fastText的组成包含三部分:模型架构、层次Softmax和N-gram特征
一、Softmax回归(Softmax Regression):
多项逻辑回归(multinomial logistic regression),是逻辑回归在处理多类别任务上的推广,用于解决多分类问题
逻辑回归中:m个被标注的样本:,其中
。由于类标是二元的,所以,
。
假设(hypothesis)如下:
代价函数(cost function)如下 类标y可取k个不同的值,类别下标从1开始:
对于训练集,
给定测试输入x,想估计x的每一种分类(j)结果出现的概率(p(y = j | x)),就要假设函数将要输出一个k维的向量(向量元素的和为1)来表示k个估计的概率值
假设函数形式如下:
注意:,是对概率分布进行归一化,使得所有概率之和为1
1{值为真的表达式} = 1
1{值为假的表达式} = 0
代价函数为:
上式是logistic回归代价函数的推广。逻辑回归是softmax回归在K=2是的特例
二、分层softmax:
要计算 y = j 时的Softmax概率:P(y = j),我们需要对所有的K个概率做归一化处理,非常耗时,
分层Softmax的基本思想:
使用树的层级结构代替扁平化的标准Softmax,使得计算P(y = j)时,只需计算一条路径上的所有节点你的概率值
示例:(树的结构是根据类标的聘书构造的霍夫曼树,K个不同的类标组成 所有的叶子节点,K-1个内部节点为内部参数,
从根节点到某个叶子节点经过的节点和边形成一条路径,路径长度被表示为L()

所以P()可被写成:

其中
![]() 表示sigmod函数;
表示sigmod函数;
LC(n) 是n节点的左孩子
[[x]] 是一个特殊的函数,被定义为: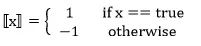
![]() 是中间节点
是中间节点 ![]() 的参数,X是Softmax层的输入
的参数,X是Softmax层的输入
上图中,高亮的节点和边是从根节点到 ![]() 的路径,路径长度
的路径,路径长度![]()
![]()
从根节点走到叶子节点![]() ,实际上是在做了3次二分类的逻辑回归,通过分层的Softmax,将计算的复杂度由|K|降到log|K|。
,实际上是在做了3次二分类的逻辑回归,通过分层的Softmax,将计算的复杂度由|K|降到log|K|。
三、 n-gram特征:
eg:
1. n-grm 字粒度:
我参与了这个项目的开发
相应的bigram特征为:我参 参与 与了 了这 这个 个项 项目 目的 的开 开发
相应的trigram特征为:我参与 参与了 与了这 了这个 这个项 个项目 项目的 目的开 的开发
2. n-gram 词粒度:
我 参与了 这个 项目的 开发
相应的bigram特征为:我/参与了 参与了/这个 这个/项目 项目的/开发
相应的trigram特征为:我/参与了/这个 参与了/这个/项目 这个/项目的/开发
为什么使用n-gram:
传统的word2vec把语料苦衷的每个单词当成原子的,会为每个单词生成一个向量,使得它忽略了单词内部的形态特征
n-gram来表示一个单词“apple”,假设n的取值为3,则它的trigram有:
"<ap" , "app" , "ppl", "ple", "le>" <表示前缀,>表示后缀,5个trigram的向量叠加起来就可以表示“apple”
优点:
1.对于低频词生成的词向量效果会更好,因为它们的n-gram可以和 其它词共享
2.对于训练词库之外的单词,仍然可以构建它们的词向量,我们可叠加她们的字符级n-gram向量
模型架构(与word2vec的CBOW模型相似,见下一节):
架构图(输入层、隐含层、输出层):

输入: 多个经向量表示的单词(多个单词及其n-gram特征,这些特征用来表示单个文档,输入特征被embedding(词嵌入)过);
输出: (采用Softmax,大大降低了模型训练时间)一个特定的target;隐含层: 对多个词向量的叠加平均
核心思想:
仔细观察模型的后半部分,即从隐含层输出到输出层输出,会发现它就是一个softmax线性多类别分类器,分类器的输入是一个用来表征当前文档的向量;模型的前半部分,即从输入层输入到隐含层输出部分,主要在做一件事情:生成用来表征文档的向量。那么它是如何做的呢?叠加构成这篇文档的所有词及n-gram的词向量,然后取平均。叠加词向量背后的思想就是传统的词袋法,即将文档看成一个由词构成的集合。
fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。
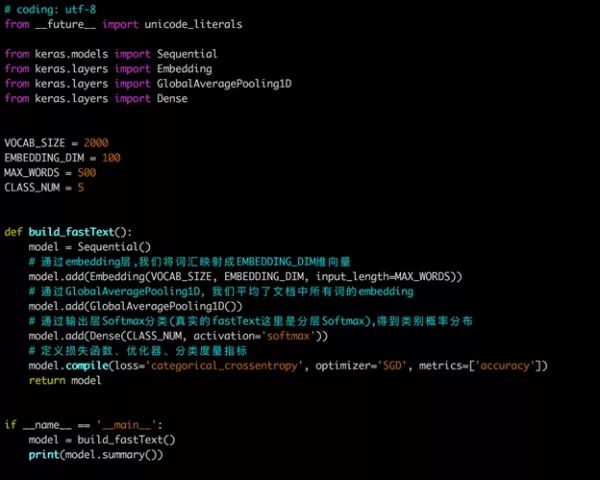
实践(生产版fastText):https://github.com/facebookresearch/fastText
demo版: