目录
一、随记
毕业后学习R、Python,一直都是在用有道云笔记做记录,当时不求美观,只求实用,做了很多文档说明。如今开始学习机器学习,发现有道云笔记的记录方式已经不能满足需要。毕竟机器学习不是靠做个文档说明就可以解决问题的,既要有理论支撑,还要有软件实现。两者相互掺杂在一起,太过随意的记录会失去一些结构性内容,估计日后自己都不知道记的什么了。所以决定把机器学习的相关内容记录到CSDN上。虽然有很多内容是从其他地方“搬过来”的,但是自己动手操作一遍,理解了,就没有白复制粘贴。
几句鸡汤:得之太易,必不珍惜 好记性不如烂笔头 实践出真知
文中会使用不同来源的资料笔记,会尽可能标注,如未说明还望见谅。所有内容仅供学习使用,言归正传,下面开始正题。
二、理论
- 适用对象:
特征与目标类目间关系多、复杂,不易理解又有相似之处,即概念难定义,但你看到后就知道是什么。不适用于类与类间没有明确界限的实例。 - 优点:简单有效;对数据的分布没有要求;对异常值和噪声有较高容忍度;训练阶段很快。
缺点:不产生模型,不易解释特征间关系;分类阶段慢,需要大量内存进行计算。K为偶数时可能出现一半对一半的问题(用距离加权)。 - 思想:
对一条测试样本,计算与训练集中各样本的距离,并找到与其距离最近的k条记录,选择这k个记录中里出现次数最多的分类标签作为测试样本的分类。对一条测试样本,计算与训练集中各样本的距离,并找到与其距离最近的k条记录,选择这k个记录中里出现次数最多的分类标签作为测试样本的分类。
计算最近邻时可根据训练集与测试样本的距离进行加权,越近权重越大(加权最近邻);对分布不均的训练集,可将"最近"定义为一定半径内的测试集(限定半径最近邻)。
KNN也可做回归,将一测试样本最近的K个样本对应的标签的平均值作为回归预测值。
- 算法实现:通过构建KDTree和搜索KDTree两步实现。 参考
4.1 构造KDTree:构造KD树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域,每个结点对应于一个K维超矩形区域,形成树形结构以便进行快速检索。根节点是包含所训练集的超矩形,依次对各维度用该维度的中位数做垂直于该维度轴的垂线,将数据分为两部分,形成两个子区域(在超平面上的点留在根节点上);对各部分依次使用下一维度的中位数做垂线,直到每个子区域不可再分,形成叶节点。
球树是KDTree的改进,用超球体切分空间。
scikit-learn里有三种实现方式:蛮力(brute-force,先选出k个样本计算距离列表,再逐一计算训练数据与测试样本的距离,距离更小的就替换之前计算的距离列表中最大者)、KDTree、球树(BallTree)
4.2 搜索KDTree:对于一个目标点,首先在KD树中找到包含目标点的叶节点。以目标点为圆心,以目标点到叶节点样本实例的距离为半径,得到一个超矩形,最近邻的点一定在这个超矩形内。然后返回到叶节点的父节点,检查另一个子节点对应的超矩形体是否和前一超矩形体相交。如果相交,就到这个子节点寻找是否有更加近的近邻,有的话就更新为最近邻。如果不相交,直接返回到父节点的父节点,在另一个子树继续搜索最近邻。当回溯到根节点时,算法结束,此时保存的最近邻节点就是最终的最近邻。
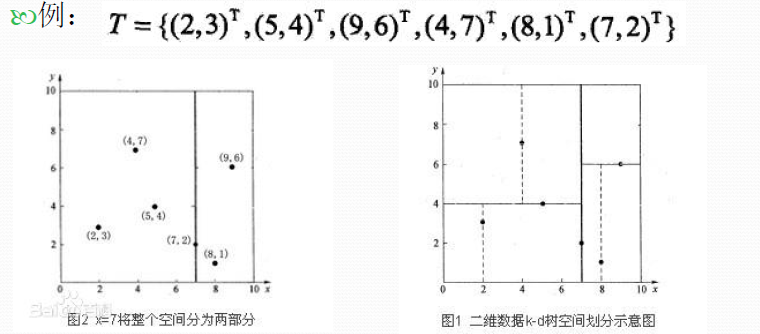
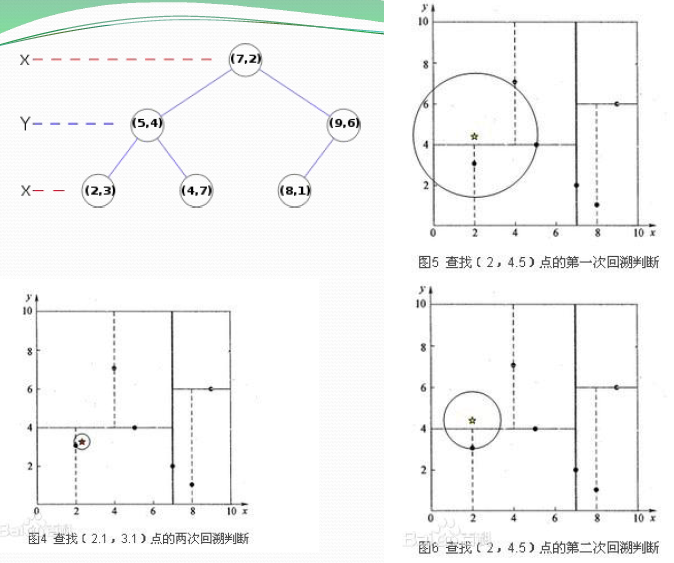
示例:对训练集D:{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}构造KDTree:
1)找到划分的特征。6个数据点在x,y维度上的数据方差分别为6.97,5.37,所以在x轴上方差更大,用第1维特征建树。
2)确定划分点(7,2)。根据x维上的值将数据排序,6个数据的中值(所谓中值,即中间大小的值)为7,所以划分点的数据是(7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于:划分点维度的直线x=7;
3)确定左子空间和右子空间。 分割超平面x=7将整个空间分为两部分:x<=7的部分为左子空间,包含3个节点={(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点={(9,6),(8,1)}。
4)用同样的办法划分左子树的节点{(2,3),(5,4),(4,7)}和右子树的节点{(9,6),(8,1)}。最终得到KD树。
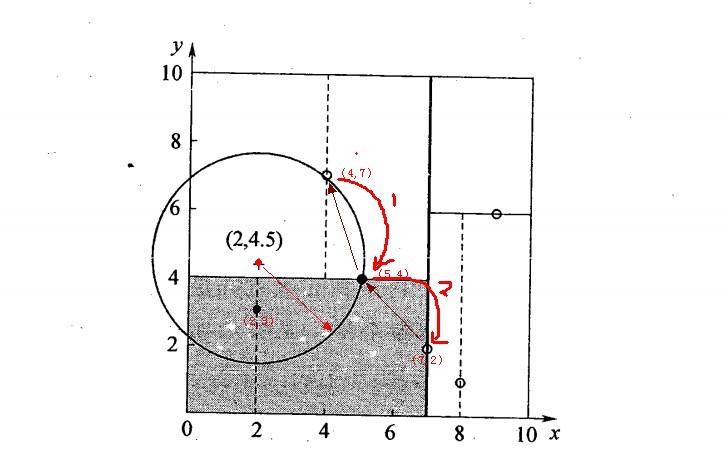
搜索过程:测试样本:(2,4.5)
1)从根节点(7,2)开始查找。找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),确定叶节点。此时形成搜索路径(7,2)->(5,4)->(4,7),以(4,7)为最近邻,距离是3.202。
2)返回叶节点的父节点(5,4),由于(5,4)与查找点间的距离为3.041,所以更新(5,4)为最近邻。
3) 以查找点(2,4.5)为圆心,以3.041为半径作圆,如下图所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)的另一节点进行查找,也就是将(2,3)节点加入搜索路径中得(7,2)->(5,4)->(2,3);于是接着搜索至(2,3)叶节点。
4)查找点距(2,3)比(5,4)要近,将最近邻点更新为(2,3),最近距离更新为1.5
5)继续向上回溯,查找至(5,4)……最终回溯到根结点(7,2),以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如下图所示。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.5。

- K值选择:K过小会使整体模型变得复杂,容易过拟合;K过大会增大学习的近似误差。K一般不超过20,通常为3~10,也可设置为 。
- 距离:
欧式距离:
曼哈顿距离:
闵可夫斯基距离:
三、sklearn
from sklearn import neighbors
1、KNN分类
neighbors.KNeighborsClassifier(n_neighbors=5, weighs="uniform", algorithm="auto", leaf_size=30,
p=2, metric="minkowski", metric_params=None, n_jobs=1, **kwargs)
n_neighors指定近邻个数。weights预测时所用的加权函数,有"uniform"等权重、“distance"距离加权(越近权重越大)、[函数]自定义的函数(以距离矩阵为输入,返回相同大小的矩阵作为权重)。algorithm指定搜索距离的算法,有"kd_tree”、“ball_tree”(球树用超球体切分空间)、“brute”(蛮力解决,对稀疏矩阵仅此可用)、“auto”(根据fit方法的数据自动使用最合适的方法)。leaf_size指定构造BallTree和KDTree时叶节点最少元素数据量(每个叶节点最少元素数量)。p指定Minkowski距离的幂(1是曼哈顿距离、2是欧式距离)。metric指定距离矩阵的计算方法,有"euclidean"欧式距离、"seuclidean"标准化欧氏距离、"chebyshev"切比雪夫距离、"minkowski"闵可夫斯基距离、"wminkowski"带权重的闵可夫斯基距离、"mahalanobis"马氏距离、“precomputed”(fit方法的输入为距离矩阵时用)、自定义函数。metric_params以字典形式传递个距离计算函数的参数。n_jobs并行计算任务数。参考
属性:algorithm计算近邻的方法 leaf_size存储数据的结构中叶节点大小 metric计算距离的方法
n_jobs并行运算任务量
n_neighbors
p
predict
predict_proba
radius
score
set_params
weights
方法:fit(X, y)训练模型。X是训练集特征矩阵、稀疏矩阵、BallTree、KDTree,为距离矩阵时实例化的参数metric=“precomputed”。y是标签数组。
predict(X)对样本进行预测。X是数组。
score(X, y)返回模型准确度(正确预测样本量比例)
kneighbors(X=None, n_neighbors=None, return_distance=True)返回测试样本最近的k个近邻点在原数据中的行索引位置数组和距离矩阵构成的元组(不返回距离矩阵时是数组)(位置索引中一个元素是一个测试样本对应的k个近邻所在行)。X是测试样本集,为距离矩阵时实例化的参数metric=“precomputed”。n_neighbors指定近邻个数。return_distance是否返回距离矩阵,若为True,则返回结果是距离矩阵和k个近邻数据行索引构成的元组。
kneighbors_graph(X=None, n_neighbors=None, mode="connectivity")计算距离测试样本X最近的k个近邻的权重(结果需用toarray()转为数组)。X是测试样本集。n_neighbors是近邻个数。mode是返回的矩阵类型,“connectivity”、“distance”。
get_params()获取实例化的参数设置。
2、最近邻回归
根据K个近邻进行回归,若对一样本根据近邻可分到多个分类中,则会选择数据中先出现的类别。
neighbors.KNeighborsRegressor(n_neighbors=5, weights="uniform", algorithm="auto", leaf_size=30,
p=2, metric="minkowski", metric_params=None, n_jobs=1, **kwargs)
n_neighbors指定近邻个数。weights指定预测时所用的权重方法或函数,有"uniform"等权重、“distance"按距离加权,函数是以距离数组为输入返回相同形状的矩阵作为权重。algorithm指定计算距离的算法名称,有"auto”、“ball_tree”、“kd_tree”、“brute”,本参数对稀疏矩阵无效(只会用brute)。leaf_size指定计算距离的算法BallTree或KDTree的叶节点大小。p指定Minkowski的幂次。metric指定计算距离的具体计算方法,默认Minkowski,也可以是函数。metric_params指定计算距离函数是额外传递的参数。n_jobs指定并行任务数量。
方法:fit(X, y)训练模型。X是训练集特征矩阵、稀疏矩阵、BallTree、KDTree,为距离矩阵时实例化的参数metric=“precomputed”。y是标签数组。
predict(X)对样本进行预测。X是数组。
score(X, y, sample_weight=None)返回**
**。sample_weight是拟合模型时所用权重。
kneighbors(X=None, n_neighbors=None, return_distance=True)返回测试样本最近的k个近邻点在原数据中的行位置索引数组和距离矩阵构成的元组(不返回距离矩阵时是数组)(位置索引中一个元素是一个测试样本对应的k个近邻所在行)。X是测试样本集,为距离矩阵时实例化的参数metric=“precomputed”。n_neighbors指定近邻个数。return_distance是否返回距离矩阵,若为True,则返回结果是距离矩阵和k个近邻数据行索引构成的元组。
kneighbors_graph(X=None, n_neighbors=None, mode="connectivity")计算距离测试样本X最近的k个近邻的权重(结果用toarray()转为数组)。X是测试样本集。n_neighbors是近邻个数。mode是返回的矩阵类型,“connectivity”、“distance”。
3、限定半径最近邻分类
将一定半径内的点取代k近邻点(适用于采样不均的数据,可通过交叉验证选择合适的半径)。
neighbors.RadiusNeighborsClassifier(radius=1, weights="uniform", algorithm="auto", leaf_size=30,
p=2, metric="minkowski", outlier_label=None, metric_params=None, **kwargs)
radius指定近邻判断范围半径。weights指定预测时所用的权重方法或函数,有"uniform"等权重、“distance"按距离加权,函数是以距离数组为输入返回相同形状的矩阵作为权重。algorithm指定计算距离的算法名称,有"auto”、“ball_tree”、“kd_tree”、“brute”,本参数对稀疏矩阵无效(只会用brute)。leaf_size指定计算距离的算法BallTree或KDTree的叶节点大小。p指定Minkowski的幂次。metric指定计算距离的具体计算方法,默认Minkowski,也可以是函数。metric_params指定计算距离函数是额外传递的参数。outlier_label以数值指定边界点的标签(无近邻的点),若为None而有边界点,则产生ValueError异常。n_jobs指定并行任务数量。
方法:fit(X, y)训练模型。X是训练集特征矩阵、稀疏矩阵、BallTree、KDTree,为距离矩阵时实例化的参数metric=“precomputed”。y是标签数组。
predict(X)对样本进行预测。X是数组。
score(X, y)返回模型准确度(正确预测样本量比例)
4、限定半径最近邻回归
neighbors.RadiusNeighborsRegressor(radius=1.0, weights='uniform', algorithm='auto', leaf_size=30,
p=2, metric='minkowski', metric_params=None, **kwargs)
radius指定近邻判断范围半径。weights指定预测时所用的权重方法或函数,有"uniform"等权重、“distance"按距离加权,函数是以距离数组为输入返回相同形状的矩阵作为权重。algorithm指定计算距离的算法名称,有"auto”、“ball_tree”、“kd_tree”、“brute”,本参数对稀疏矩阵无效(只会用brute)。leaf_size指定计算距离的算法BallTree或KDTree的叶节点大小。p指定Minkowski的幂次。metric指定计算距离的具体计算方法,默认Minkowski,也可以是函数。metric_params指定计算距离函数是额外传递的参数。
5、最近质心分类
选择最近质心来进行分类。
neighbors.NearestCentroid(metric='euclidean', shrink_threshold=None)
shrink_threshold指定特征收缩的阈值。
6、其他有用函数
6-1计算样本最近邻的连接矩阵(系数矩阵或距离)
返回用KNN时和每个样本最近的k个训练集的位置
neighbors.kneighbors_graph(X, n_neighbors, mode='connectivity', metric='minkowski',
p=2, metric_params=None, include_self=False, n_jobs=1)
返回距本样本距离最近的n个样本的系数矩阵(0/1或距离)[n_sample, n_sample],A[i, j]表示将j是否属于i的最近n个样本或距离。
X是样本数据。n_neighbors每个样附近的样本个数。mode返回矩阵类型,有"connectivity"(返回0/1表示的连接矩阵)、“distance”(返回一个样本到其最近n个样本的距离矩阵)。metric计算一个样本到其最近样本的计算方法,默认"minkowski"。p指定minkowski距离的指数值,1为曼哈顿距离(l1)、2为欧式距离(l2),也可以为其他数值。metric_params用字典表示的计算距离矩阵的其他关键字参数。include_self是否计算样本到其自身距离,为True时用于mode=“connectivity”;False用于mode=“distance”。n_jobs指定并行计算任务数。
方法:toarray()以数组显示矩阵。
6-2返回用限定半径最近邻算法时和每个样本在限定半径内的训练集样本位置
neighbors.radius_neighbors_graph(X, radius, mode='connectivity', metric='minkowski',
p=2, metric_params=None, include_self=False, n_jobs=1)
6-3返回用KNN时每个样本最近的k个训练集样本的位置,也可返回用限定半径最近邻法时和每个样本最近邻的训练集样本位置
neighbors.NearestNeighbors(n_neighbors=5, radius=1.0, algorithm='auto', leaf_size=30, metric='minkowski',
p=2, metric_params=None, n_jobs=1, **kwargs)
通常用在聚类模型中
7. 示例代码:
import numpy as np
from sklearn import neighbors
from sklearn.datasets.samples_generator import make_blobs
from matplotlib import pyplot
centers = [[-2,2],[2,2],[0,4]]
X, y = make_blobs(n_samples=60, centers=centers, random_state=0, cluster_std=0.6)
c = np.array(centers)
k=5
clf = neighbors.KNeighborsClassifier(n_neighbors=k)
clf.fit(X,y)
X_sample=np.array([[0,2]])
y_sample=clf.predict(X_sample)
n_neighbors = clf.kneighbors(X_sample, return_distance=False)
clf.kneighbors_graph(X=X, n_neighbors = k, mode = "connectivity").toarray()
pyplot.figure(figsize = (16, 10), dpi = 144)
pyplot.scatter(X[:,0], X[:,1], c = y, cmap="cool", s = 20)
pyplot.scatter(c[:,0], c[:,1], c = "orange", marker = "p", s = 20)
pyplot.scatter(X_sample[:, 0], X_sample[:, 1], c = y_sample, cmap = "cool", s = 20, marker = "x")
for i in n_neighbors[0]:
pyplot.plot([X[i, 0], X_sample[:, 0]], [X[i, 1], X_sample[:, 1]],
'--', linewidth = 0.6, c = "red")`
四、R语言
library(class)
knn(train, test, cl, k=1, l=0, prob=FALSE, use.all=TRUE) #基于欧式距离
train是训练集数据框或矩阵(不含分类结果)。test是测试机数据框或矩阵。cl是训练集个样本的分类因子向量。k最近邻样本个数。l最低票数占比,否则为doubt即NA。prob是否返回确定分类时的票数占比。use.all选择k个最近样本时对节点数据的处理,T时会选择所有节点,F会从节点中随机挑选以满足k个样本。
CrossTable(x, y, prop.chisq=T) #查看结果列联表,有卡方检验结果,属于gmodel包