FastText简介
预备知识
N-gram模型
对句子或单词的所有长度为N的子句或子字符串进行操作,如2-gram中,对“girl”的字符串为“gi”,“ir”,"rl"进行操作,通常有操作如下:
- 比较两个单词的相似度,即按照公式根据子字符串的匹配情况计算出相似度,常用于模糊匹配、单词纠错等
- 评估句子是否合理,将句子定义为N阶马尔科夫链,即 ,根据语料库得到的条件概率可求得句子出现在该语料库中的概率,常用于搜索引擎中输入提示、文本自动生成等
CBOW模型
是把单词的高维稀疏的one-hot向量映射为低维稠密的表示的方法。
模型架构如下:
(此处有图)
- 输入:给定词的上下文共 个单词,每个单词由 维的一个1-of-V的向量表示,即
- 映射:每个单词乘以一个 的输入矩阵 ,求和得到一个 维的中间向量 ,即
- 输出: 乘以一个 的输出矩阵 ,得到一个 维向量,每一维做 得到这个单词出现的概率,选择其中最大的 个作为输出
FastText模型
[1]中提出了FastText模型,类似CBOW模型,使用n-gram特征代替单个词的特征,提取序列信息,效果与深度学习分类器持平,但速度快得多。其模型架构如下:
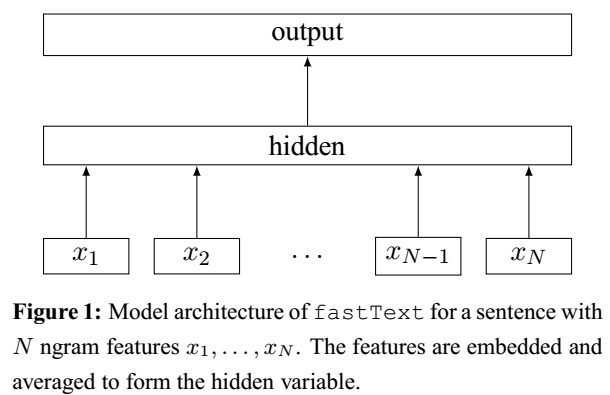
- 对整篇文档的n-gram特征,计算词向量,取平均得到文档的向量表示
- 将上述文档向量作为线性分类器的输入,并使用层次softmax计算文档属于每个类别的概率
- 将所有类别按照频率构建哈夫曼二叉树,每次对两个类别进行二分类(如使用LR),决定走左子树或右子树,将复杂度由线性降低为对数
- 损失函数为对数似然函数取负,即
NCE loss(noise-contrastive estimation),噪声对比估计。
在词向量的生成过程中,用的loss函数是NCE或negative sampling,而不是常规的softmax。在《learning tensorflow》这本书中,作者这样说道:but it is sufficient to think of it (NCE) as a sort of efficient approximation to the ordinary softmax function used in classification tasks。由此看来,NCE是softmax的一种近似,但是为什么要做这种近似,而不直接用softmax呢?
当类别数很大时(CBOW中是单词数),softmax复杂度很高,为了更高效地进行,将softmax计算过程转化为二分类(LR)。具体地,将单词与真实类别的true pair、单词与随机类别的randomly corrupted pair送入分类器,待优化的分类器只需判断输入的pair是真或假即可。(主要思想与负采样和层次softmax相同)
Word2Vec slightly customizes the process and calls it negative sampling.
def nce_loss(weights, #[num_classes, embed_size]
biases, #[num_classes]
inputs, #[vocab_size, embed_size]
labels, #[vocab_size, num_true]
num_sampled, num_classes, num_true=1,
sampled_values=None,
remove_accidental_hits=False,
partition_strategy="mod",
name="nce_loss")
个人理解:对input中的每个词,选择对应的标签构成正样本对,再随机选择num_sampled个标签与该词构成负样本对。对每个单词对,在weights和biases中找到对应标签的w和b,用逻辑回归进行二分类,每个分类问题计算交叉熵
Reference
[1] Bag of Tricks for Efficient Text Classification