版权声明:转载请注明出处 https://blog.csdn.net/zhouchen1998/article/details/89043356
一元回归分析和多元线性回归
- 前言
- 在统计学中,回归分析(Regression Analysis)指的是确定两种或两种以上变量间的相互依赖的定量关系的一种分析方法。该方法常使用数据统计的基本原理,对大量统计数据进行数学处理,并确定因变量与某些自变量的相关关系,建立一个相关性较好的回归方程(函数表达式),并加以外推,用于预测以后的因变量的变化的分析方法。
- 回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。实际上预测分析是回归分析的一种。
- 之前有说过分类问题,模式分类是通过构造一个分类函数或者分类模型将数据集映射到一个个给定的类别中(这些类别是离散的),它是模式识别的核心研究内容,关系到其识别的整体效率,广泛应用于各个研究领域。而回归问题则是确定两种或者两种以上变量间相互依赖的定量关系的一种统计方法。(这些结果是连续的)。
- 就结果形式上来看,分类试图得到一个向离散集合的映射,回归试图得到一个向连续集合的映射。
- 一个简单的回归方程:
- 用户满意度= 0.008*形象 + 0.645*质量 + 0.221*价格
- 这个方程说明质量对用户满意度贡献比最大,质量提高1分,满意度提升0.645分,以此类推,形象贡献最小。
- 使用回归分析得到这个式子,在今后产品上市前,可以根据产品的质量、价格以及形象预测用户对即将上市产品满意度。(这三个特征任意可以计算一个确切的值,即映射到一个连续不断的空间。)
- 回归分析方法较多,常见如下。
- 按照涉及变量多少,分为一元回归分析和多元回归分析。
- 按照因变量的多少,分为简单回归分析和多重回归分析。
- 按照自变量和因变量之间的关系类型,分为线性回归分析和非线性回归分析。
- 简介
- 一元回归分析
- 对于一组自变量x和对应的一组因变量y的值,x和y呈线性相关关系,现在需要求出满足这个线性关系的直线方程。在数学上一般使用最小二乘法,其主要思想就是找到这样一条直线,使所有已知点到这条直线的距离的和最短,那么理论上这条直线就应该和实际数据拟合度最高。
- 多元线性回归
- 上面的一元回归自变量只有一个,在回归分析中如果出现两个以上的自变量,称为多元回归。事实上,一种现象常常与多种因素关联,由多个自变量的最优组合共同来预测或估计因变量,比只用一个自变量进行预测或估计更有效,更符合实际。因此,多元线性回归意义大于一元回归。例如,一个消费水平的关系式中,工资水平、受教育水平、职业、地区、家庭负担等因素都会影响消费水平。
- 一元回归分析
- 原理
- 一元回归分析
- 假设方程为 已知很多数据点(x,y),经过最小二乘法,计算出截距项a和斜率b。
- 回归的目的就是建立一个回归方程来预测目标值,回归的求解就是求这个回归方程的回归系数,如a和b。在回归系数计算出来之后,预测的方法就非常简单了,只需要把输入值代入回归方程即可得到预测值。
- 多元线性回归
- 若特征X不止一个,可以构造多元线性回归模型。 多元线性回归与一元线性回归类似,可以用最小二乘法估计模型参数,也需要对模型及模型参数进行统计检验,计算出a0,a1,a2等参数。这时就可以得到多元回归方程,此时,给出多个自变量,使用回归方程,就可以预测因变量。
- 回归计算法
- 步骤
- 通过对Loss函数求每个参数的偏导。
- 对所有偏导数,令其为0,解出参数值。
- 这种方法就是最小二乘法。
- 对于多元回归,可以使用矩阵进行相关推导,大致思想与一元回归类似,使用最小二乘法。
- 步骤
- 一元回归分析
- 实战
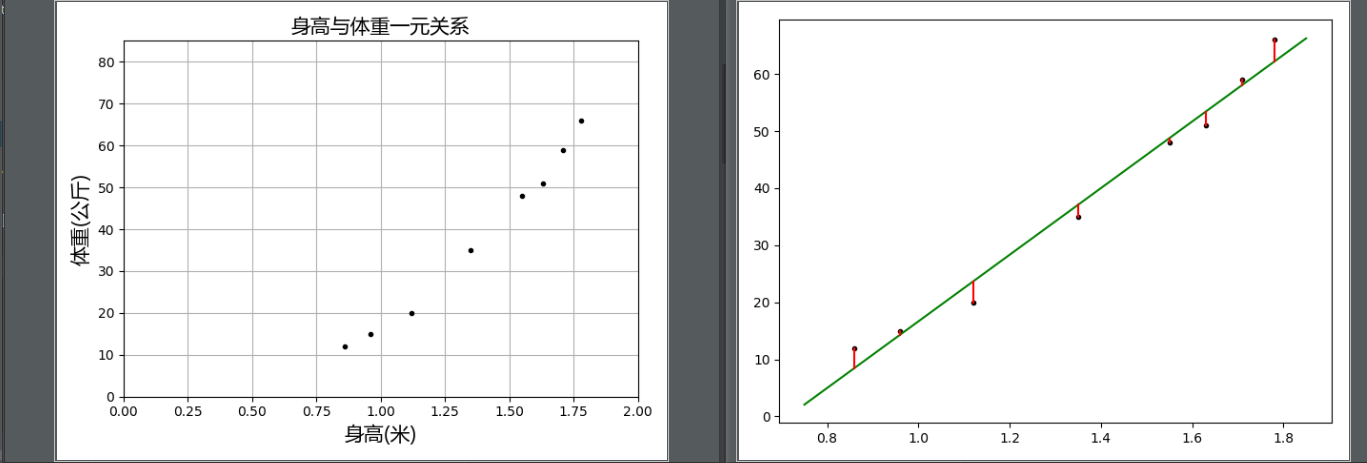
- 身高与体重的一元回归
- 运行结果
- 运行结果
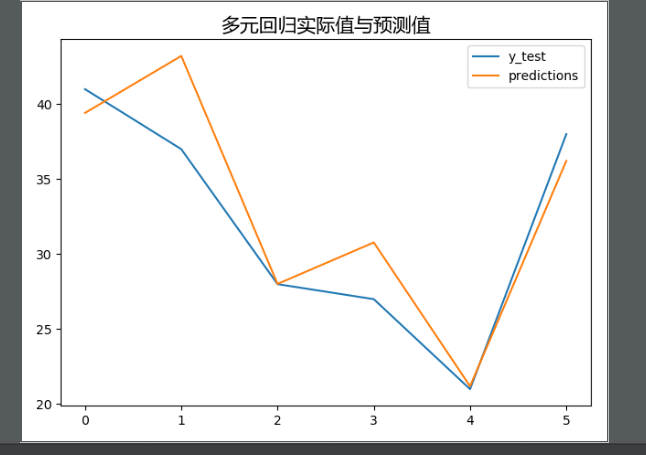
- 身高、年龄与体重的二元回归
- 运行结果
- 运行结果
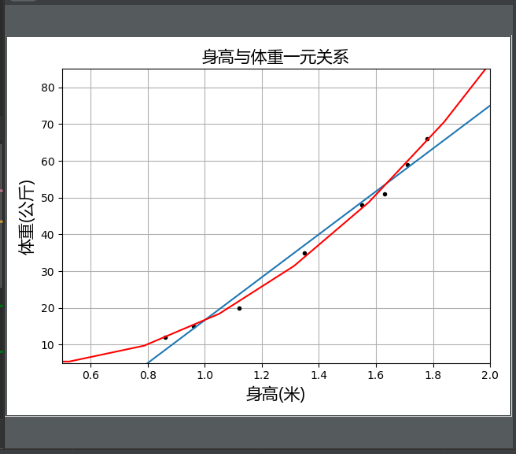
- 身高与体重高次回归
- 运行结果
- 运行结果
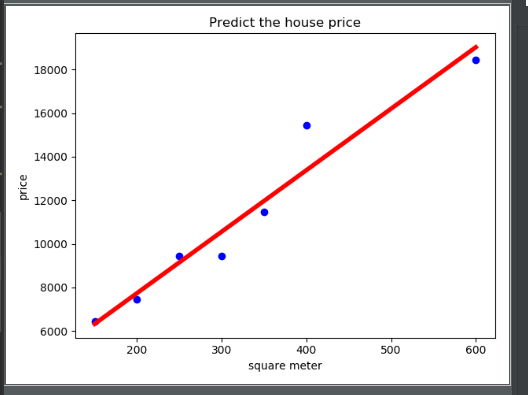
- 房价预测
- 代码
-
# -*-coding:utf-8-*- import matplotlib.pyplot as plt import pandas as pd from sklearn.linear_model import LinearRegression import numpy as np # 输入文件,将房间大小和价格的数据转成scikitlearn中LinearRegression模型识别的数据 def get_data(file_name): data = pd.read_csv(file_name) X_parameter = [] Y_parameter = [] for single_square_meter, single_price_value in zip(data['square_meter'], data['price']): X_parameter.append([float(single_square_meter)]) Y_parameter.append([float(single_price_value)]) return X_parameter, Y_parameter # 线性分析 def line_model_main(X_parameter, Y_parameter, predict_square_meter): # 模型对象 regr = LinearRegression() # 训练模型 regr.fit(X_parameter, Y_parameter) # 预测数据 predict_outcome = regr.predict(predict_square_meter) predictions = {} # 截距值 predictions['intercept'] = regr.intercept_ # 斜率值 predictions['coefficient'] = regr.coef_ # 预测值 predictions['predict_value'] = predict_outcome return predictions # 显示图像 def show_linear_line(X_parameter, Y_parameter): # 构造模型对象 regr = LinearRegression() # 训练模型 regr.fit(X_parameter, Y_parameter) # 绘制已知数据的散点图 plt.scatter(X_parameter, Y_parameter, color='blue') # 绘制预测直线 plt.plot(X_parameter, regr.predict(X_parameter), color='red', linewidth=4) plt.title('Predict the house price') plt.xlabel('square meter') plt.ylabel('price') plt.show() # 主函数 def main(): # 读取数据 X, Y = get_data('data/house_price.csv') # 获取预测值,这里我们预测700平英尺的房子的房价 predict_square_meter = np.array([300, 400]).reshape(-1, 1) result = line_model_main(X, Y, predict_square_meter) for key, value in result.items(): print('{0}:{1}'.format(key, value)) # 绘图 show_linear_line(X, Y) if __name__ == '__main__': main()
-
- 运行结果
- 代码
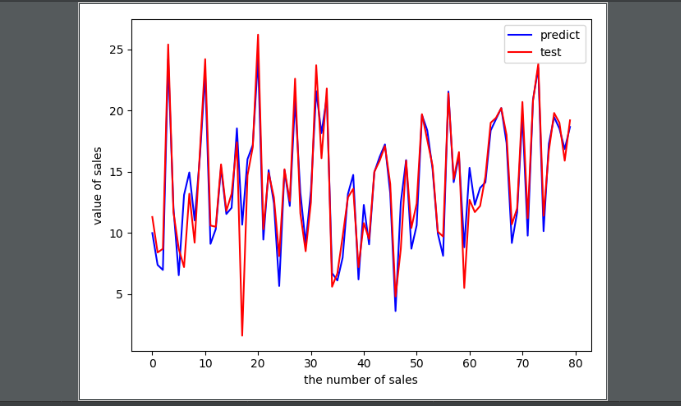
- 产品销量与广告多元回归
- 代码
-
# -*-coding:utf-8-*- # 导入模块 import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split # 使用pandas读入数据 data = pd.read_csv('data/Advertising.csv') # 转换数据 feature_cols = ['TV', 'radio', 'newspaper'] X = data[feature_cols] y = data['sales'] # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.4, random_state=0) # 循环多元回归模型 linreg = LinearRegression() model = linreg.fit(X_train, y_train) print(model) print(linreg.intercept_) print(linreg.coef_) # 预测 y_pred = linreg.predict(X_test) print(y_pred) # 使用图形来对比预测数据与实际数据之间的关系 plt.figure() plt.plot(range(len(y_pred)), y_pred, 'b', label='predict') plt.plot(range(len(y_pred)), y_test, 'r', label='test') plt.legend(loc='upper right') plt.xlabel('the number of sales') plt.ylabel('value of sales') plt.show() # 模型验证 sum_mean = 0 for i in range(len(y_pred)): sum_mean += (y_pred[i] - y_test.values[i]) ** 2 sum_erro = np.sqrt(sum_mean / 50) print('RMSE by hand:', sum_erro)
-
- 运行结果
- 代码
- 身高与体重的一元回归
- 补充说明
- 参考书为《Python3数据分析与机器学习实战》,对部分错误修改
- 具体数据集和代码见我的Github,欢迎Star或者Fork