文章目录
一、概要
背景:机器学习(ML)已成为从自动驾驶到认证系统等各种关键应用的基石。然而,随着机器学习模型采用率的提高,出现了多种攻击。
一类此类攻击是训练时间攻击,对手在机器学习模型训练之前或期间执行攻击。
我们提出了一种针对基于计算机视觉的机器学习模型的新的训练时间攻击,即模型劫持攻击。
model hijacking attacks:adversary 试图是 劫持 一个目标模型(target model),在原拥有者不注意的时候 执行 与原始模型(original model)不同的任务。
模型劫持攻击 要求 隐蔽性, 即用于劫持目标模型的数据样本应该与 模型的原始训练数据集相似。
为此,提出了两种不同的模型劫持攻击, 即变色龙和反向变色龙。(基于一种新的编码器-解码器风格的ML模型,即伪装器)
二、介绍Introduction
对数据和计算能力的高要求, 个体很难满足, 许多新型训练模式被提出, 典型例子是 联邦学习。 但是会产生新的安全问题, 创造了一种可能, 敌方能够在操纵ML模型训练。 (后门攻击和数据中毒)
模型劫持攻击
- 不危害目标模型 相对于 其原始任务的效用。
- 伪装中毒数据,使其看起来类似于来自目标模型训练数据集相同分布的数据。
地方只需要 能够 毒害 目标模型的训练数据集。(地方利用自己的劫持任务数据集来 毒害 目标模型训练数据集,但是仅仅是这样很容易被检测到)
如何定义劫持攻击成功呢?
- 劫持模型应实现良好的性能。
- 攻击的执行应该是隐蔽的。
为了满足这些要求, 提出两种劫持攻击模型, 变色龙攻击和 反向变色龙攻击。
变色龙攻击:
- 利用两种不同的损失来训练伪装者:视觉损失和语义损失, 分别在视觉上和语义上使 伪装者的 输出类似于 被劫持的样本。
- 在劫持任务和原始任务 的标签之间建立映射。
反向变色龙攻击:
- 当劫持 和 被劫持的 数据集相似时, 变色龙攻击的性能不行。
- 除了视觉损失和语义损失, 还额外增加了不利语义损失,显示的增加了约束,减轻劫持任务的训练。
数据集
MNIST, CIFAR-10, CelebA
贡献
-
我们提出了针对机器学习模型的第一种模型劫持攻击。
-
我们提出了一种伪装模型,该模型对劫持样本进行伪装,用于隐蔽模型劫持攻击。
-
我们提出的两种模型劫持攻击,即变色龙攻击和反向变色龙攻击,在不同的设置下实现了强大的性能。
三、前置内容
机器学习分类设置
- 机器学习分类器 用于将 数据样本分类/标签,对于输入样本x,该分类器(模型)M预测了一组概率向量Y。|Y|表示该组中唯一标签的数量。
- Y中的每个yi表示:M将样本x分配给标签li的置信度
- 模型的输出:只考虑最终的预先指定标签,即具有最大概率的标签,M (x) = argmax` iY
- 为了训练模型M,需要定义一个损失函数,并利用优化器最小化训练集D上的经验损失。
数据中毒攻击
- 敌方首先创建一个恶意数据集Dm(将一组样本标错)
- 将恶意数据集插入到良性数据集D中,来创建中毒数据集Dp(Dp = Dm||D)
- 中毒数据集Dp用来训练上述模型M
问题陈述
- 我们将与目标模型的原始任务相关的数据集称为原始数据集,而与劫持任务相关的数据集作为劫持数据集。
- 当敌方可以利用模型执行自己的劫持任务(hijacking task)时,认为该模型已经被劫持了。
四、几种模型攻击方式
普通攻击管道
- 敌方首先创建劫持数据集, 然后, 对于劫持数据集种的每个标签, 定义一个映射, 将其与原始数据集的标签相关联。
- 接下来,对手用劫持数据集毒害目标模型的训练数据集,并等待目标模型被训练,即被劫持。一旦模型被劫持,为了发起攻击,对手创建一个劫持样本并查询被劫持的模型。最后,对手将预测输出映射(使用攻击初始化时执行的相同映射的逆映射)回劫持任务的相应标签。
- 为了躲避检测,用于毒害目标模型的样本在视觉上与原始数据集中的 样本相似。(伪装其, 编码器-解码器的模型) 将劫持数据集种的样本转换为与原始数据集中的视觉相似,同时保持每个样本的原始语义。 伪装后的劫持数据集成为 伪装数据集(camouflaged dataset)
劫持成功的四个要求
要求1.被劫持模型在其原始任务上应具有与目标模型类似或更好的性能。
要求2.劫持数据集应伪装为被劫持者数据集,以使攻击更加隐蔽。
要求3.被劫持模型应根据劫持任务正确分类伪装样本。
要求4.为了进一步提高模型劫持攻击的隐蔽性,被劫持模型应随机对劫持数据集中的任何非伪装样本进行分类,即显著低于伪装样本的性能
模型劫持vs后门vs数据中毒
后门攻击:
- 敌手试图通过 操纵 目标模型的 训练 来危害模型的效用。
- 敌手可以将触发器链接到特定的模型输出。例如,当触发器被插入任何输入时,目标模型会预测一个被对手预定义的标签。
构建
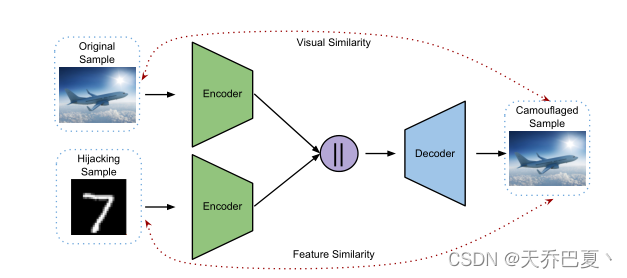
伪装器: 将劫持数据集 D h D_h Dh伪装成 被劫持数据集 D 0 D_0 D0, 由两个encoders和一个decoder组成。
A E C ( x o , x h ) = E − 1 ( E o ( x o ) ∣ ∣ E h ( x h ) ) = x c AE_C (x_o,x_h) = E^{−1}(E_o(x_o)||E_h(x_h)) = x_c AEC(xo,xh)=E−1(Eo(xo)∣∣Eh(xh))=xc
E 0 E_0 E0 是第一个编码器, 它将被劫持数据集中的样本 x 0 x_0 x0作为它的输入。
E h E_h Eh 是第一个编码器, 它将劫持数据集中的样本 x h x_h xh作为它的输入。
将两个编码器的输出连接起来, 创建decoder的输入, E − 1 E^{-1} E−1, 解码器生成伪装样本 x c x_c xc,该样本具有 x o x_o xo的视觉外观,具有 x h x_h xh的特征/语义
x 0 x_0 x0代表从原始数据集中来的样本, x h x_h xh代表从劫持数据集中来的样本。
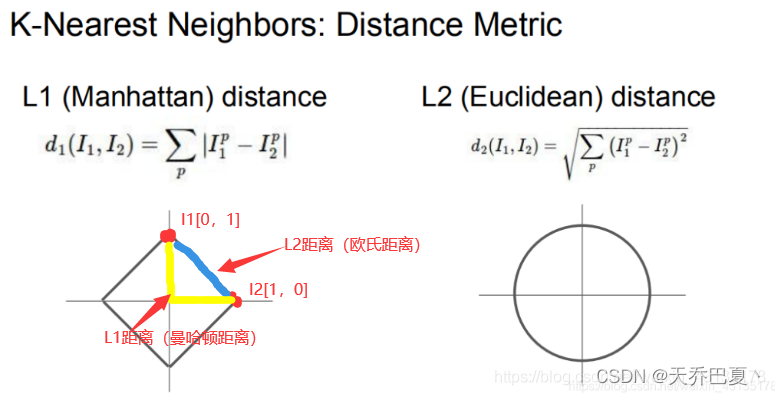
视觉损失:视觉损失计算伪装器输出和被劫持者样本之间的L1距离: ϕ v l = m i n ∣ ∣ x c − x o ∣ ∣ ϕ_{vl} = min||x_c − x_o|| ϕvl=min∣∣xc−xo∣∣
语义损失:由于语义丢失是在特征层而不是视觉层上进行的,因此我们首先需要一个特征提取器F,它提取给定样本的特征。我们使用MobileNetV2第二层到最后一层的输出。 ϕ s l = m i n ∣ ∣ F ( x c ) − F ( x h ) ∣ ∣ , ϕ_{sl} = min||F (x_c) −F (x_h)||, ϕsl=min∣∣F(xc)−F(xh)∣∣,
反向语义损失:这种损失最大化了被劫持者特征和使用L1距离的伪装样本之间的差异。 ϕ a s l = m a x ∣ ∣ F ( x c ) − F ( x o ) ∣ ∣ ϕ_{asl} = max||F (x_c) −F (x_o)|| ϕasl=max∣∣F(xc)−F(xo)∣∣
我们使用预处理的MobileNetV2作为我们的特征提取器。
变色龙攻击
变色龙攻击可分为三个阶段,即准备阶段、伪装阶段和执行阶段。
准备阶段
- 首先,敌手用被劫持数据集伪装劫持数据集。
- 接着,敌手创建原始数据集标签和劫持数据集中的标签的映射。(非语义的方式,即无论每个标签代表什么,我们都将原始数据集的第i个标签分配给劫持数据集的第i标签。)
- 最后,敌手选择其特征提取器F,用于计算训练伪装器所需样本的特征。
伪装阶段
- 对手首先将来自被劫持者数据集的样本与劫持数据集中的样本随机配对。(由于两个数据集可以具有不同的大小,因此两个数据集映射的关系为多对多的映射关系)
- 在样本映射之后,将每对样本(劫持者样本 和 被劫持者样本) 提供给伪装器。
- 使用如下损失函数: L C h a m ( x c , x o , x h ) = m i n ( ∣ ∣ x c − x o ∣ ∣ + ∣ ∣ F ( x c ) − F ( x h ) ∣ ∣ ) L_{Cham}(x_c,x_o,x_h) = min ( ||x_c −x_o||+||F (x_c)−F (x_h)|| ) LCham(xc,xo,xh)=min(∣∣xc−xo∣∣+∣∣F(xc)−F(xh)∣∣), 使用伪装器的输出和输入样本来更新伪装器。
执行阶段
下图展现了伪装训练后变色龙攻击的概况:
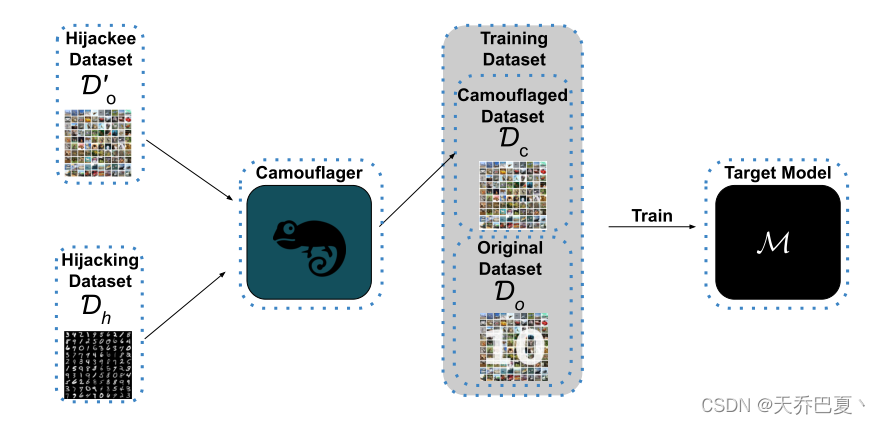
首先,敌方将被劫持者数据集 D o ′ D'_o Do′中的样本映射到劫持数据集 D h D_h Dh中的样本,并通过查询经过训练的伪装者camouflager来创建伪装数据集 D c D_c Dc。接下来,他们使用伪装数据集毒害目标模型Target Model的训练,以劫持它。
我们将使用中毒数据集训练后的目标模型称为劫持模型。
反向变色龙攻击
当劫持和被劫持数据集显著不同时,变色龙攻击具有良好的性能。然而,当两个数据集都很复杂且没有显著差异时,性能开始下降。因此,我们提出了更高级的攻击,即反向变色龙攻击。
反向变色龙攻击试图明确地将伪装器输出的特征与被劫持者数据集隔开。为了实现这一点,除了视觉和语义损失之外,我们还使用了不利的语义损失。
L C h a m A d v ( x c , x o , x h ) = m i n ( ∣ ∣ x c − x o ∣ ∣ + ∣ ∣ F ( x c ) − F ( x h ) ∣ ∣ − ∣ ∣ F ( x c ) − F ( x o ) ∣ ∣ ) L_{ChamAdv}(x_c,x_o,x_h) = min ( ||x_c −x_o||+||F (x_c)−F (x_h)|| - ||F(x_c) - F(x_o)|| ) LChamAdv(xc,xo,xh)=min(∣∣xc−xo∣∣+∣∣F(xc)−F(xh)∣∣−∣∣F(xc)−F(xo)∣∣)
五、评估
数据集介绍
- MNIST:一个灰度级手写数字分类数据集。
- CIFAR-10:是一个10类彩色数据集。
- CelebA:是一个拥有超过200000张彩色图像的人脸属性数据集。
模型构建

conv2d(k,f)是具有大小为k和f滤波器的核的二维卷积层
最后,我们使用Adam优化器来训练伪装器。
两个评估指标
- 效用:在干净(clean)的测试数据集上比较了劫持模型(hijacked model)和干净模型(clean model)的准确性。
- 攻击成功率:攻击成功率衡量劫持数据集上的模型劫持攻击性能。(Attack Success Rate, ASR)
变色龙攻击实验数据
我们使用MNIST作为我们的劫持数据集,CIFAR-10和CelebA作为这次攻击的原始数据集
性能评估
clean :首先,我们只使用原始数据集训练一个干净模型(clean),以计算和比较变色龙劫持模型的效用。
Naive:其次,我们执行原始模型劫持攻击(naive),对手劫持目标模型,而不首先伪装劫持数据集。值得注意的是,这种Naive攻击是攻击成功率性能的上界,因为劫持样本是按原样使用的,没有任何修改以降低其隐蔽性,这是我们高级模型劫持攻击的目标。
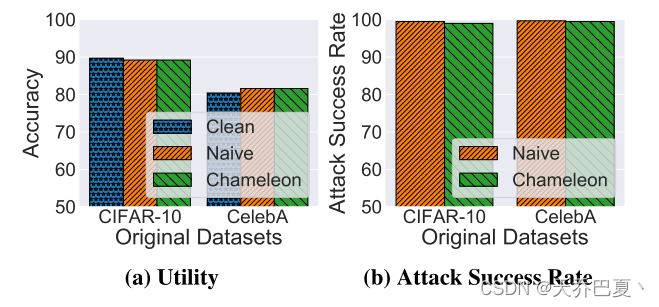
- 准确率:我们的变色龙攻击在原始测试数据集上实现了89.2%的准确率,这与朴素攻击完全相同,仅比CIFAR-10数据集的干净模型低0.5%。对于CelebA数据集,我们的变色龙和天真劫持模型实现了81.6%的准确率,比干净模型高1.2%。
- 攻击成功率。由于这里的劫持任务是MNIST,攻击成功率衡量劫持-MNIST-测试数据集的准确性。如图3b所示,我们的变色龙攻击实现了与天真劫持模型几乎相同的性能。当原始任务为CIFAR-10分类时,变色龙劫持模型实现了99%的攻击成功率,仅比天真劫持模型的攻击成功度低0.5%。对于CelebA分类模型,我们的攻击实现了99.5%的攻击成功率,仅比朴素模型低0.2%
一般来说,使用变色龙攻击的劫持模型可以实现几乎完美的攻击成功率(要求3),而实用性的下降可以忽略不计(要求1),这表明当原始数据集和劫持数据集显著不同时,这种攻击的有效性(如后文图6所示)。
隐匿性评估
- 首先,我们测量劫持和原始数据集之间的欧几里得距离,以及伪装和原始数据集的距离。为了测量欧几里得距离,我们随机抽取1000个伪装、原始和劫持样本。(距离越小表示攻击越隐蔽)
- 其次,我们使用 t-distributed stochastic neighbor em-bedding (t-SNE)将劫持、原始和伪装数据集的100个样本减少到二维。
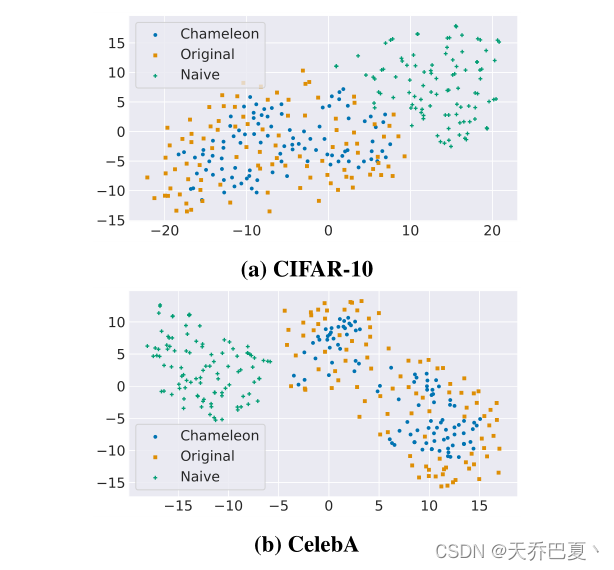
a和b中显示了CIFAR-10和CelebA劫持模型的t-SNE缩减样本。伪装(变色龙)样本更接近原始(原始)样本,并隐藏在原始样本中,与劫持(天真)样本不同。变色龙攻击在隐蔽性方面明显优于naive模型劫持攻击

最后,我们将随机抽样的伪装样本与来自原始数据集和劫持数据集的样本一起可视化,如图5所示。事实上,我们的伪装样本看起来像添加了一些人工制品的原始样本。
反向变色龙攻击
性能评估
当使用CIFAR-10作为原始数据集和CelebA作为劫持数据集执行变色龙攻击时,它只实现了65.7%的攻击成功率,比原始攻击低14.3%。可能的原因:
- 之前MNIST作为劫持数据集,celeb相对来说有更加复杂的性质。
- CelebA和CIFAR-10数据集彼此更接近。
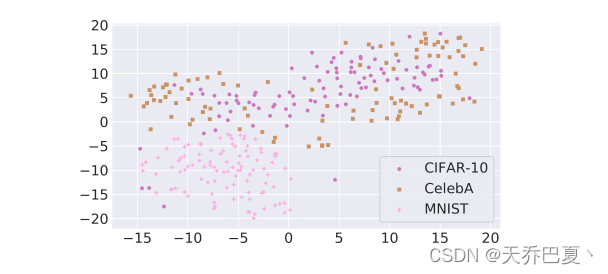
因此,当将CelebA或CIFAR-10数据集视为劫持数据集时,我们执行反向变色龙攻击。
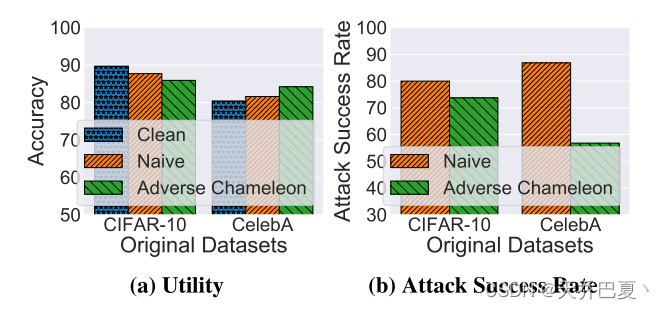
如图所示,当使用Adverse Chameleon攻击伪装CelebA数据集并劫持CIFAR-10分类模型时,该实用程序仅略微下降。更具体地说,当使用Naive和Adverse Chameleon攻击劫持模型时,被劫持模型在CIFAR-10测试数据集上的准确率分别达到87.7%和85.9%。这一准确率仅为2%,比干净的CIFAR-10分类模型低3.8%。
对于相反的情况,即劫持数据集是CIFAR-10,原始数据集是CelebA,我们的反向变色龙攻击达到84.2%的准确率,分别比Naive攻击和clean模型高2.6%和3.8%。我们认为,性能的提高是由于我们的攻击的正规化效应。
如图7a和图7b所示,我们的不利变色龙攻击同时满足我们的性能相关要求,即要求1和要求3。
隐匿性评估
使用欧几里德距离和t-SNE可视化和比较不利变色龙的隐身性(要求2)。
首先,我们比较欧氏距离。使用我们的反向变色龙攻击劫持带有CelebA分类-劫持-任务的CIFAR-10分类模型,导致0.52欧氏距离。这比Naive攻击的欧氏距离小2.5倍。
当使用CelebA分类任务作为原始任务,使用CIFAR-10分类作为劫持任务时,我们的反向变色龙实现了0.77欧式距离,这比使用Naive攻击的变色龙低1.6倍。
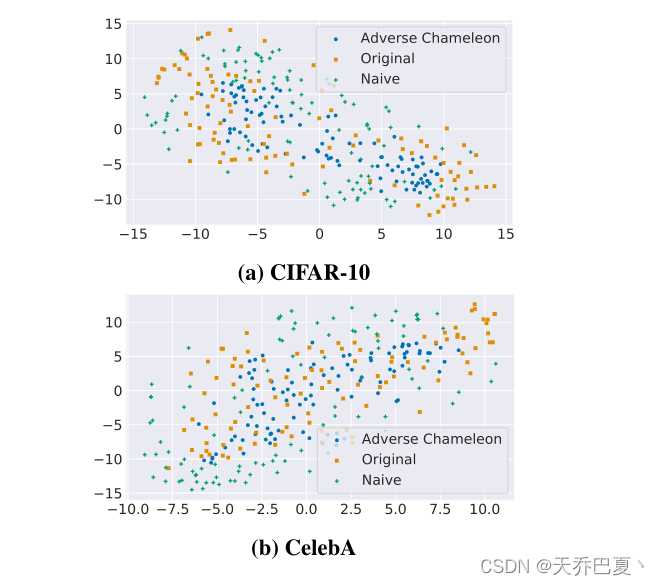
我们在图8b中显示了使用CelebA作为劫持数据集和使用CIFAR-10作为原始数据集的结果,在图8a中显示了相反的结果。如两个图所示,被劫持的样本(不利变色龙)与原始样本(原始)比非伪装劫持样本(天真)更为聚类。
比较变色龙攻击和不利变色龙攻击的t-SNE结果,可以进一步确认使用CelebA或CIFAR-10分类任务作为劫持任务确实比使用MNIST更难;

总结
两种攻击的讨论:如本节和上一节(第4.3节)所示,我们的两种模型劫持攻击,即变色龙攻击和反向变色龙攻击,都实现了强大的性能,即,与天真攻击相比,它们实现了可比的攻击成功率,与干净模型相比具有类似的效用。此外,当劫持和原始数据集不同时,使用变色龙攻击就足够了。然而,当两个数据集更加复杂和相似时,则需要反向变色龙攻击来提高模型劫持攻击的性能。
六、考虑不同参数对实验的影响
不同的目标模型
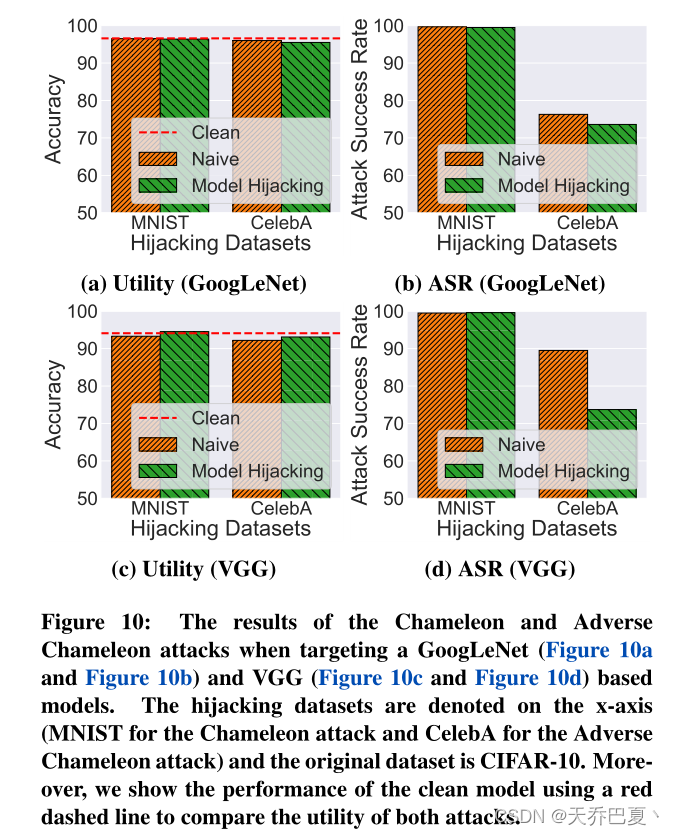
不同的特征提取器
不同的损失函数
伪装器的可转移性
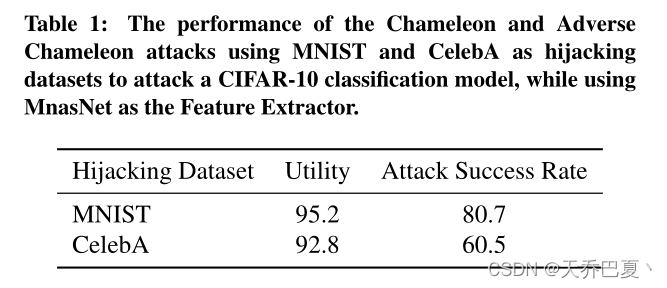
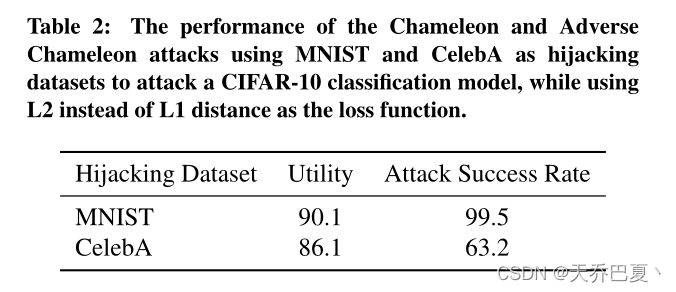
我们现在评估伪装者的可转让性。为此,我们使用第4.3节和第4.4节中使用的先前经过培训的伪装者劫持CIFAR-100分类模型,其中MNIST和CelebA分别作为劫持数据集。我们使用经过预处理的伪装者来实施变色龙攻击和反向变色龙攻击,这两种攻击分别在第3.4节和第3.5节中介绍。
我们的实验表明,对于MNIST劫持数据集,变色龙攻击实现了81.8%的准确率和99.5%的ASR。类似地,对于CelebA劫持数据集,反向变色龙攻击实现了78.6%的准确率和76.3%的ASR。
这些结果进一步证明了伪装器在训练后的可转移性。换言之,对手可以训练伪装者,并利用它劫持具有不同分类任务的不同模型。
被劫持数据集的大小
我们现在评估被劫持者数据集大小的影响。
在这里,我们使用我们的不利变色龙攻击劫持具有CelebA数据集的CIFAR-10分类模型。
我们为劫持者数据集评估了一系列不同的大小,即我们将大小设置为10100、1000和10000个样本。对于每个设置,我们劫持CIFAR-10模型并计算两个指标,即效用和攻击成功率。
使用大小为10、100、1000和10000的劫持者数据集执行不利变色龙攻击,攻击成功率分别为44.7%、60.5%、73.7%和65.8%,准确率分别为82.4%、87.4%、85.9%和87.4%。
结果表明,使用10个样本的劫持者数据集对于执行模型劫持攻击来说太小了。然而,将样本大小设置为100个或更多已经足以应对不利的变色龙劫持攻击。我们选择尺寸为1000的劫机者,因为与其他两个相比,它实现了最佳的整体性能
中毒速率
我们评估了变色龙和有害变色龙攻击,同时将劫持数据集(中毒数据)的大小设置为10000到40000,步长为10000。对于这两种攻击,我们将原始任务设置为CIFAR-10分类。对于劫持任务,我们使用MNIST分类进行变色龙攻击,使用CelebA分类进行不利变色龙攻击。
我们的结果表明,对于使用MNIST作为劫持数据集的简单情况,10000,即17%的中毒率,劫持样本足以让我们的变色龙攻击劫持CIFAR-10分类模型。更具体地说,使用10000个劫持样本劫持模型的攻击成功率(99%)与使用40000个样本劫持模型相同,类似地,两个模型的效用之间的差异可以忽略不计。
然而,对于使用CelebA作为劫持数据集执行不利变色龙攻击和劫持CIFAR-10分类模型的更复杂任务;劫持数据集的大小具有显著影响。例如,当使用20000个样本时,攻击成功率从73.7%降至63.2%,即中毒率为28%,而不是40000。然而,由于劫持样本较少,被劫持模型的实用性从85.9%增加到86.7%。
七、相关工作
八、三个限制
- 我们的模型劫持攻击的第一个限制是劫持数据集的类数不能超过原始数据集。为了解决这一限制,我们建议使用更复杂的分层模型劫持攻击,并具有多个分类任务的虚拟层。
- 我们攻击的第二个限制是伪装图像上的视觉-非自然-伪影。为了解决这一限制,我们提出了不同的方法
- 第一种方法是使用具有更多层的更强大的最先进的自动编码器。
- 此外,我们建议使用加权参数对视觉损失给予更多权重,从而使输出图像更自然。
- 第三种方法是添加一个判别模型,该模型对图像的不自然外观进行惩罚。
- 最后,我们攻击的第三个限制是训练伪装者的成本。我们建议使用预训练的自动编码器并对其进行微调,这可以减少训练时间。此外,我们计划在未来的工作中探索采用少量的射击学习技术,以进一步降低伪装机的训练成本。
九、可能的抵御方法
- 一种幼稚的防御方法是在将图像输入模型之前向图像添加噪声。这种防御会降低攻击性能,但也会降低原始任务的性能。
- 更复杂的防御是对训练和测试图像使用自动编码器或不同的去噪技术。
- 另一种可能的防御方法是根据目标模型的熵过滤其输出。换句话说,模型所有者首先确定一个阈值,然后计算每个查询样本的熵。如果这个样本的熵高于/低于阈值,那么模型所有者可以接受/拒绝它。