在上一篇笔记中,我们使用了所有常用的情感分析技术,成功地达到了大约84%的测试精度。在本笔记本中,我们将实现一个模型,得到可比的结果,同时训练效果明显更快,使用大约一半的参数。更具体地说,我们将实现来自论文Bag of Tricks for Efficient Text Classification的“FastText”模型。
准备数据
FastText论文的一个关键概念是,它们计算输入句子的n-gram,并将它们附加到句子的末尾。这里,我们用bi-grams。简单地说,bi-gram是在一个句子中连续出现的一对单词/标记。
例如,在“how are you ?”句子中,bi-grams是:“how are”,“are you”和“you ?”
generate_bigrams函数接受一个已经被标记化的句子,计算bi-grams并将它们附加到标记化的列表的末尾。
def generate_bigrams(x):
n_grams = set(zip(*[x[i:] for i in range(2)]))
for n_gram in n_grams:
x.append(' '.join(n_gram))
return x
例如:
generate_bigrams(['This', 'film', 'is', 'terrible'])
['This', 'film', 'is', 'terrible', 'This film', 'film is', 'is terrible']
TorchText字段有一个预处理参数。这里传递的函数将在句子被标记化之后(从字符串转换为标记列表时),但在句子被数字化之前(从标记列表转换为索引列表时)应用于句子。这就是我们传递generate_bigrams函数的地方。因为我们没有使用RNN,所以我们不能使用打包填充序列(packed padded sequences),因此我们不需要设置include_length = True。
import torch
from torchtext import data
from torchtext import datasets
SEED = 1234
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
TEXT = data.Field(tokenize='spacy', tokenizer_language='en_core_web_sm', preprocessing=generate_bigrams)
LABLE = data.LabelField(dtype=torch.float)
与之前一样,我们加载IMDb数据集并创建分割。
import random
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
train_data, valid_data = train_data.split(random_state = random.seed(SEED))
构建词汇表并加载预先训练的单词嵌入。
MAX_VOCAB_SIZE = 25_000
TEXT.build_vocab(train_data,
max_size = MAX_VOCAB_SIZE,
vectors = "glove.6B.100d",
unk_init = torch.Tensor.normal_)
LABEL.build_vocab(train_data)
并创建迭代器。
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size = BATCH_SIZE,
device = device)
搭建模型
这个模型的参数比之前的模型少得多,因为它只有两个层,即嵌入层和线性层。在视线中没有RNN组件!
相反,它首先使用嵌入层(蓝色)计算每个单词的词嵌入,然后计算所有词嵌入的平均值(粉色),并通过线性层(银色)提供预测结果,就是这样!
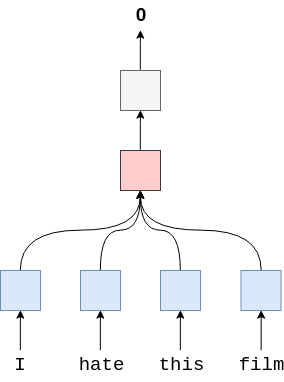
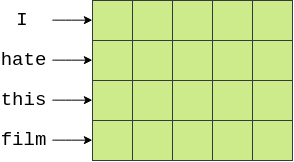
我们使用avg_pool2d(average pool 2-dimensions 2维平均池)函数实现平均计算。最初,你可能会认为使用二维池似乎很奇怪,我们的句子肯定是一维的,而不是二维的?然而,您可以将单词嵌入看作是一个二维网格,其中单词沿着一个轴,单词嵌入的维度沿着另一个轴。下图是转换为5维词嵌入后的示例句子,词沿纵轴,词嵌入沿横轴。这个[4x5]张量中的每个元素都用一个绿色块表示。
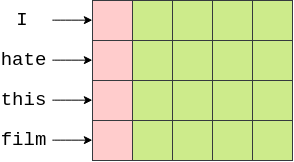
avg_pool2d使用embedded.shape1乘以1的形状的过滤器。下图中粉红色的部分显示了这一点。
我们计算过滤器覆盖的所有元素的平均值,然后过滤器向右滑动,计算句子中每个单词的下一列嵌入值的和的平均值。
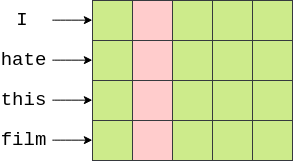
过滤器每滑过一个位置为我们提供一个值,即所有覆盖元素的平均值。当过滤器覆盖了所有的嵌入维度后,我们得到一个[1x5]的张量。然后这个张量通过线性层来产生我们的预测。
import torch.nn as nn
import torch.nn.functional as F
class FastText(nn.Module):
def __init__(self, vocab_size, embedding_dim, output_dim, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
self.fc = nn.Linear(embedding_dim, output_dim)
def forward(self, text):
#text = [sent len, batch size]
embedded = self.embedding(text)
#embedded = [sent len, batch size, emb dim]
embedded = embedded.permute(1, 0, 2)
#embedded = [batch size, sent len, emb dim]
pooled = F.avg_pool2d(embedded, (embedded.shape[1], 1)).squeeze(1)
#pooled = [batch size, embedding_dim]
return self.fc(pooled)
与以前一样,我们将创建FastText类的一个实例。
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
OUTPUT_DIM = 1
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = FastText(INPUT_DIM, EMBEDDING_DIM, OUTPUT_DIM, PAD_IDX)
看看我们模型中的参数数量,我们看到我们与第一个笔记中的标准RNN几乎相同,而只有前一个模型的一半参数。
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
The model has 2,500,301 trainable parameters
把预先训练好的向量复制到嵌入层。
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
tensor([[-0.1117, -0.4966, 0.1631, ..., 1.2647, -0.2753, -0.1325],
[-0.8555, -0.7208, 1.3755, ..., 0.0825, -1.1314, 0.3997],
[-0.0382, -0.2449, 0.7281, ..., -0.1459, 0.8278, 0.2706],
...,
[ 0.3199, 0.0746, 0.0231, ..., -0.3609, 1.1303, 0.5668],
[-1.0530, -1.0757, 0.3903, ..., 0.0792, -0.3059, 1.9734],
[-0.1734, -0.3195, 0.3694, ..., -0.2435, 0.4767, 0.1151]])
不要忘记将未知《unk》和填充《pad》标记的初始权重归零。
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
训练模型
训练模型和上次完全一样。
我们初始化优化器…
import torch.optim as optim
optimizer = optim.Adam(model.parameters())
我们定义标准(criterion),并将模型和标准(criterion)放在GPU上(如果有的话)…
criterion = nn.BCEWithLogitsLoss()
model = model.to(device)
criterion = criterion.to(device)
我们实现了计算准确率的函数…
def binary_accuracy(preds, y):
"""
Returns accuracy per batch, i.e. if you get 8/10 right, this returns 0.8, NOT 8
"""
#round predictions to the closest integer
rounded_preds = torch.round(torch.sigmoid(preds))
correct = (rounded_preds == y).float() #convert into float for division
acc = correct.sum() / len(correct)
return acc
我们定义一个函数来训练我们的模型…
注意:我们不再使用dropout,所以我们不需要使用model.train(),但正如第1本笔记本中提到的,使用它是一个很好的实践。
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad()
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
我们定义一个函数来测试我们的模型…
注意:同样,我们保留了model.eval(),即使我们不使用dropout。
def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
与之前一样,我们将实现一个有用的函数来告诉我们一个epoch需要多长时间。
import time
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
最后,我们训练我们的模型。
N_EPOCHS = 5
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut3-model.pt')
print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')
Epoch: 01 | Epoch Time: 0m 6s
Train Loss: 0.688 | Train Acc: 57.23%
Val. Loss: 0.642 | Val. Acc: 71.23%
Epoch: 02 | Epoch Time: 0m 5s
Train Loss: 0.653 | Train Acc: 71.09%
Val. Loss: 0.521 | Val. Acc: 75.28%
Epoch: 03 | Epoch Time: 0m 5s
Train Loss: 0.582 | Train Acc: 78.88%
Val. Loss: 0.449 | Val. Acc: 79.64%
Epoch: 04 | Epoch Time: 0m 5s
Train Loss: 0.505 | Train Acc: 83.15%
Val. Loss: 0.426 | Val. Acc: 82.12%
Epoch: 05 | Epoch Time: 0m 5s
Train Loss: 0.439 | Train Acc: 85.99%
Val. Loss: 0.397 | Val. Acc: 85.02%
…并得到测试的准确率!
结果与上一本笔记中的结果相当,但是训练花费的时间要少得多!
model.load_state_dict(torch.load('tut3-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
Test Loss: 0.391 | Test Acc: 85.11%
用户输入
和之前一样,我们可以测试用户提供的能确保从标记化的句子中生成bigrams的任何输入。
import spacy
nlp = spacy.load('en_core_web_sm')
def predict_sentiment(model, sentence):
model.eval()
tokenized = generate_bigrams([tok.text for tok in nlp.tokenizer(sentence)])
indexed = [TEXT.vocab.stoi[t] for t in tokenized]
tensor = torch.LongTensor(indexed).to(device)
tensor = tensor.unsqueeze(1)
prediction = torch.sigmoid(model(tensor))
return prediction.item()
一个负面评论的例子…
res = predict_sentiment(model, "This film is terrible")
print(res)
1.621993561684576e-07
一个正面评论的例子…
predict_sentiment(model, "This film is great")
print(res)
1.0
完整代码
import torch
from torchtext import data
from torchtext import datasets
def generate_bigrams(x):
n_grams = set(zip(*[x[i:] for i in range(2)]))
for n_gram in n_grams:
x.append(' '.join(n_gram))
return x
# res = generate_bigrams(['the', 'film', 'is', 'happy'])
# print(res)
SEED = 1234
torch.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
TEXT = data.Field(tokenize='spacy', tokenizer_language='en_core_web_sm', preprocessing=generate_bigrams)
LABLE = data.LabelField(dtype=torch.float)
import random
train_data, test_data = datasets.IMDB.splits(TEXT, LABLE)
train_data, valid_data = train_data.split(random_state = random.seed(SEED))
MAX_VOCAB_SIZE = 25_000
TEXT.build_vocab(
train_data,
max_size = MAX_VOCAB_SIZE,
vectors = 'glove.6B.100d',
unk_init = torch.Tensor.normal_
)
LABLE.build_vocab(train_data)
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device
)
import torch.nn as nn
import torch.nn.functional as F
class FastText(nn.Module):
def __init__(self, vocab_size, embedding_dim, output_dim, pad_idx):
super(FastText, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, pad_idx)
self.fc = nn.Linear(embedding_dim, output_dim)
def forward(self, text):
# text = [sent_len, batch_size]
embedded = self.embedding(text)
# embedded = [sent_len, batch_size, emb_dim]
embedded = embedded.permute(1, 0, 2)
# embedded = [batch_size, sent_len, emb_dim]
pooled = F.avg_pool2d(embedded, (embedded.shape[1], 1)).squeeze(1)
# pooled = [batch_size, emb_dim]
return self.fc(pooled)
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
OUTPUT_DIM = 1
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = FastText(INPUT_DIM, EMBEDDING_DIM, OUTPUT_DIM, PAD_IDX)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')
pretrained_embeddings = TEXT.vocab.vectors
model.embedding.weight.data.copy_(pretrained_embeddings)
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token]
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM)
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM)
import torch.optim as optim
optimizer = optim.Adam(model.parameters())
criterion = nn.BCEWithLogitsLoss()
model = model.to(device)
criterion = criterion.to(device)
def binary_accuracy(pred, y):
rounded_preds = torch.round(torch.sigmoid(pred))
correct = (rounded_preds == y).float()
acc = correct.sum() / len(correct)
return acc
def train(model, iterator, optimizer, criterion):
epoch_loss = 0
epoch_acc = 0
model.train()
for batch in iterator:
optimizer.zero_grad()
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval()
with torch.no_grad():
for batch in iterator:
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, batch.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
import time
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
N_EPOCHS = 5
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'tut3-model.pt')
print(f'Epoch: {epoch + 1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc * 100:.2f}%')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc * 100:.2f}%')
model.load_state_dict(torch.load('tut3-model.pt'))
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')
import spacy
nlp = spacy.load('en_core_web_sm')
def predict_sentiment(model, sentence):
model.eval()
tokenized = generate_bigrams([tok.text for tok in nlp.tokenizer(sentence)])
indexed = [TEXT.vocab.stoi[t] for t in tokenized]
tensor = torch.LongTensor(indexed).to(device)
tensor = tensor.unsqueeze(1)
prediction = torch.sigmoid(model(tensor))
return prediction.item()
res = predict_sentiment(model, "This film is terrible")
print(res)
res = predict_sentiment(model, "This film is great")
print(res)
后续行动
在下一篇笔记本,我们将使用卷积神经网络(CNNs)来进行情感分析。