移学习基本方法):
(1)基于实例的迁移学习方法
在源域中找到与目标域相似的数据,把这个数据的权值进行调整,使得新的数据与目标域的数据进行匹配。然后进行训练学习,得到适用于目标域的模型。这样的方法优点是方法简单,实现容易。缺点在于权重的选择与相似度的度量依赖经验,且源域与目标域的数据分布往往不同。

(2)基于特征的迁移学习方法
当源域和目标域含有一些共同的交叉特征时,我们可以通过特征变换,将源域和目标域的特征变换到相同空间,使得该空间中源域数据与目标域数据具有相同分布的数据分布,然后进行传统的机器学习。优点是对大多数方法适用,效果较好。缺点在于难于求解,容易发生过适配。

需要注意的的是基于特征的迁移学习方法和基于实例的迁移学习方法的不同是基于特征的迁移学习需要进行特征变换来使得源域和目标域数据到到同一特征空间,而基于实例的迁移学习只是从实际数据中进行选择来得到与目标域相似的部分数据,然后直接学习。
(3)基于模型的迁移学习方法
源域和目标域共享模型参数,也就是将之前在源域中通过大量数据训练好的模型应用到目标域上进行预测。基于模型的迁移学习方法比较直接,这样的方法优点是可以充分利用模型之间存在的相似性。缺点在于模型参数不易收敛。
举个例子:比如利用上千万的图象来训练好一个图象识别的系统,当我们遇到一个新的图象领域问题的时候,就不用再去找几千万个图象来训练了,只需把原来训练好的模型迁移到新的领域,在新的领域往往只需几万张图片就够,同样可以得到很高的精度。
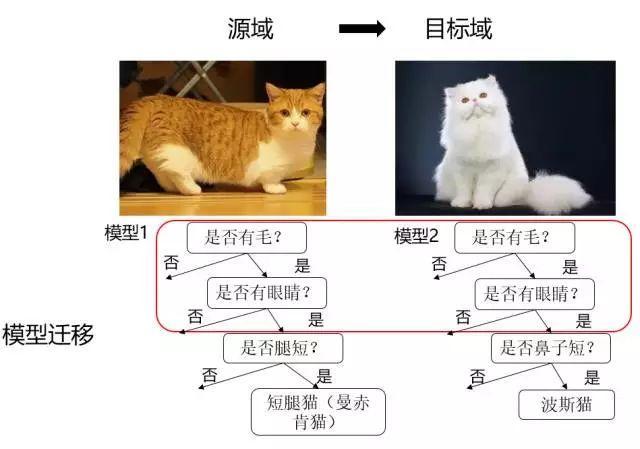
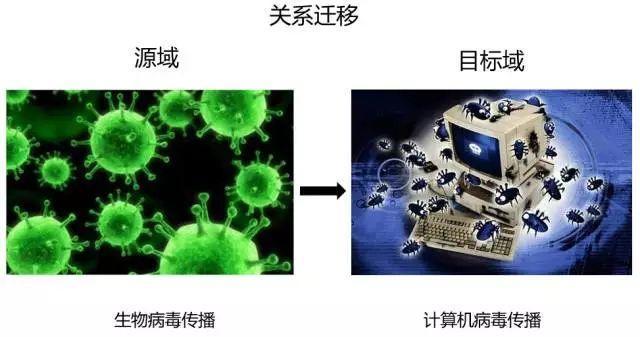
(4)基于关系的迁移学习方法
当两个域是相似的时候,那么它们之间会共享某种相似关系,将源域中学习到的逻辑网络关系应用到目标域上来进行迁移,比方说生物病毒传播规律到计算机病毒传播规律的迁移。这部分的研究工作比较少。典型方法就是mapping的方法
下图来总结以上的知识(可以看成归纳式迁移学习是最广泛应用的):

另外,如果按特征空间,可分为:
同构迁移学习(Homogeneous TL): 源域和目标域的特征维度相同分布不同
异构迁移学习(Heterogeneous TL):源域和目标域的特征空间不同
下图作为迁移学习分类的一个梳理:
迁移学习的应用
用于情感分类,图像分类,命名实体识别,WiFi信号定位,自动化设计,中文到英文翻译等问题。
迁移学习的价值
- 复用现有知识域数据,已有的大量工作不至于完全丢弃;
- 不需要再去花费巨大代价去重新采集和标定庞大的新数据集,也有可能数据根本无法获取;
- 对于快速出现的新领域,能够快速迁移和应用,体现时效性优势。
整理参考链接如下:
http://cs231n.github.io/transfer-learning/
http://yosinski.com/transfer
https://my.oschina.net/u/876354/blog/1614883
http://baijiahao.baidu.com/s?id=1590903538875880299&wfr=spider&for=pc
http://www.ijiandao.com/2b/baijia/86640.html