版权声明:转载必须经过本人同意,并且注明文章来源! https://blog.csdn.net/weixin_41665360/article/details/88639000
1、YOLO_v2 VS YOLO_v1
根据
YOLO 的误差分析(参考论文笔记:YOLO),
YOLO 定位误差高,而且相比于基于区域提议的方法,
YOLO 的召回率偏低。 针对这两点,
YOLO_v2 做了以下改进:
- 在所有的卷积层后增加
BatchNormalization 这可以显著改善网络的收敛性,并且有利于正则化模型,防止过拟合。增加
BN 以后移除网络的
dropout。这将
mAP 提升
2%。
- 高分辨率分类器
YOLO 使用
224×224 分辨率图像训练分类网络,并且将分辨率增加到
448 用于检测。这意味着网络需要同时学习目标检测并且适应新的输入分辨率;
YOLO_v2 首先在
448×448 分辨率图像上微调分类器网络,使其更好地调整卷积核适应高分辨率。微调
10 epochs 以后,再微调网络用于检测任务。 这将
mAP 提升
4%。
- 移除全连接层,使用锚框预测边界框
YOLO_v2 首先去除了一个池化层使网络卷积层的输出有更大的分辨率。然后收缩网络处理
416×416 的输入图像,取代
448×448 分辨率图像。这样通过
32 降采样因子,网络输出特征图大小为
13×13;
YOLO_v2 将类预测机制与空间位置分离,为每个锚框预测类和目标。
YOLO 在每幅图像仅预测
98 个框,但是
YOLO_v2 在每幅图像预测超过
1000 个框。使用锚框导致精度略微下降,但是召回率显著提高。
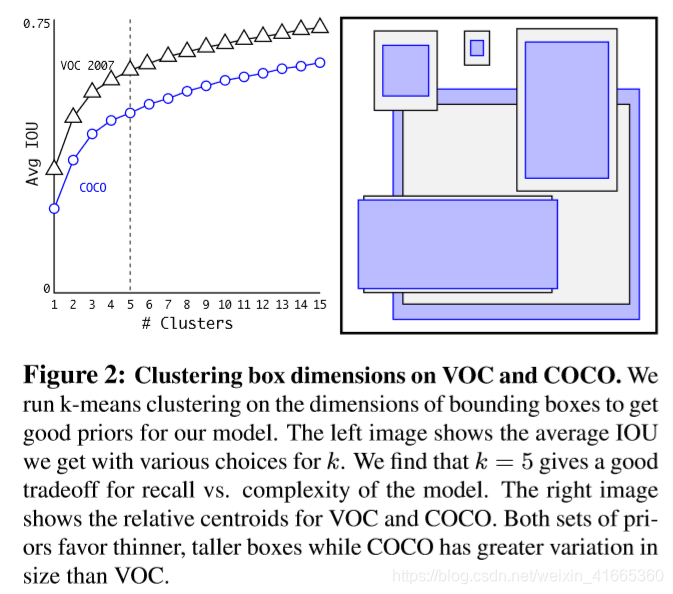
- 尺寸聚类 通过在训练数据集上运行
k−means 聚类算法,为预测框找到较优的先验尺寸。由于
IOU 分数独立于框的大小,因此使用以下度量准则:
d(box,centroid)=1−IOU(box,centroid)
图
2 给出了
k 值与平均
IOU 的关系,考虑召回率和模型复杂度的折衷,选择
k=5。
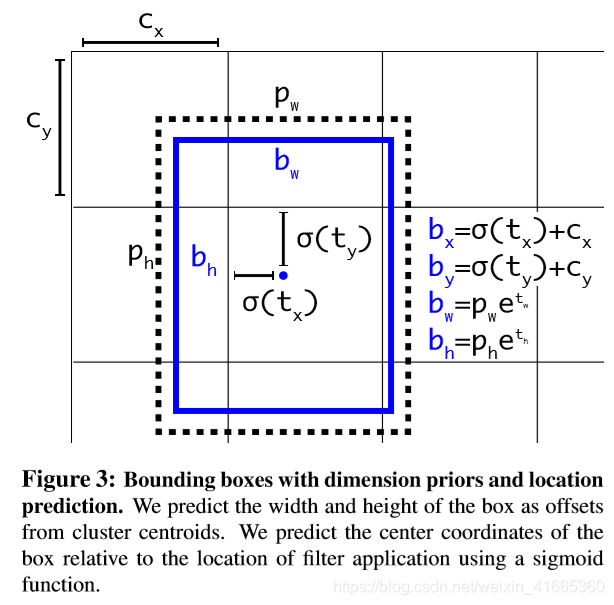
- 直接位置预测:由于位置偏移量预测没有约束锚框的中心坐标,随机初始化可能导致要花费很长时间才能使模型稳定下来,因此
YOLO_v2 直接预测相对于网格位置的定位坐标。 输出特征图的每个网格预测
5 个边界框,每个边界框预测
5 个坐标值
tx,ty,tw,th,to。若网格偏离图像左上角
(cx,cy) 边界框先验的宽和高为
pw,ph:
Pr(object)bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=pheth∗IOU(b,object)=σ(to)
使用尺寸聚类并直接预测边界框中心坐标将
mAP 提高大约
5%。
- 细粒度特征
YOLO_v2 在
13×13 特征图上进行检测。虽然这对于大目标来说是足够的,但是对于定位较小目标来说,它可能需要更细粒度的特征。
YOLO_v2 简单添加一个
Passthrough 层,获取
26×26 分辨率的早期特征。
Passthrough 层类似于
ResNet 中的恒等映射,通过将相邻特征堆叠到不同的通道而不是空间位置,来连接高分辨率特征和低分辨率特征。这将
26×26×512 的特征图转换为
13×13×2048 的特征图,可以与原始特征连接。这使得性能略微提高了
1%。
- 多尺度训练
YOLO 使用分辨率为
448×448 的输入。
YOLO_v2 输入分辨率为
416×416。为了使
YOLO_v2 在不同大小的图像上运行更加鲁棒,训练时每
10 batches 网络选择一个新的图像尺寸。由于模型降采样因子为
32 ,图像尺寸从
{320,352,...,608} 中选择。这种机制迫使网络学会在各种输入尺寸上进行良好的预测。这意味着相同的网络可以以不同的分辨率预测检测。网络在较小的尺寸下运行更快,因此
YOLOv2 提供了速度和精度之间的简单折衷。
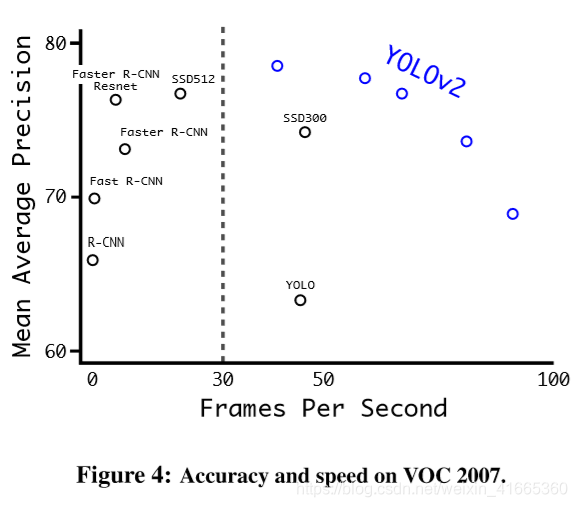
2、Brief Summary
2.1、Bounding Boxes 和 Anchor Boxes 比较
-
Bounding Boxes 对应每个网格,每个
Bounding Boxes 仅生成
5 个预测值,即
(x,y,w,h,p)。
(x,y) 为预测框中心相对于网格边界的坐标。
(w,h) 为预测框相对于整幅图像的宽度和高度。每个网格预测
C 个类概率值,因此,
YOLO 输出为
S×S×(B×5+C) 维的张量
-
Anchor Boxes 是从标记好的训练集中,通过
k−means 聚类算法获得的目标边界框的先验尺寸。它可以帮助训练过程尽快收敛,增加回归过程的稳定性。每个网格对应
A 个锚框,输出大小为
A×(5+C),每个量的含义见
1.5。
其实可以简单地将
Anchor Boxes 理解为特殊的
Bounding Boxes,区别在于
Anchor Boxes 在
Bounding Boxes 的基础上又添加了尺度约束,可以对预测框的尺度大小进行较优的初始化,从而改善收敛。
2.2、YOLO_v1和YOLO_v2设计比较
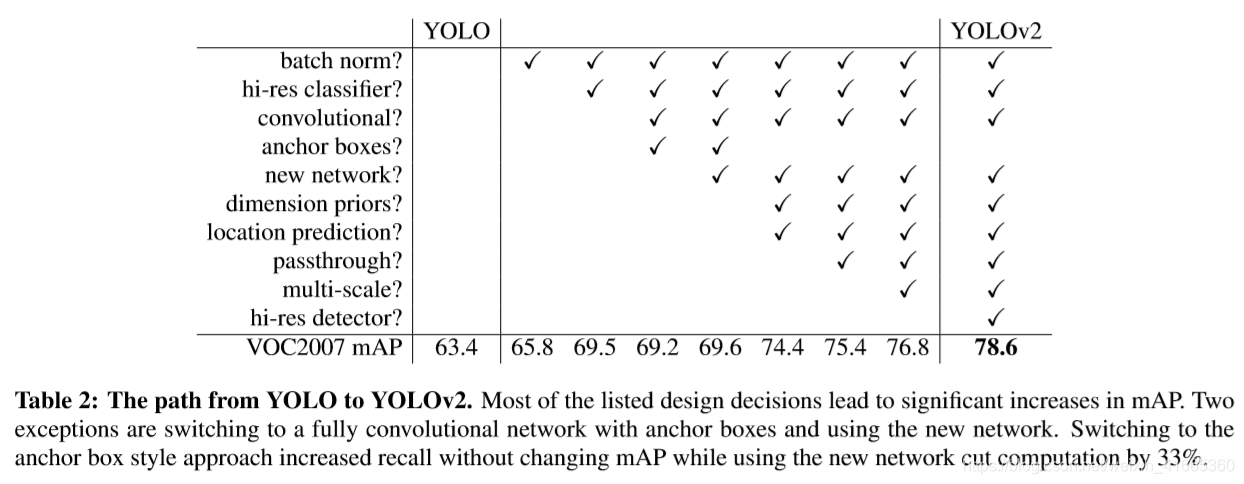
2.3、YOLO_v1和YOLO_v2性能比较
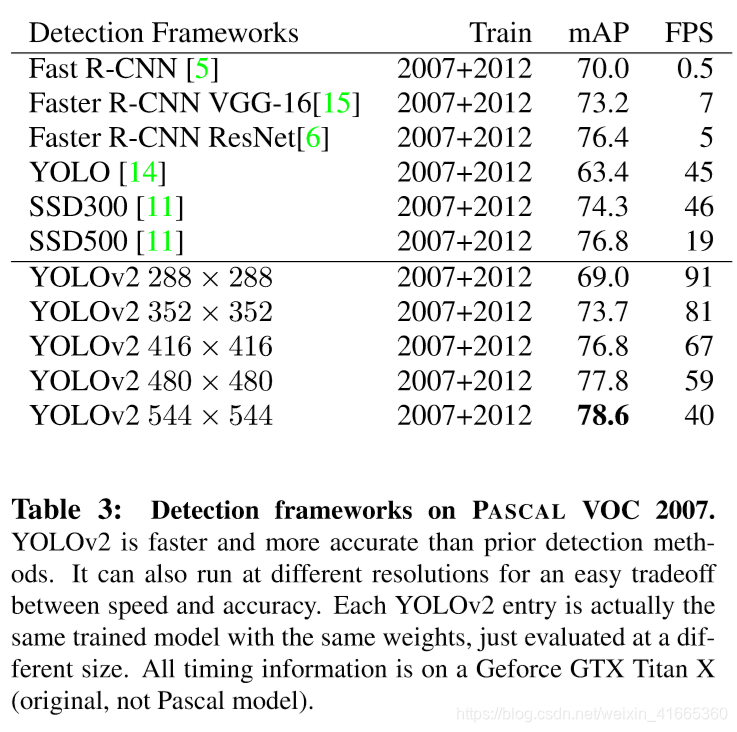
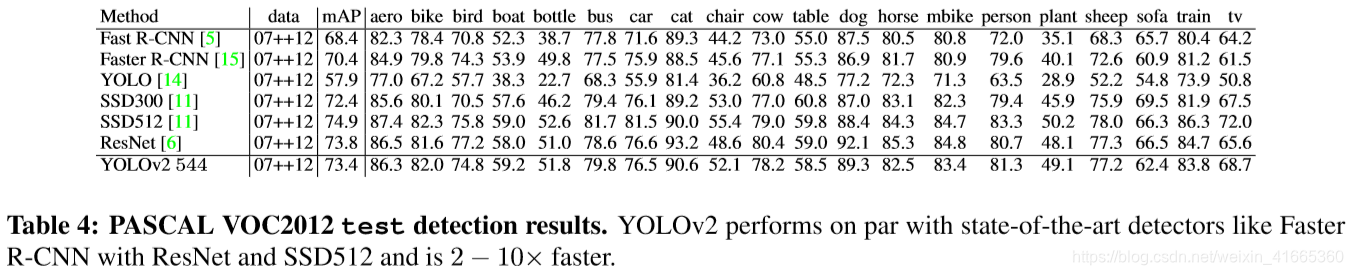
3、YOLOv3
3.1、YOLOv3 特点
- 系统只为每个
ground truth 分配一个先验框。如果先验框未分配给
ground truth ,则不会对坐标或类别预测造成损失,只有目标置信度损失。
-
YOLOv2 每个网格分配
5 个锚框,
YOLOv3 为每个网格分配
3 个尺度的锚框,每个尺度分配
3 个锚框,一共使用
9 个锚框。输出为
N×N×[3∗(4+1+80)] 维度的张量,
80 为预测的类别数量。
-
YOLOv3 并没有像
YOLOv2 使用很多技巧来提升性能,主要是网络结构的优化。以下是
darknet19 和
darknet53 的网络结构图。


性能比较:
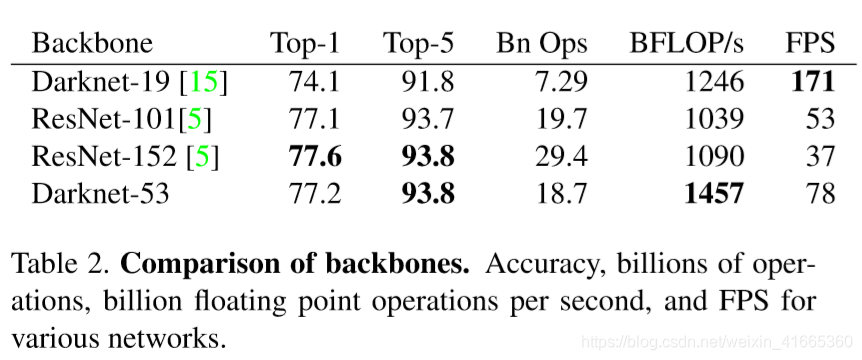
从图中结果可以看出,
Darknet53 比
Darknet19 性能更优,而且比
ResNet−101 和
ResNet−152 更有效率。
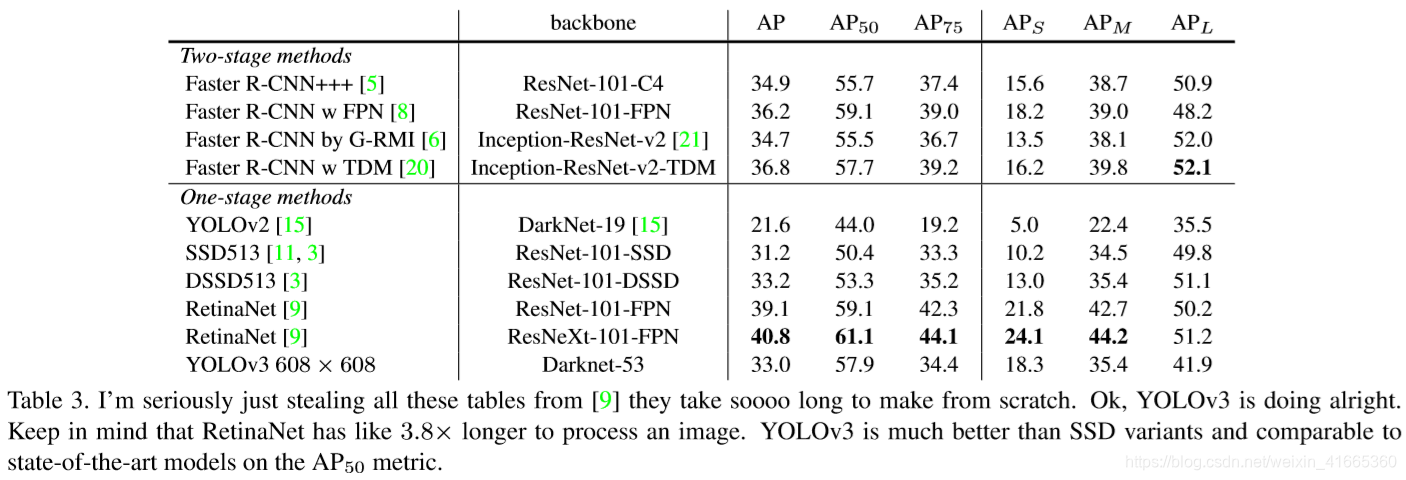
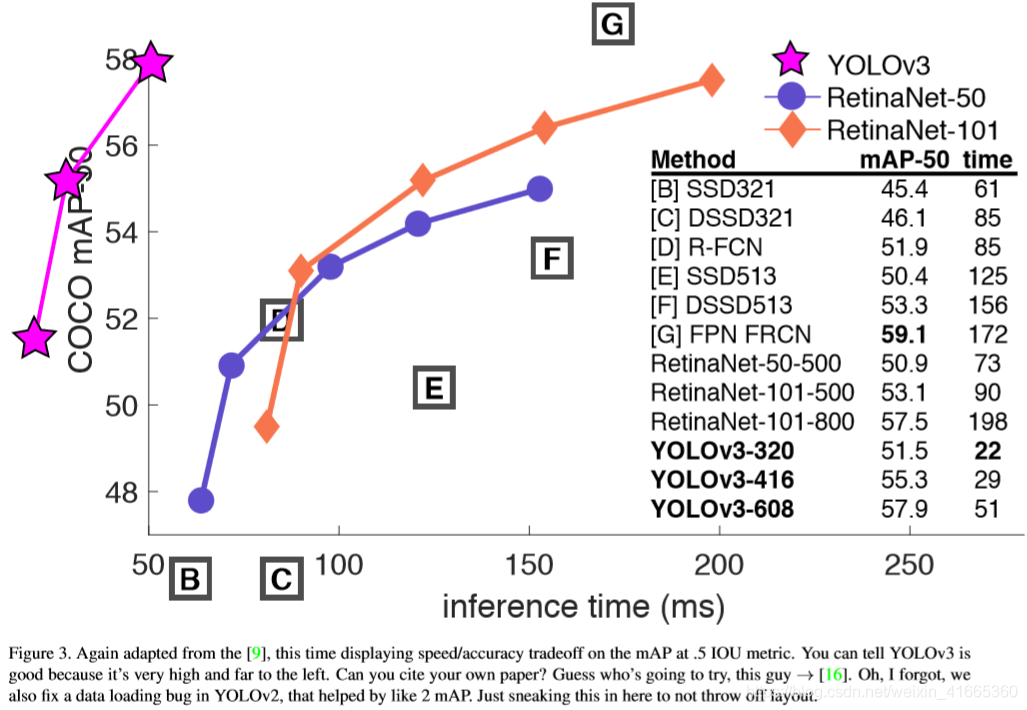
3.2、作者的尝试
锚框偏移量预测
作者尝试使用普通锚框预测机制,使用线性激活将
x,y 偏移预测为框宽或框高的倍数。最后发现这个描述降低了模型的稳定性,并且效果不太好。
线性 x,y 预测取代 logistic
使用线性激活取代逻辑激活来预测
x,y 偏移量。这导致
mAP 下降了几个点。
焦点损失
作者尝试使用焦点损失,导致
mAP 下降了
2 点。
YOLOv3 对于焦点损失试图解决的问题可能已经很鲁棒了,因为它有独立的目标预测和条件类预测。因此,对于大多数例子来说,类预测没有损失?还是什么?不完全确定。
双 IOU 阈值和真值分配
Faster R−CNN在训练中使用两个
IOU 阈值。如果一个预测与某一
ground truth 重叠
0.7,这是一个正例,
[.3−.7] 忽略,与所有
ground truth 重叠小于
0.3,则判断为一个负例。作者尝试了类似的策略,但没有得到好的结果。
4、整理的不是很好,有问题欢迎大家批评指正!