提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
本文主要是记录了学习NLP相关的笔记,如有错误,还请不吝赐教。
一、聊天机器人项目实战
1.1 走进聊天机器人
当前企业中的常见聊天机器人:
1.QA BOT(问答机器人):回答问题
(1)代表:智能客服
(2)比如:提问和回答
2.TASK BOT(任务机器人):帮助人们做事情
(1)代表:siri
(2)比如:设置明天早上9点的闹钟
3.CHAT BOT(聊天机器人):通用、开放聊天
(1)代表:微软小冰
问答机器人的常用实现手段:
1.信息检索、搜索(简单,效果一般,对数据问答对的要求高)
关键词:tfidf、SVM、朴素贝叶斯、RNN、CNN
2.知识图谱(相对复杂、效果好、很多论文)
在图形数据库中存储知识和知识见的关系,把问答转化为查询语句、能够实现推理
任务机器人的常见实现思路:
1.语音转文字
2.意图识别、领域识别、文本分类
3.槽位填充:比如买票机器人使用命令识别填充从(位置)到(位置)的票2个位置
4.回话管理、回话策略
5.自然语言生成
6.文本转语言
闲聊机器人的常见实现思路:
1.信息检索(简单、能够回答的话术有限)
2.seq2seq和变种(答案覆盖率高但不能保证答案的通顺等)
1.2 企业中的聊天机器人如何实现
1.2.1 阿里小蜜


检索模型流程:

1.3 需求分析和流程介绍

闲聊模型;

问答模型:
问答模型使用了召回和排序的机制来实现,保证获取的速度的同时保证准确率。
1.问题分析:对问题进行基础的处理,包括分词、词性的获取、词向量的获取
2.问题的召回:通过机器学习的方法进行海选,海选出大致满足要求的相似问题的前k个
3.问题的排序:通过深度学习的模型对问题计算准确率,进行排序
4.设定阈值,返回结果

整体项目流程:
a.对输入做基础处理
b.进行意图识别
c.分类之后用户是进行问答,调用问答模型,返回结果
(1)对问题进行基础的处理,包括分词、词性的获取、词向量的获取
(2)问题的召回:通过机器学习的方法进行海选,海选出大致满足要求的相似问题的前k个
(3)问题的排序:通过深度学习的模型对问题计算准确率,进行排序
(4)设定阈值,返回结果
d.分类之后是要进行闲聊,调用闲聊模型返回结果
(1)Seq2Seq这种生成模型
fasttext:
word representation(词语表示)
sentence classification (句子分类)
pysparnn:
语料准备:
1.词典
2.停用词
3.问答对
4.相似问题
分词:
在jieba中load自己的字典,然后取出停用词:
import jieba
import string
import jieba.posseg as psg
user_dict_path= '../corpus/keywords.txt'
stop_words_path='../corpus/stopwords.txt'
stop_words=[i.strip() for i in open(stop_words_path,encoding="UTF-8").readlines()]
letter=string.ascii_lowercase
jieba.load_userdict(user_dict_path)
def _cut_by_word(sentence):
"""
实现单个字返回
:param sentence:
:return:
"""
result=[]
temp = ""
for word in sentence:
if word.lower() in letter:
temp+=word
else:
if temp!="":
result.append(temp.lower())
temp=""
result.append(word.strip())
if temp!="":
result.append(temp.lower())
return result
def cut(sentence,by_word:bool=False,use_stopwords:bool=False,with_sg:bool=False):
"""
分词
:param sentence:
:param by_word: 是否按照单个字分词
:param use_stopwords: 是否使用停用词
:param with_sg: 是否返回词性
:return: 返回分词结果
"""
if by_word:
result= _cut_by_word(sente nce)
else:
result = psg.lcut(sentence)
result=[(i.word,i.flag) for i in result]
if not with_sg:
result= [i[0] for i in result]
if use_stopwords:
result=[i for i in result if i not in stop_words]
return result
if __name__=="__main__":
res=cut("Python和C++哪个难?",use_stopwords=True)
print(res)
二、fastText文本分类
2.1 文本分类的目的和方法
文本分类的目的就是要进行意图识别。
在当前的项目中,我们只有两种意图需要被识别出来,所以对应的是2分类问题。
如果当我们的聊天机器人由多个功能,那么我们需要分类的类别就有多个,即多分类问题。
常见的分类方法:
机器学习:(朴素贝叶斯,决策树)
1.特征工程:对文本进行处理,转化为能够被计算的向量来表示。我们可以考虑使用所有词语的出现次数,也可以考虑使用tfidf这种方法来处理
2.模型构建
3.训练
4.评估
补充:一些优化的方式:
- 特征工程的过程中处理的更加细致,比如文本中类似你,我,他这种词语可以把它剔除;某些词语出现的次数太少,可能并不具有代表意义;某些词语出现的次数太多,可能导致影响的程度过大等等都是我们可以考虑的地方
- 使用不同的算法进行训练,获取不同算法的结果,选择最好的,或者是使用集成学习方法
深度学习:
- 对文本进行embedding的操作,转化为向量
- 之后再通过多层的神经网络进行线性和非线性的变化得到结果
- 变换后的结果和目标值进行计算得到损失函数,比如对数似然损失等
- 通过最小化损失函数,去更新原来模型中的参数
2.2 fastText
2.2.1 fastText介绍
fastText是一个单词表示学习和文本分类的库
优点:在标准的多核CPU上, 在10分钟之内能够训练10亿词级别语料库的词向量,能够在1分钟之内给30万多类别的50多万句子进行分类。
fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。
2.2.2 fastText的基本使用
1.把数据准备为需要的格式
2.进行模型的训练、保持和加载、预测
#1. 训练
model = fastText.train_supervised("./data/text_classify.txt",wordNgrams=1,epoch=20)
#2. 保存
model.save_model("./data/ft_classify.model")
#3. 加载
model = fastText.load_model("./data/ft_classify.model")
textlist = [句子1,句子2]
#4. 预测,传入句子列表
ret = model.predict(textlist)
其中所需要的数据结构为:

以上格式是fastText要求的格式,其中chat、QA字段可以自定义,就是目标值,__label__之前的为特征值,需要使用\t进行分隔,特征值需要进行分词,__label__后面的是目标值
2.2.3 fastText语料数据的准备
import json
import logging
import jieba
import pandas
from tqdm import tqdm
from cut_sentence import cut
classifier_path="../corpus/小黄鸡未分词.conv"
by_hand_path="../corpus/手动构造的问题.json"
crawled_path="../corpus/爬虫抓取的问题.csv"
classify_corpus_path="../corpus/dataset.txt"
def keywords_in_line(line):
"""相似问题中去除关键字不在其中的句子
"""
keywords_list = ["传智播客","传智","黑马程序员","黑马","python"
"人工智能","c语言","c++","java","javaee","前端","移动开发","ui",
"ue","大数据","软件测试","php","h5","产品经理","linux","运维","go语言",
"区块链","影视制作","pmp","项目管理","新媒体","小程序","前端"]
for keyword in keywords_list:
if keyword in line:
return True
return False
def process_xiaohuangji(file):
flag=0
number=0
## todo 句子长度为1时可以考虑删去
for line in tqdm(open(classifier_path ,encoding="UTF-8").readlines(),desc="小黄鸡"):
if line.startswith("E"):
flag=0
continue
elif line.startswith("M"):
if flag==0:
flag=1
line=line[1:].strip()
else:
continue
line_cut=cut(line)
if not keywords_in_line(line_cut):
line_cut=" ".join(line_cut)+"\t"+"__label__Chat"
file.write(line_cut+"\n")
number+=1
return number
def process_byhand_data(file):
number=0
dataDict=json.loads(open(by_hand_path,encoding="utf-8").read())
for key in dataDict:
for lines in tqdm(dataDict[key]):
for line in lines:
if "校区" in line:
continue
line_cut = cut(line.strip())
line_cut = " ".join(line_cut) + "\t" + "__label__QA"
file.write(line_cut + "\n")
number+=1
return number
def process_crawled_data(file):
number=0
for line in tqdm(open(crawled_path,encoding="UTF-8").readlines(),desc="抓取的数据"):
line_cut = cut(line.strip())
line_cut = " ".join(line_cut) + "\t" + "__label__QA"
file.write(line_cut + "\n")
number+=1
return number
def process():
file_path="./text.txt"
file=open(file_path,"w",encoding="UTF-8")
number=0
number += process_xiaohuangji(file)
number+=process_byhand_data(file)
number+=process_crawled_data(file)
if __name__=="__main__":
process()
2.2.4 fastText模型的训练
fastText训练的代码示例如下:
import logging
import fastText
import pickle
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.DEBUG)
ft_model = fastText.train_supervised("./data/text_classify.txt",wordNgrams=1,epoch=20)
ft_model.save_model("./data/ft_classify.model")
其中 wordNgrams 为N-gram,即N元词组
epoch为训练迭代的次数
具体代码如下:
import fasttext
file_path="../util/text.txt"
model_path="./classifier.model"
classifier_corpus_test_path="./"
classifier_corpus_train_path="./"
def build_classifier_model():
model=fasttext.train_supervised(file_path,wordNgrams=2,epoch=20,minCount=5)
model.save_model(model_path)
def get_classfier_model():
model=fasttext.load_model(model_path)
return model
2.3.5 模型的封装
import fasttext
train_path="../corpus/data_train.txt"
test_path="../corpus/data_test.txt"
train_by_word_path="../corpus/data_by_word_test.txt"
test_by_word_path="../corpus/data_by_word_train.txt"
model_by_word_path="./classifier_by_word.model"
model_path="./classifier.model"
def build_classifier_model(by_word=False):
data_path=train_path if not by_word else train_by_word_path
model=fasttext.train_supervised(data_path,wordNgrams=2,epoch=20,minCount=1)
save_path=model_path if not by_word else model_by_word_path
model.save_model(save_path)
def get_classfier_model(by_word=False):
save_path=model_path if not by_word else model_by_word_path
model=fasttext.load_model(save_path)
return model
def eval(by_word=False):
model=get_classfier_model(by_word)
input=[]
target=[]
eval_data_path=test_path if not by_word else test_by_word_path
for line in open(eval_data_path,encoding="UTF-8").readlines():
temp=line.split("__label__")
if len(temp)<2:
continue
input.append(temp[0].strip())
target.append(temp[1].strip())
labels,acc_list=model.predict(input)
sum=0
print(len(labels),len(target))
for i ,j in zip(labels,target):
if i[0].replace("__label__","")==j:
sum+=1
acc=sum/len(labels)
return acc
import fasttext
from typing import Dict
classify_model_by_word_path="./classifier_by_word.model"
classify_model_path="./classifier.model"
class Classify:
def __init__(self):
self.model=fasttext.load_model(classify_model_path)
self.model_by_word=fasttext.load_model(classify_model_by_word_path)
def predict(self,sentence:Dict):
"""
判断输入数据的分类结果,即意图识别
:param sentence_cuted 分词之后的句子
:return: (label,acc)
"""
(label,acc)=self.model.predict(sentence["cut"])
(label_by_word,acc_by_word)=self.model_by_word.predict(sentence["cut_by_word"])
for label,acc,label_by_word,acc_by_word in zip(label,acc,label_by_word,acc_by_word):
if label=="__label__chat":
label="__label__QA"
acc=1-acc
if label_by_word=="__label__chat":
label_by_word="__label__QA"
acc_by_word=1-acc_by_word
if acc>0.95 or acc_by_word>0.95:
return ("QA",max(acc,acc_by_word))
else:
return ("Chat",max(1-acc,1-acc_by_word))
if __name__=="__main__":
model=Classify()
ret=model.predict({
"cut":"python","cut_by_word":"python"})
print(ret)
2.3.6 fastText原理分析
fastText的架构非常简单,有三层:输入层、隐含层、输出层(Hierarchical Softmax)
输入层:是对文档embedding之后的向量,包含有N-garm特征
隐藏层:是对输入数据的求和平均
输出层:是文档对应标签

1.N-gram模型:
在很多情况下,词袋模型是不满足我们的需求的。
例如:我爱她 和她爱我在词袋模型下面,概率完全相同,但是其含义确实差别非常大。
为了解决这个问题,就有了N-gram模型,它不仅考虑词频,还会考虑当前词前面的词语,比如我爱,她爱。
N-gram模型的描述是:第n个词出现与前n-1个词相关,而与其他任何词不相关。(当然在很多场景下和前n-1个词也会相关,但是为了简化问题,经常会这样去计算)
例如:I love deep learning这个句子,在n=2的情况下,可以表示为{i love},{love deep},{deep learning},n=3的情况下,可以表示为{I love deep},{love deep learning}。
在n=2的情况下,这个模型被称为Bi-garm(二元n-garm模型)
在n=3 的情况下,这个模型被称为Tri-garm(三元n-garm模型)
所以在fasttext的输入层,不仅有分词之后的词语,还有包含有N-gram的组合词语一起作为输入
补充:词袋模型:bag of word 又称为bow,称为词袋。是一种只统计词频的手段,通过词频来代替原来的词语
2.fastText中的层次化的softmax-对传统softmax的优化方法

为了提高效率,在fastText中计算分类标签的概率的时候,不再是使用传统的softmax来进行多分类的计算,而是使用的哈夫曼树(Huffman,也成为霍夫曼树),使用层次化的softmax(Hierarchial softmax)来进行概率的计算。
层次化softmax的具体分析:

上图中,红色为哈夫曼编码,即label5的哈夫曼编码为1001,那么此时如何定义条件概率 P ( L a b e l 5 ∣ c o n t e x ) P(Label5|contex) P(Label5∣contex)呢?
以Label5为例,从根节点到Label5中间经历了4次分支,每次分支都可以认为是进行了一次2分类,根据哈夫曼编码,可以把路径中的每个非叶子节点0认为是负类,1认为是正类(也可以把0认为是正类)
由机器学习课程中逻辑回归使用sigmoid函数进行2分类的过程中,一个节点被分为正类的概率是 δ ( X T θ ) = 1 1 + e − X T θ \delta(X^{T}\theta) = \frac{1}{1+e^{-X^T\theta}} δ(XTθ)=1+e−XTθ1,被分类负类的概率是: 1 − δ ( X T θ ) 1-\delta(X^T\theta) 1−δ(XTθ),其中 θ \theta θ就是图中非叶子节点对应的参数 θ \theta θ。
对于从根节点出发,到达Label5一共经历4次2分类,将每次分类结果的概率写出来就是:
- 第一次:$P(1|X,\theta_1) = \delta(X^T\theta_1) $ ,即从根节点到23节点的概率是在知道X和 θ 1 \theta_1 θ1的情况下取值为1的概率
- 第二次:$P(0|X,\theta_2) =1- \delta(X^T\theta_2) $
- 第三次:$P(0 |X,\theta_3) =1- \delta(X^T\theta_4) $
- 第四次:$P(1|X,\theta_4) = \delta(X^T\theta_4) $
但是我们需要求的是 P ( L a b e l ∣ c o n t e x ) P(Label|contex) P(Label∣contex), 他等于前4词的概率的乘积,公式如下( d j w d_j^w djw是第j个节点的哈夫曼编码)
P ( L a b e l ∣ c o n t e x t ) = ∏ j = 2 5 P ( d j ∣ X , θ j − 1 ) P(Label|context) = \prod_{j=2}^5P(d_j|X,\theta_{j-1}) P(Label∣context)=j=2∏5P(dj∣X,θj−1)
其中:
P ( d j ∣ X , θ j − 1 ) = { δ ( X T θ j − 1 ) , d j = 1 ; 1 − δ ( X T θ j − 1 ) d j = 0 ; P(d_j|X,\theta_{j-1}) = \left\{ \begin{aligned} &\delta(X^T\theta_{j-1}), & d_j=1;\\ &1-\delta(X^T\theta_{j-1}) & d_j=0; \end{aligned} \right. P(dj∣X,θj−1)={
δ(XTθj−1),1−δ(XTθj−1)dj=1;dj=0;
或者也可以写成一个整体,把目标值作为指数,之后取log之后会前置:
P ( d j ∣ X , θ j − 1 ) = [ δ ( X T θ j − 1 ) ] d j ⋅ [ 1 − δ ( X T θ j − 1 ) ] 1 − d j P(d_j|X,\theta_{j-1}) = [\delta(X^T\theta_{j-1})]^{d_j} \cdot [1-\delta(X^T\theta_{j-1})]^{1-d_j} P(dj∣X,θj−1)=[δ(XTθj−1)]dj⋅[1−δ(XTθj−1)]1−dj
在机器学习中的逻辑回归中,我们经常把二分类的损失函数(目标函数)定义为对数似然损失,即
l = − 1 M ∑ l a b e l ∈ l a b e l s l a b e l ∗ l o g P ( l a b e l ∣ c o n t e x t ) l =-\frac{1}{M} \sum_{label\in labels} label*log\ P(label|context) l=−M1label∈labels∑label∗log P(label∣context)
式子中,求和符号表示的是使用样本的过程中,每一个label对应的概率取对数后的和,之后求取均值。
带入前面对 P ( l a b e l ∣ c o n t e x t ) P(label|context) P(label∣context)的定义得到:
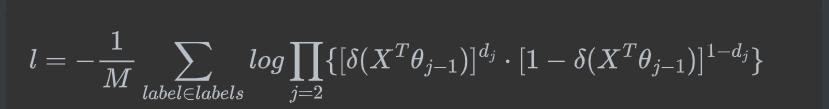
有了损失函数之后,接下来就是对其中的 X , θ X,\theta X,θ进行求导,并更新,最终还需要更新最开始的每个词语词向量
层次化softmax的好处:传统的softmax的时间复杂度为L(Labels的数量),但是使用层次化softmax之后时间复杂度的log(L) (二叉树高度和宽度的近似),从而在多分类的场景提高了效率
负采样:
即每次从除当前label外的其他label中,随机的选择几个作为负样本。
由此,最小化损失函数时就可以看做是一个二分类的问题,由此减少相应的计算量。
补充:
负采样:
从原来所有的样本中,等比例的选择neg个负样本作(遇到自己则跳过),作为训练样本,添加到训练数据中,和正例样本一起来进行训练。
使用梯度上升的方法进行梯度计算和参数更新,仅仅每次只用一波样本(一个正例和neg个反例)更新梯度,来进行迭代更新

好处:
- 提高训练速度,选择了部分数据进行计算损失,同时整个对每一个label而言都是一个二分类,损失计算更加简单,只需要让当前label的值的概率尽可能大,其他label的都为反例,概率会尽可能小
- 改进效果,增加部分负样本,能够模拟真实场景下的噪声情况,能够让模型的稳健性更强