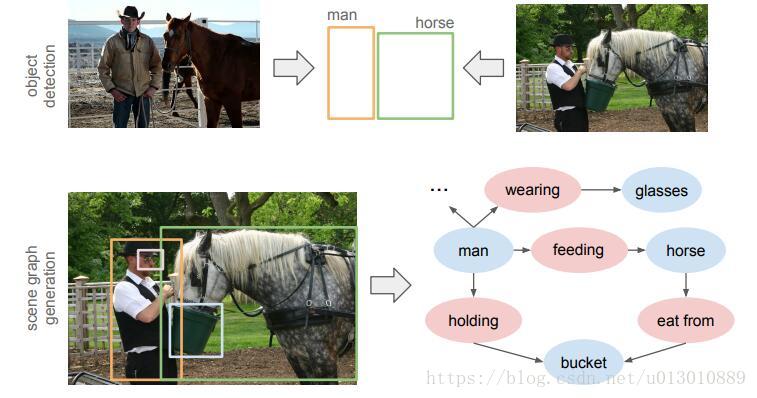
计算机视觉一步步发展,从最初的分类、检测、分割来到了更深层的理解: Scene Graph Generation(场景图生成),即开始预测场景中物体之间的关系
Scene Graph简介
原有的检测box或者实例分割的mask不能充分地表达出图片的语义,因为两个相同的box/mask,可能是不同的语义,这个时候需要Scene Graph来能深层地理解图片的语义信息,这为caption、text2imgage等打下基础。

两个发现
Prevalent(普遍) Relations in Visual Genome
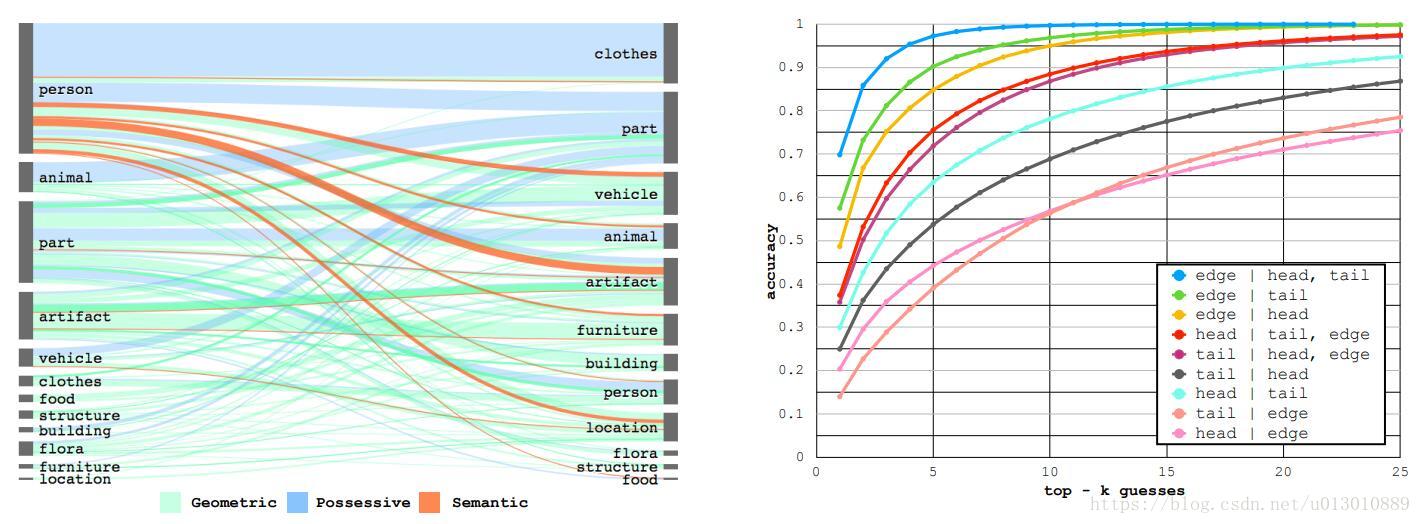
VG数据库中主要由这3种关系组成: geometric(几何): 50.9%, possessive(所有格): 40.9% semantic(语义): 8.7%.
然后本文首先从数据库中发现衣服、身体部件大多是所有格关系;家具、建筑大多是几何关系;人大多是语义关系的主语,这些都说明我们在生成SG时有很多先验可以利用
然后本文就做了右图的实验: 我们可以从最高的蓝色曲线看到,给出主语(head)和宾语(tail)的label后(没有任何图片特征,只有类别信息)能够很好地预测出relation(edge),top5时达到了97%的精度。然而给出relation,却很难预测出主语或宾语。这个实验给我们的启发是我们在预测relation时一定要利用主语宾语的类别信息
Larger Motifs(模板)
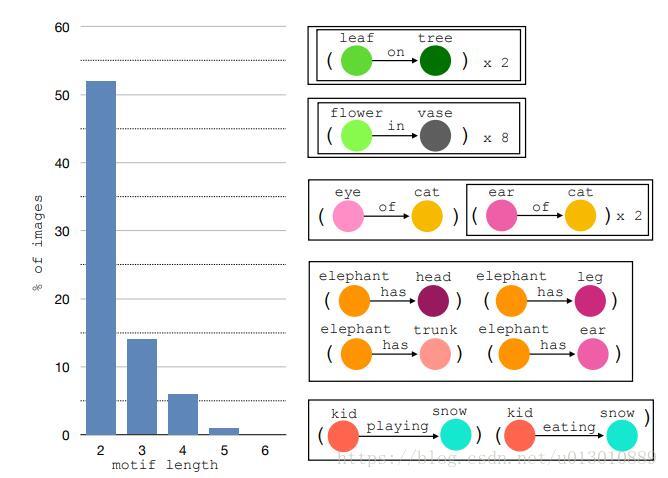
SG不仅有上文描述的普遍存在的局部结构(先验),全局里也有类似的结构特点。motif我翻译成了模板,即关系对(主语类别,关系,宾语类别)中至少2个一样,不区分instance。比如第一、二个是关系对中的3个都一样。第三个 eye of cat和ear of cat是关系对中的2个(关系和宾语)一样即of cat。第4个中的motif也是关系对中的2个(主语和关系)一样即elephant has,第5个中的motif也是关系对中的2个(主语和宾语)一样即kid snow
motif length代表一张图片中出现某一motif的次数。结果发现,有50%的图片中有长度是2的motif,也就是说某一motif在这些图片中出现一次的情况下,大概率还会出现第二次,就像上图中的elephant has一样,一下出现了4次。这启发我们在预测关系的时候要考虑全局上下文信息,即要考虑全局中出现的motif,它们之间也是有联系的
Framework
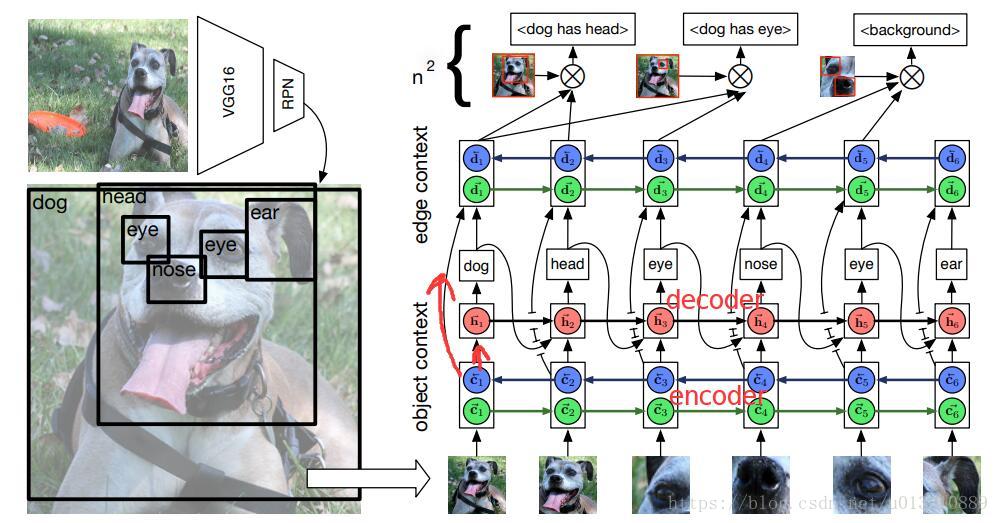
该框架分为两个context:
- object context: 将所有roi的特征送到rnn中进行encoding,得到带有object context的特征,然后这些refine后的特征一方面送到decoder里解码预测类别,另一方面送到edge context那边
- edge context: 将上一步预测出来的类别embeding后和refine后的特征进行cat然后送入rnn,这样为了给预测关系时用的特征加入context,就是上文说关系和主语宾语的类别十分相关而且图片中的motif经常出现多次
Experiments
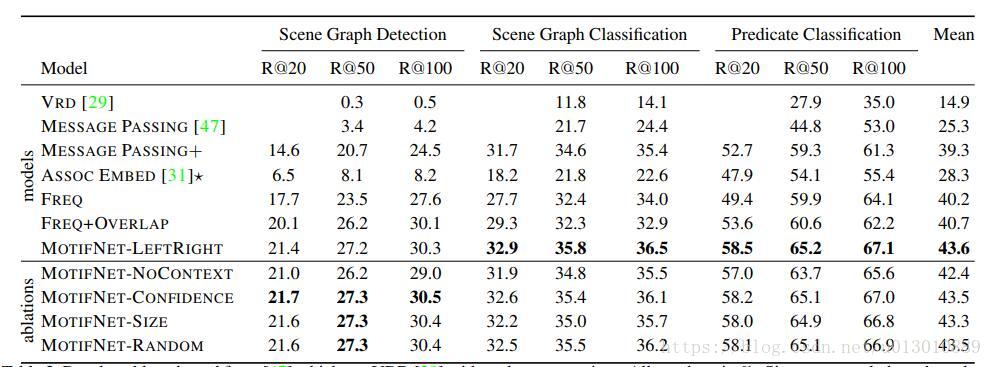
注意FREQ这个实验,这是直接拿到faster rcnn生成的box和其类别信息,不用图片的特征,然后就直接从之前统计的P(Relation| Subject, Object)预测这两个box的relation,结果发现竟然已经超过Message Passing方法很多了。+OVERLAP是指只预测两个box有overlap的,没有overlap即视为它俩没有关系。
当然用了motif,也就是加了box特征后还是有提高的,加了context后进一步提高。最后对比了一下这些box送入rnn的顺序,按从左到右或者大小或者置信度或者随机,差别不是很大,最后选择了从左到右。