DEMO入门示例
本次示例以训练一个能追踪小球的游戏AI。
1.新建一个Unity项目
并将之前下载的ml-agents项目UnitySDK目录下的Assets和ProjectSettings导入(复制覆盖)进新建的Unity项目
2.进入Unity项目,先编写好两个脚本
RollerAcademy 是将用于训练环境的组件:
//RollerAcademy.cs
//继承Academy用于重写训练环境,就目前而言无需改动,因此简单的直接继承即可。
using MLAgents;
public class RollerAcademy : Academy { }RollerAgent 是将用于智能体对象的组件:
//RollerAgent.cs
//继承Agent用于重写智能体的AgentReset,CollectObservations,AgentAction等方法。
using MLAgents;
using UnityEngine;
public class RollerAgent : Agent
{
Rigidbody rBody;
void Start()
{
rBody = GetComponent<Rigidbody>();
}
public Transform Target;
//Reset时调用
public override void AgentReset()
{
if (this.transform.position.y < 0)
{
//如果智能体掉下去,则重置位置+重置速度
this.rBody.angularVelocity = Vector3.zero;
this.rBody.velocity = Vector3.zero;
this.transform.position = new Vector3(0, 0.5f, 0);
}
//将目标球重生至一个新的随机位置
Target.position = new Vector3(Random.value * 8 - 4,0.5f,Random.value * 8 - 4);
}
//收集观察结果
public override void CollectObservations()
{
//------ 观测
//观测到目标球和智能体的位置
AddVectorObs(Target.position);
AddVectorObs(this.transform.position);
//观测到智能体的速度
AddVectorObs(rBody.velocity.x);
AddVectorObs(rBody.velocity.z);
//在这里因为目标球是不会动的,智能体也不会在y轴上又运动,所以没有必要观察这些值的变化。
}
public float speed = 10;
//处理动作,并根据当前动作评估奖励信号值
public override void AgentAction(float[] vectorAction, string textAction)
{
//------ 动作处理
// 接受两个动作数值
Vector3 controlSignal = Vector3.zero;
controlSignal.x = vectorAction[0];
controlSignal.z = vectorAction[1];
rBody.AddForce(controlSignal * speed);
//------ 奖励信号
float distanceToTarget = Vector3.Distance(this.transform.position,Target.position);
// 到达目标球
if (distanceToTarget < 1.42f)
{
//奖励值+1.0f
SetReward(1.0f);
Done();
}
// 掉落场景外
if (this.transform.position.y < 0)
{
Done();
}
}
}3.创建Brain决策体
创建两个Brain文件

- 打开Asset => Create => ML-Agents => LearningBrain
- 打开Asset => Create => ML-Agents => PlayerBrain
更改好名字(本文取了RollerBallBrain和RollerBallPlayer),这样就创建了两个Brain文件。
LearningBrain适用于训练模型的决策体,而PlayerBrain只是映射键盘按键的决策体(即玩家控制)。
之所以创建PlayerBrain,在训练前可让玩家通过真实操控测试当前游戏环境是否正确,然后确认无问题后再切换LearningBrain交给机器去操控(训练)。
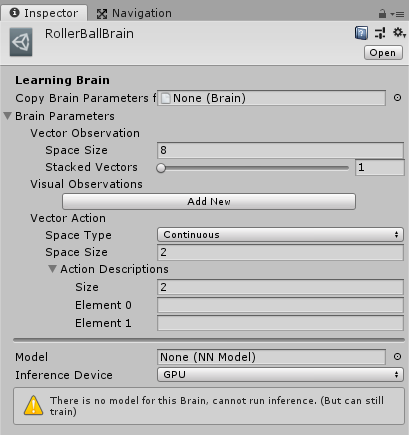
对RollerBallPlayer进行配置
从上面写的RollerAgent脚本,我们知道:
- Observation Space Size调整为8:因为总共观察 2个3D位置+2个1D速度,因此总共大小空间为8个float大小。
- Action Space Size 调整为2:因为总共动作 有2个数值
- 引入了4个按键WASD:为了让操作对2个动作值影响,所以4个按键分别对应2个动作值的正负1

对RollerBallBrain进行配置
然后我们让RollerBallBrain直接Copy Brain Parameters from刚刚配置好的RollerBallPlayer:
- 还要调整Inference Device 为GPU
4.搭建好游戏场景
创建一个地板(Plane)

创建一个小球(Target)
创建要控制的智能体(RollerAgent)
- Brain 绑定RollerBallPlayer时,是玩家可以操控它。绑定RollerBallBrain时,是机器操控它。
- Decision Interval(决策间隔)调整为10,让它的Brain做决策不要太频繁也不要太过稀疏
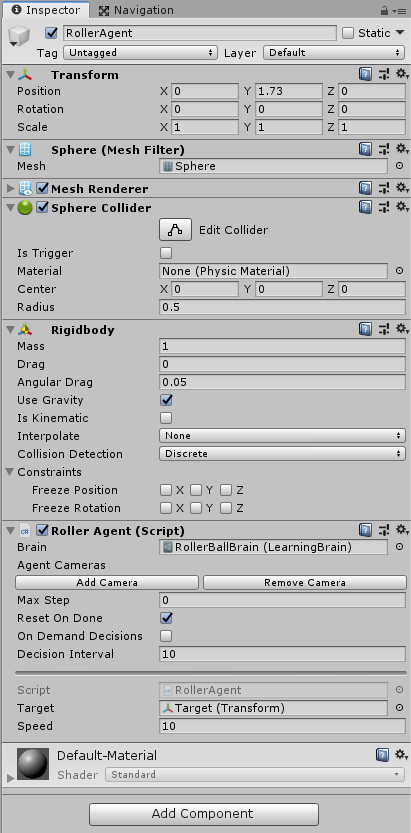
创建训练环境游戏对象(Academy)
- 在BroadcastHub绑定好那两个Brain文件
目前场景预览


- 将RollerAgent的Brain绑定RollerBallPlayer,运行Unity场景,尝试自己用WASD操控小球,测试游戏场景是否OK。
5.开始训练(挂机)
- 将RollerAgent的Brain绑定RollerBallBrain,

- 然后将Academy的BroadcastHub里RollerBallBrain的Control勾上
然后现在可以打开开始菜单,直接使用cmd命令窗口,
cd到之前下载ml-agents项目的目录里,
cd C:\Downloads\ml-agents再输入激活ml-agents环境:
activate ml-agents开启训练:
mlagents-learn config/config.yaml --run-id=RollerBall-1 --trainconfig/config.yaml是训练配置文件,RollerBall-1是你给训练出来的模型取的名字
注意config/config.yaml是不存在的,需要自己仿照于官方的示例配置文件config/trainer_config.yaml并修改配置而新建的。
下面是config.yaml示例:
default:
trainer: ppo
batch_size: 10
beta: 5.0e-3
buffer_size: 100
epsilon: 0.2
gamma: 0.99
hidden_units: 128
lambd: 0.95
learning_rate: 3.0e-4
max_steps: 3.0e5
memory_size: 256
normalize: false
num_epoch: 3
num_layers: 2
time_horizon: 64
sequence_length: 64
summary_freq: 1000
use_recurrent: false
use_curiosity: false
curiosity_strength: 0.01
curiosity_enc_size: 128
当出现如下画面:
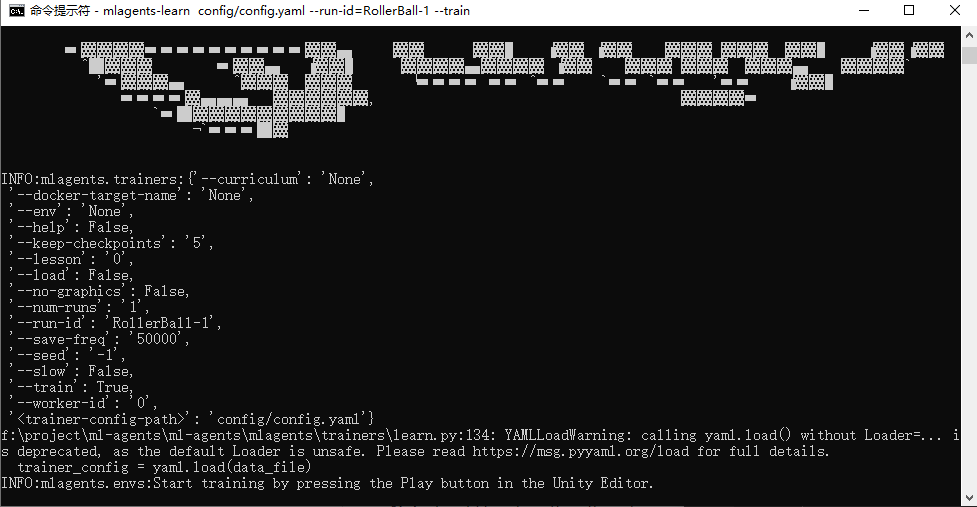
- 返还到Unity,点下运行键,那么你就会看到Unity执行训练。
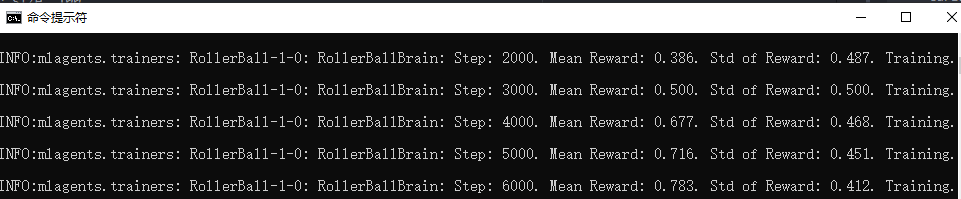
你的命令窗口也会时刻告诉你训练阶段的信息。
- 可以去睡觉等待结果了,亦或者在某个时间停止Unity运行。那么ml-agents会将目前为止训练出来的数据模型保存到ml-agents\models目录下。
6.跑训练出来的模型
- 将ml-agents\models目录下跑出来的RollerBall-1文件夹整个复制到你刚刚Unity项目里。
- Unity里,将RollerBallBrain的Model绑定上刚刚复制文件夹的NNModel。

- Unity里,将Academy的BroadcastHub的Control勾选去掉。

- 运行Unity场景,看看你跑出来的模型的蠢样了(笑)。

概念
另外一提,最新的介绍文档资料示例等都在Unity官方机器学习的github项目,感兴趣可以持续保持关注它的更新:
https://github.com/Unity-Technologies/ml-agents
Unity官方博客机器学习概念详解(1):https://blogs.unity3d.com/2017/12/11/using-machine-learning-agents-in-a-real-game-a-beginners-guide/
Unity官方博客机器学习概念详解(2):https://blogs.unity3d.com/2017/06/26/unity-ai-themed-blog-entries/
Unity ml-agents概念详解国内翻译博客:https://blog.csdn.net/u010019717/article/details/80382933
这里只做部分概念简介,懒得写太多了,以多人战争游戏中的 军医AI 为例介绍。
Agent(智能体) - 它可以被附加到一个 Unity 游戏对象上(场景中的 任何角色),负责生成它的观测结果、执行它接收的动作并适时分配奖励。在例子里,它应该附加到军医游戏对象上。
- 观测 : 军医对环境的感知。观测可以是数字和/或视觉形式。数字观测会从 Agent 的角度测量环境的属性。对于军医来说,这将是军医可以看到的战场属性。根据游戏和 agent 的不同,数字观测的数据可以是__离散__的或__连续__的形式。对于大多数有趣的环境,Agent 将需要若干连续的数字观测,而对于具有少量独特配置的简单环境,离散观测就足够了。另一方面,视觉观测是附加到 agent 的摄像头所生成的图像,代表着 agent 在该时间点看到的内容。
- 我们通常会将 agent 的观测 与环境状态混淆。环境状态表示包含所有游戏角色的整个场景的信息。但是,agent 观测仅包含它自己所了解的信息,通常是环境状态的一个子集。例如,军医观测不能包含隐身敌人的信息。
- 动作 : 军医可采取的动作。动作可以是连续的或离散的。就军医而言,如果环境是一个只是简单的网格世界, 那么采用四个方向的离散动作就足够了(即上下左右)。但是,如果环境更加复杂并且军医可以自由移动,那么使用两个连续动作(一个对应于方向, 另一个对应于速度)更合适。
- 除了上述的移动动作外,军医还应有救治动作等。
- 奖励信号 : 一个表示军医行为的标量。例如,军医在死亡时会得到很大的负奖励,每当恢复受伤的队员时会得到适度的正奖励,而在受伤队员因缺乏救助而死亡时会得到适度的负奖励。
- 奖励信号表示如何将任务的目标传达给 agent,所以采用的设置方式需要确保当获得的奖励达到最大值时,agent能够产生我们最期望的行为。
- 注意,不需要在每个时刻都提供奖励信号,只有在军医执行好的或坏的动作时才提供。
Brain(决策体) - 它封装了 Agent 的决策逻辑。实质上,Brain 中保存着每个 Agent 的 policy,决定了 Agent 在每种情况下应采取的动作。更具体地说,Agent 给其绑定的 Brain 发送 Agent的观测结果和奖励 ,然后 Brain 返回下一步的动作。
Academy(训练环境) - 它是负责指挥场景内所有 Agent 的观测和决策过程的整体训练环境。它可以指定若干环境参数,例如渲染质量和环境运行速度参数。