这节课主要讲
随机梯度下降,分类
1. 批量梯度下降(Batch Gradient Descent,BGD)
使用整个训练集的优化算法被称为批量(batch)或确定性(deterministic)梯度算法,因为它们会在一个大批量中同时处理所有样本。
批量梯度下降法是最原始的形式,它是指在每一次迭代时使用所有样本来进行梯度的更新。
优点:
(1)在训练过程中,使用固定的学习率。
(2)由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。
(3)它对梯度的估计是无偏的。样例越多,标准差越低。
(4)一次迭代是对所有样本进行计算,此时利用向量化进行操作,实现了并行。
缺点:
(1)尽管在计算过程中,使用了向量化计算,但是遍历全部样本仍需要大量时间,尤其是当数据集很大时(几百万甚至上亿),就有点力不从心了。
(2)每次的更新都是在遍历全部样例之后发生的,这时才会发现一些例子可能是多余的且对参数更新没有太大的作用。

这个例子就是一个批量梯度下降,需要把所有的数据都训练一遍,求出所有数据的平均损失函数E,然后根据这个平均损失函数来更新梯度。
从迭代的次数上来看,BGD迭代的次数相对较少。其迭代的收敛曲线示意图可以表示如下:
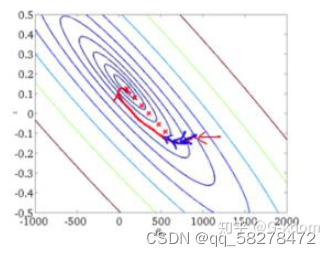
2. 随机梯度下降(Stochastic Gradient Descent,SGD)
随机梯度下降法不同于批量梯度下降,随机梯度下降是在每次迭代时使用一个样本来对参数进行更新。
这里不需要把所有的数据都训练一遍,求出一条数据的损失函数E,然后根据这一条数据的损失函数来更新梯度。
优点:
(1)在学习过程中加入了噪声,提高了泛化误差。
(2)由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据上的损失函数,这样每一轮参数的更新速度大大加快。
缺点:
(1)不收敛,在最小值附近波动。
(2)不能在一个样本中使用向量化计算,学习过程变得很慢。
(3)单个样本并不能代表全体样本的趋势。
从迭代的次数上来看,SGD迭代的次数较多,在解空间的搜索过程看起来很盲目。其迭代的收敛曲线示意图可以表示如下:
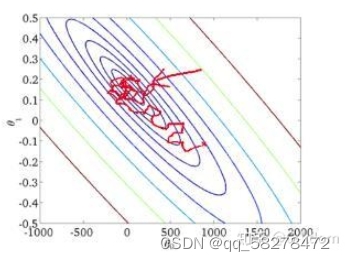
随机梯度下降法数据可以随机的 打乱训练集顺序。
3. 小批量梯度下降(Mini-batch Gradient Descent,MBGD)
大多数用于深度学习的梯度下降算法介于以上两者之间,使用一个以上而又不是全部的训练样本。传统上,这些会被称为小批量(mini-batch)或小批量随机(mini-batch stochastic)方法,现在通常将它们简单地成为随机(stochastic)方法。对于深度学习模型而言,人们所说的“随机梯度下降, SGD”,其实就是基于小批量(mini-batch)的随机梯度下降。


优点:
(1)计算速度比Batch Gradient Descent快,因为只遍历部分样例就可执行更新。
(2)随机选择样例有利于避免重复多余的样例和对参数更新较少贡献的样例。
(3)每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。
缺点:
(1)在迭代的过程中,因为噪音的存在,学习过程会出现波动。因此,它在最小值的区域徘徊,不会收敛。
(2)学习过程会有更多的振荡,为更接近最小值,需要增加学习率衰减项,以降低学习率,避免过度振荡。
(3)batch_size的不当选择可能会带来一些问题。
下图显示了以上三种梯度下降算法的收敛过程:

不管是随机梯度还是批量梯度,它们的区别在于每次迭代计算应用的数据多少;随机一条优点是计算快,但是容易造成抖动,且有很大的随机性【管中窥豹,可见一斑】;批量全部优点是计算准确,可以稳步下降,但每次迭代计算时间长,资源消耗大;中庸之道在算法领域也是一个很重要的思想,Mini-batch就是其中的产物,每次计算取一小批数据进行迭代计算,即减低了异常数据带来的抖动,也降低了每次迭代计算的数据计算量;对于一般的应用场景,Mini-batch会是一个比较好的选择!
分类和回归 Classification and Regression
其实分类和回归的本质是一样的,都是对输入做出预测,其区别在于输出的类型。
分类问题:分类问题的输出是离散型变量(如: +1、-1),是一种定性输出。(预测明天天气是阴、晴还是雨) 回归问题:回归问题的输出是连续型变量,是一种定量输出。(预测明天的温度是多少度)。
分类问题最后是给出每一个类别的概率是多少,然后把概率最大的那一个视为结果。
激活函数
激活函数的目的是为神经元添加非线形的输入。一个没有激活函数的神经网络就只是一个线性回归模型,非线形的激活函数能够增加非线性的变换到输入中,使得它能够学习和表现更复杂的任务。
首先摆结论,因为线性模型的表达能力不够,引入激活函数是为了添加非线性因素。 接下来展开来说。
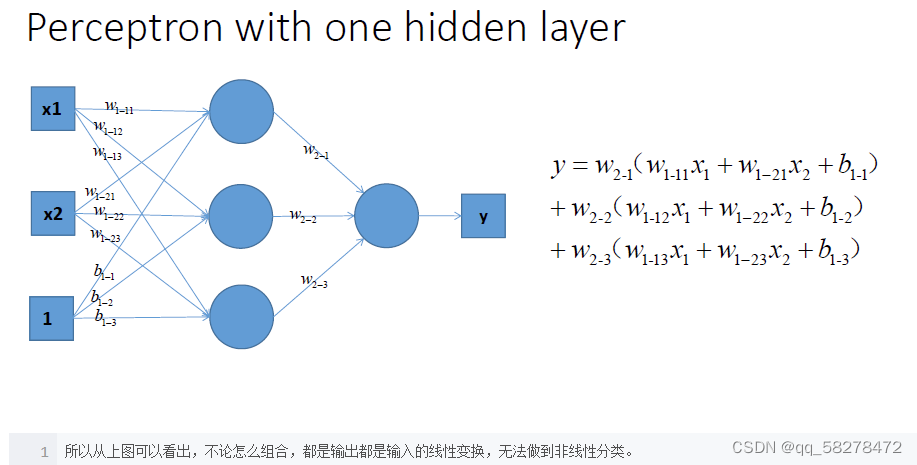
激活函数的作用?
引入非线性因素。
在我们面对线性可分的数据集的时候,简单的用线性分类器即可解决分类问题。但是现实生活中的数据往往不是线性可分的,面对这样的数据,一般有两个方法:引入非线性函数、线性变换。
线性变换
就是把当前特征空间通过一定的线性映射转换到另一个空间,让数据能够更好的被分类。
激活函数
激活函数是如何引入非线性因素的呢?在神经网络中,为了避免单纯的线性组合,我们在每一层的输出后面都添加一个激活函数(sigmoid、tanh、ReLu等等),这样的函数长这样:
Sigmoid & Tanh
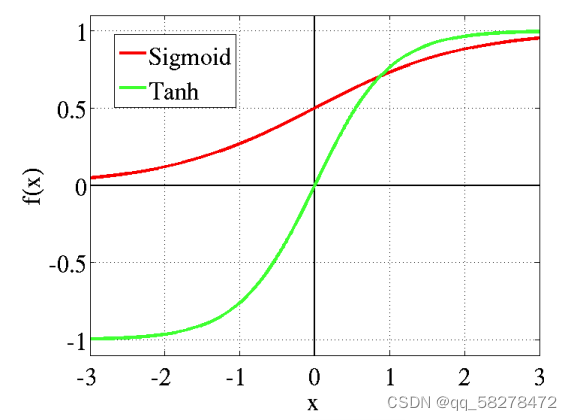
每一层的输出通过这些激活函数之后,就变得比以前复杂很多,从而提升了神经网络模型的表达能力。当然怎么选择这个激活函数,还是很需要一些trick的。现在很多都用tanh或者relu。
下面视频看为什么使用激活函数,以及各个激活函数的求导过程
[5分钟深度学习] #03 激活函数哔哩哔哩bilibili
【数之道 06】神经网络模型中激活函数的选择_哔哩哔哩_bilibili
主要看三种激活函数的介绍
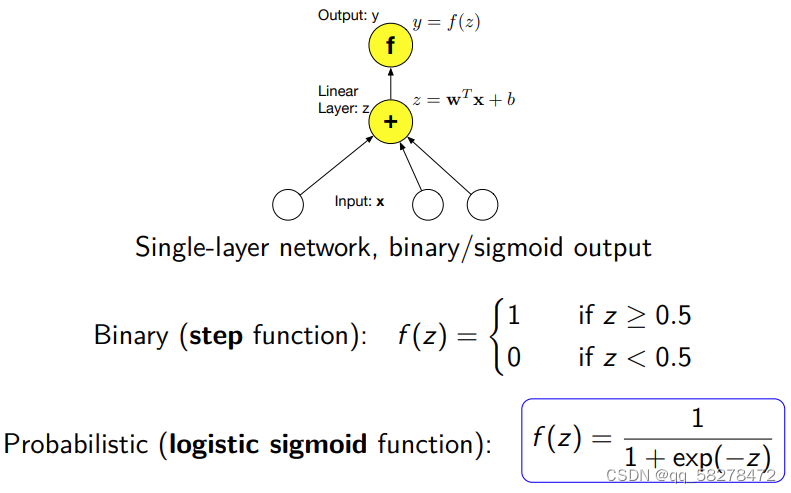
以单层神经网络为例,sigmoid函数可以作为二分类逻辑回归模型的预测表达式,因为他可以把表达式映射到[0,1]. 之前的方法看z的输出值大于0.5判定为第一类,小于则是第二类,有了sigmoid就可以直接映射到[0,1],知道是哪一类。sigmoid函数又称 Logistic函数,用于隐层神经元输出,取值范围为(0,1),可以用来做二分类。sigmoid可以用来二分类,也可以用作是激活函数.
如果使用线性激活函数,那么输入跟输出之间的关系为线性的,无论神经网络有多少层都是线性组合。
使用非线性激活函数是为了增加神经网络模型的非线性因素,以便使网络更加强大,增加它的能力,使它可以学习复杂的事物,复杂的表单数据,以及表示输入输出之间非线性的复杂的任意函数映射。其求导过程视频里面介绍了就不赘述了。
第一种使用分段函数有个问题,就是其表达式不可微(differentiable),可微是指那些在定义域中所有点都存在导数的函数,在Z等于0.5的时候就没有导数。因此不可微,但是sigmoid函数就是可微的,导数是σ′(x)=σ(x)[1−σ(x)],其中σ(x)就是sigmoid的表达式。
第二个问题,就是使用分段函数z有微小的变化,就会引起结果有很大的偏差,老师举例0.5和0.49可能差别不大,但是用分段函数就会分到两个类别去。但是用sigmoid就不会,它比较平滑。
逻辑回归LR使得最终结果有了概率解释的能力(将结果限制在0-1之间),sigmoid为平滑函数(连续可导),能够得到更好的分类结果,而step function为分段函数,对于分类的结果处理比较粗糙,非0即1,而不是返回一个分类的概率。sigmoid使用概率作为输出结果使得样本在距离很小的差别下不再强制地输出+1和-1这两种天壤之别的结果,而是通过概率的方式告诉你结果可能是多少,同时也告诉你预测的不确信程度。这样子看起来让人比较安心一点不是吗?
第一种方法分类用的是分段函数叫感知机,第二种方法用线性回归+sigmoid叫逻辑回归。
下面是逻辑回归的一个视频,可以看看
【机器学习】逻辑回归十分钟学会,通俗易懂(内含spark求解过程)哔哩哔哩bilibili

这里还是链式求导E和Y都如下,大家可以动手算一下,算不出来我手把手辅导。

交叉熵损失函数
交叉熵函数为在处理分类问题中常用的一种损失函数、
1.交叉熵损失函数由来 交叉熵是信息论中的一个重要概念,主要用于度量两个概率分布间的差异性。首先我们来了解几个概念。
1.1信息量 信息论奠基人香农(Shannon)认为“信息是用来消除随机不确定性的东西”。也就是说衡量信息量大小就看这个信息消除不确定性的程度。
“太阳从东方升起了”这条信息没有减少不确定性。因为太阳肯定从东面升起。这是句废话,信息量为0。
“六月份下雪了”,这条信息就比较有价值,根据历史统计信息来看,六月份鲜有下雪记录,可知该语句信息量较大。
从上面两个例子可以看出:信息量的大小和事件发生的概率成反比。
由此引出信息量的表示:
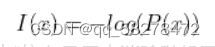
其中P(x)表示为, 时间x的发生概率,这里可能会有质疑,我们知道信息量的大小和事件发生的概率成反比,函数形式为减函数,为什么要表现为对数形式呢?
1.事件发生的概率越低,信息量越大;
2.事件发生的概率越高,信息量越低;
3.多个事件同时发生的概率是多个事件概率相乘,总信息量是多个事件信息量相加。
根据性质3,可以知道使用对数形式可以满足性质需求,因此为表现该形式。
下面老师主要讲解了推导过程,尽量理,不理解也没事都这么用的,但求偏导得会。

有了质量函数我们要求一个log 至于为什么 上边有写

有了交叉熵损失函数之后我们就可以和之间一样,进行链式求导了,唯一得不同点就是,损失函数变了

为什么第一个用得均方损失函数,现在又要用交叉熵损失函数呢?我们来看一下损失函数
损失函数
1. 为什么要设定损失函数
在神经网络的学习中,寻找最优参数(权重和偏置)时,要寻找使损失函数的值尽可能小的参数。为了找到使损失函数的值尽可能小的地方,需要计算参数的导数(确切地讲是梯度),然后以这个导数为指引,逐步更新参数的值。

两种损失函数得用途不同,也各自有优点。
如果我们有K个类使用“one-hot”(“one-from-N”)输出编码——正确类的目标为1,其他所有目标为0 例如

预测结果可能为【0.8,0.5,0.6】,对多个类使用多个sigmoid意味着网络的输出不被限制为和为1。因此我们要学习softmax,softmax可以将不同种类得到得概率之和为1.
-
在softmax中,我们计算得到的各类别概率之和为1 ,也就是说我们加大某一类别的概率必然导致其他类别减小——各类别之间相互关联,是互斥的。
-
在sigmoid中,我们计算的各类别概率之和则不一定为1 ,各个输出值依次独立的经过激活函数的映射,某一个类别概率增大可能也伴随另一个类别概率增大——各类别之间相互独立,不互斥。
说白了softmax能做到归一化,让所有结果和为1 softmax多用于多分类,在sigmoid基础上改进得到,sigmoid多用于二分类。具体看下面视频。
之后就是把交叉熵函数从二分类拓展到多分类,然后又计算了偏导。
week2就写到这里了,有些内容需要我细说。