目录
前言
yolov2是在yolov1的基础上进行改进的,主要解决了yolov1定位不准确以及检测重叠的物体极差的情况,总的来说,它有以下改进:
- BN层取代了Dropout
- 使用了高分辨率分类器
- K-means选定先验框的尺寸
- 网络结构—darknet19
- 细粒度的特征
BN层取代了Dropout
在yolov1的基础上添加了Batch Normalization,BatchNorm层和Dropout层在一定程度上都可以抑制过拟合,但其工作机制有所不同,Dropout会随机让一些节点输出为0,用来增加模型的泛化能力,在一定的程度上起到了正则化作用,但Dropout会降低训练时的信息流通,收敛速度变得更慢,而BatchNorm层通过对每个batch做标准化,使得信息在层与层之间传递时分布更稳定。这也起到一定的正则作用,并可以 accelerate 网络的训练。
相比Dropout,BatchNorm的优点是:
-
对特征分布做标准化,使得梯度传播更顺畅,起到加速训练的效果
-
在测试时不丢弃任何节点,保留了完整的网络结构
-
对小batch size更友好
因此,在目标检测任务中,特别是对batch size敏感的一阶段检测网络中,使用BatchNorm可以获得更好的效果,成为了标准配置。随着BatchNorm层的引入,yolov2和v3收敛速度更快,效果也有所提升。
可以说,BN层在一定程度上取代了yolov1中的Dropout层,成为yolo后续版本的标准组件之一。
使用了高分辨率分类器
yolov2相比v1使用了更高分辨率的图像进行分类网络的预训练,这也是YOLOv2取得提升的一个重要原因。
YOLO 对应训练过程分为两步,第一步是通过 ImageNet 训练集 进行高分辨率的预训练,这一步训练的是分类网络;第二步是训练检测网络,是在分类网络的基础上进行微调。
yolov1使用224x224的较低分辨率图像预训练分类网络。而在yolov2中,作者将预训练时使用的图像分辨率提高到了448x448。
使用更大分辨率的图像可以学习到更丰富的特征表示,有利于提升模型的检测效果。文中也报告称,更高分辨率预训练可以使mAP提高约4%。
此外,YOLOv2还改进了网络结构,加深了网络层数,进一步提升了特征表达效果。
K-means选定先验框的尺寸
YOLOv2的先验框选择方法如下:
-
收集训练数据集中真实框的宽高信息
-
对真实框的宽高按比例进行聚类,获得多个宽高比例cluster
-
为每个cluster计算一个平均宽高(即先验框的宽高)
-
对不同特征层,分别进行上述步骤,获得该特征层的多个先验框
与yolov1直接人工设置不同,YOLOv2的先验框是通过K-means算法对真实框统计聚类得到的。这种方法可以让先验框更贴近数据集的真实分布情况,从而提升检测效果。
网络结构—darknet19
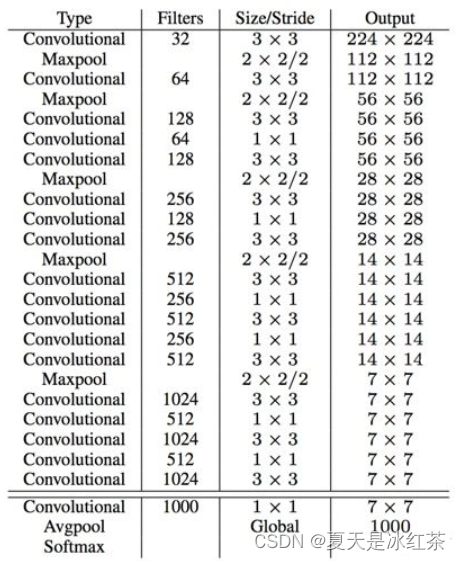
Darknet-19主要特点包括:
仅使用3x3卷积层和2x2最大池化层堆叠构建,没有全连接层
从空间维度不断下采样,逐步减小特征图尺寸,增加通道数
在Darknet结构上增加了批标准化(BatchNorm)层
19层网络深度,相比VGG16等要浅一些
Darknet-19作为分类网络预训练后,YOLOv2在其基础上进行了扩展,它加入了回归预测层、类别预测层等用于检测的层,在多尺度特征层上进行检测,提高小目标检测效果,并且使用了特征融合的方式提升检测精度。
细粒度的特征
其实就是为了增强网络对于小物体检测的能力,但提升效果不明显,这一缺点在v3版本中有巨大改进。具体来说,YOLOv2在预测层前融合了不同层级的特征,包括:
(1)原13x13的特征层
(2)通过上采样获得的26x26特征层
(3)通过上采样获得的52x52特征层
这多尺度的特征融合提供了不同粒度的信息。较高分辨率的特征具有更细致的纹理信息,有利于小物体检测。但是论文结果也显示,这种multi-scale特征在YOLOv2中对检测小物体的提升非常有限(mAP提升 only 2%)。原因在于 uprising 过程中会丢失许多定位信息。此外小物体特征稀疏,容易在融合中被丢弃。