官方:Unity ML-Agents深度学习工具包|Unity中国官网 | Unity中国官网
Github下载链接:https://github.com/Unity-Technologies/ml-agents
ML-Agents是游戏引擎Unity3D中的一个插件,也就是说,这个软件的主业是用来开发游戏的,实际上,它也是市面上用得最多的游戏引擎之一。而在几年前随着人工智能的兴起,强化学习算法的不断改进,使得越来越多的强化学习环境被开发出来,例如总所周知的OpenAI的Gym,同时还有许多实验室都采用的星际争霸2环境来进行多智能体强化学习的研究。那么,我们自然想到,可不可以开发属于自己的强化学习环境来实现自己的算法,实际上,作为一款备受欢迎的游戏引擎,Unity3D很早就有了这么一个想法。
详情见论文:Unity: A General Platform for Intelligent Agents https://arxiv.org/abs/1809.02627
作为一个对游戏开发和强化学习都非常感兴趣的人,自然也了解到了这款插件,使得能够自己创造一个独一无二,与众不同,又充满智慧的游戏AI成为可能。
在Github的官方包中有更为详细的英文指导,如果不想翻译,也可以跟着我下面的步骤走。
文件说明
ML-Agents工具包包含几个部分:
Unity包com.unity.ml-agents包含了集成到Unity 项目中的 Unity C# SDK。,可以帮助你使用 ML-Agents 的Demo。
Unity包ml-agents.extensions依赖于com.unity.ml-agents,包含的是实验性组件,还未成为com.unity.ml-agents的一部分。
三个Python包:mlagents包含机器学习算法可以让你训练智能体,大多数ML-Agents的用户值需要直接安装这个文件。mlagents_envs包含了Python的API可以让其与Unity场景进行交互,这使得Python机器学习算法和Unity场景间的管理变得便利,mlagents依赖于mlagents_envs。gym_unity提供了Unity场景支持OpenAI Gym接口的封装。
Project文件夹包含了几个示例环境,展示了ML-Agents的几个特点,可以帮助你快速上手。
PyTorch发展势头非常迅速,Tensorflow是基于静态计算图模型(Static Computational Graph, SCG),而PyTorch基于动态图模型(Dynamic Computational Graph, DCG)。他们都有各自的优势和劣势,关于两者的对比网上有很多总结的帖子,例如这个(https://www.quora.com/Should-I-go-for-TensorFlow-or-PyTorch),这个(https://www.forbes.com/sites/quora/2017/07/10/is-pytorch-better-than-tensorflow/#1dd3199173b7)。两者都是很成功的深度学习框架,拥有很多用户。具体如何选择,还要根据自己的需求来决定。在Unity Ml-Agent这里,目前也只能选择Tensorflow......
不知道什么时候Unity官方能支持PyTorch。但仔细想想,难度应该很大。首先,Tensorflow更加成熟,生态系统发展更加完善。像WebGL上用的Tensorflow.js(https://js.tensorflow.org/),移动设备上用的tensorflow lite(https://www.tensorflow.org/mobile/tflite/),有强大的google在背后做支撑,产品线一应俱全。PyTorch还在发展过程中,这些东西几乎没有。其次,但是非常重要的一点是,Unity一直使用CSharp作为首要开发语言(以前的Unity Script已被抛弃),TensorflowSharp(https://github.com/migueldeicaza/TensorFlowSharp)正好提供了这样一个中间层, 对TensorFlow C API 进行.NET封装,使得在Unity中使用Tensorflow变成了现实。而PyTroch呢?是从Lua(虽然游戏界比较常用,但总体来说非常小众的脚本语言)移植过来的,是完全面向Python的语言,想与CSharp结合?除非有人专门去做,目前来看,这个需求实在是小众。
尽管如此,并不是说完全不能使用PyTorch来训练模型,通过曲线救国的方法,目前或许可以尝试一下下面几个思路:
1)使用PyTorch训练模型,使用开源的模型转换器,把训练好的模型转成Tensorflow的格式,这个github(https://github.com/ysh329/deep-learning-model-convertor)中集合了现有的一些主流的深度学习框架模型转换器,值得尝试。
2) 使用ONNX(Open Neural Network Exchange)。ONNX(https://onnx.ai/)是一个深度学习模型开放格式,它相当于制定了一个标准格式,让各个框架训练出来的模型具备互操作能力。开发者使用它可以非常轻松的在深度学习框架、工具之间来回切换,能有效提高训练结果的复用能力。PyTorch 1.0 版本也有望支持更多的平台(https://www.forbes.com/sites/janakirammsv/2018/05/04/facebook-announces-pytorch-1-0-and-expanded-onnx-ecosystem/#4b4bfb843fc0)。
纯属这么一说,我没有做任何实验。;)
看到这里很容易,但要做到这里肯定需要花费不少时间,“时间是世界上一切成就的土壤”,相信付出就会有收获。
0. 预备知识
虽然名字叫做机器学习ML,但是主要内容还是增强学习RL(或者叫强化学习)。其实并没有错,ML中主要包括监督学习、非监督学习和增强学习三种范式,只是这里并没有监督学习和非监督学习的内容。
这还是要从强化学习说起,但是为了避免篇幅太长,这里不做介绍了。网上有很多的学习资料,可以自行补课。Richard S. Sutton and Andrew G. Barto 的书 Reinforcement Learning: An Introduction 可以说是该领域的圣经。这里有第二版的pdf(http://incompleteideas.net/book/the-book-2nd.html)。
视频推荐大神David Silver的课程(https://www.bilibili.com/video/av8912293),他的重点在于传统的增强学习原理。另外一个课程是UC Berkeley的深度增强学习课程(https://www.bilibili.com/video/av20957290),该讲师被评为“MIT Tech Review Top 35 Innovators Under 35 (TR35), 2016”,结合最新的深度学习讲增强学习算法,很赞!
当然,既然是Unity的ml-agent,还必须知道Unity到底怎么玩。玩Unity需要使用C#语言,玩深度学习需要使用Python语言。
嗯。。。要学的东西很多啊,是时候继续了!
1. 直观感受Hello World
官方给出3D平衡小球的示例做出Hello World示例。这个hello world可不简单,第一次做还是需要比较多的时间。但是没有办法,这本来就是多个学科、多个领域的交叉,当你一步一步做下来并看到最终结果的时候,才能体会到作为一名程序员的成就感。所以不要犹豫,官方文档讲解清晰明了,如果具备了Unity、增强学习、python、TensorFlow的一点基础知识,那就赶快开始吧。毕竟这里还不需要自己去写代码。直观感受一下能激发你的求知欲和好奇心。下面上个截图:

3DBalanceBall
稍作讲解,小球在倾斜的地板上会往下滑,最终坠落。该地板就是训练出来智能体(Agent),它通过改变自己的倾斜角度,使得小球在3D空间中保持平衡。
2. 从头动手
2.1 环境构建
参考这里(https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Learning-Environment-Create-New.md),不再赘述。
2.2 训练
参考这里(https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Training-ML-Agents.md),不再赘述。
有几点事情要注意:
- 得不到收敛的策略。默认的训练次数是max_steps: 5.0e4,是在trainer_config.yaml这个文件中设定的。这个次数我在训练的时候得不到收敛的policy,因此需要加大一些;还有一种方案,就是学习3DBall 的那种方式,在场景中复制多份的环境,并行训练。
- tensorboard 打开之后不显示内容。好几次都遇到这个问题,参考这里(https://stackoverflow.com/questions/44175037/cant-open-tensorboard-0-0-0-06006-or-localhost6006)的解决方法就是:执行命令的时候指定host的IP地址,类似以下命令:
tensorboard --logdir=training:your_log_dir --host=127.0.0.1
然后访问http://127.0.0.1:6006即可。 - 只有在所有的steps都跑完之后,才会生成bytes文件,如果按下ctrl+c强行停止,不会生成。
2.3 Play
把训练完成得到的bytes文件拷贝到Unity的工程中,这里需要修改Brain类型为Internal,然后指定Graph Model文件。点击Play,即可看到训练的效果。我设定了训练step是2.0e5,使用TensorFlow GPU版本,GTX 1060 3GB的显卡,训练时间也很短,RollerBall就能妥妥的找到Target!

RollerBall
3. 原理
3.1 与OpenAI Gym的对比
这里不再解释增强学习的概念,网上有太多的资料可用,比我讲解强多了。这里想和OpenAI Gym做一个对比。再使用Gym做增强学习时主要的代码框架是这样的:
env = gym.make('CartPole-v0')
env.reset()
while True:
env.render()
state, reward, done, _ = env.step(env.action_space.sample()) # take a random action
if done:
break
env.close()
Gym已经做好了很多个环境供我们调用,只需要关注自己的增强学习算法即可(当然,也可以进行扩展,实现自己的env)。但是再Unity中并没有这么便利的工具,我想这也是ml-agents这个项目的出发点之一。Gym毕竟只是一个算法实验平台,并不能直接用于游戏开发或者生产实践。
从上面一段代码可以看出,制作环境需要重点实现的几个关键函数:
- 环境需要初始化和关闭,如make函数、close函数
- 增强学习需要多次反复的训练,环境需要重置自身状态,如reset函数
- 环境需要定义自身的状态空间和动作空间,如action_space,observation_space
- 环境需要一步一步的执行,并返回该步执行后环境的状态、回报、结束标记等,如step函数
3.2 整体架构
对于制作环境来讲,Unity肯定具有天然的优势,而且是三维的。但是困难又来了,目前的深度学习框架大多数是基于Python语言,Unity基于C#语言开发,环境和智能体怎么结合起来呢?该项目给了我们答案。下面这幅图是我根据自己对源码的理解画出来,非官方。

Unity ML-Agents整体架构
该项目在训练阶段使用了Socket进行进程间的通信,Python端做Socket Server,Unity Environment(C#实现)来做Socket Client。TensorFlow训练的模型保存为自己的格式(就是训练完成之后生成的bytes文件)。在Inference阶段,使用TensorFlowSharp来读取训练好的模型,用于在Unity Environment中的Brain,来具体指导Agent与环境交互。
3.2 关键部件
还是有必要介绍一下该项目中各个主要的部件,及其相互之间的关系。本部分主要参考自这个页面(https://github.com/Unity-Technologies/ml-agents/blob/master/docs/localized/zh-CN/docs/ML-Agents-Overview.md)。该项目目前的中文文档质量一般,数量也不多,所以还是重点阅读研究英文文档。
ML-Agents 是一个 Unity 插件,它包含三个高级组件:
-
学习环境(Learning Environment) - 其中包含Unity场景和所有游戏角色。
-
Python API - 其中包含用于训练(学习某个行为或 policy)的所有机器学习算法。请注意, 与学习环境不同,Python API不是Unity的一部分,而是位于外部并通过External Communicator与Unity进行通信。
-
External Communicator - 它将Unity环境与Python API连接起来。它位于Unity环境中。

 编辑ML-Agents 的简化框图
编辑ML-Agents 的简化框图
Learning Environment包含三个附加组件,它们可帮助组织Unity场景。
-
Agent - 它可以被附加到一个Unity GameObject上(可以是场景中的任何角色),负责生成它的观测结果、执行它接收的动作 并适时分配奖励(正/负)。每个Agent只与一个Brain相关联。这里可以把Agent理解成一个“傀儡”,它是环境与大脑之间的中间层,负责观察环境的状态、并执行大脑的意图。
-
Brain - 它封装了Agent的决策逻辑。实质上,Brain中保存着每个Agent的policy,决定了Agent 在每种情况下应采取的动作。更具体地说,它是从Agent接收观测结果和奖励并返回动作的组件。
-
Academy - 它指挥agent的观测和决策过程。在Academy内,可以指定若干环境参数,例如渲染质量和环境运行速度参数。External Communicator位于Academy内。从代码来看,Academy的实现其实就类似与Gym中ENV。
每个学习环境都会有一个全局的Academy,与每一个游戏角色一一对应的多个Agent。虽然每个Agent必须与一个Brain相连,但具有相似观测和动作的多个Agent可关联到同一个Brain。举例来说,在示例游戏中,我们有两个各自拥有自己军医的军队。因此,在我们的学习环境中将有两个Agent, 每名军医对应一个Agent,但这两个军医都可以关联到同一个Brain。请注意,这两个军医与同一个Brain相连的原因是,他们的观测和动作空间是相似的。这并不意味着在每种情况下,他们都会有相同的观测和动作值。换句话说,Brain定义了所有可能的观测和动作的空间,而与之相连的Agent(在本示例中是指军医)可以各自拥有自己独特的观测和动作值。如果我们将游戏扩展到包含坦克驾驶员NPC,那么附加到这些角色的Agent不能与连接到军医的Agent共享一个Brain(军医和驾驶员有不同的动作)。
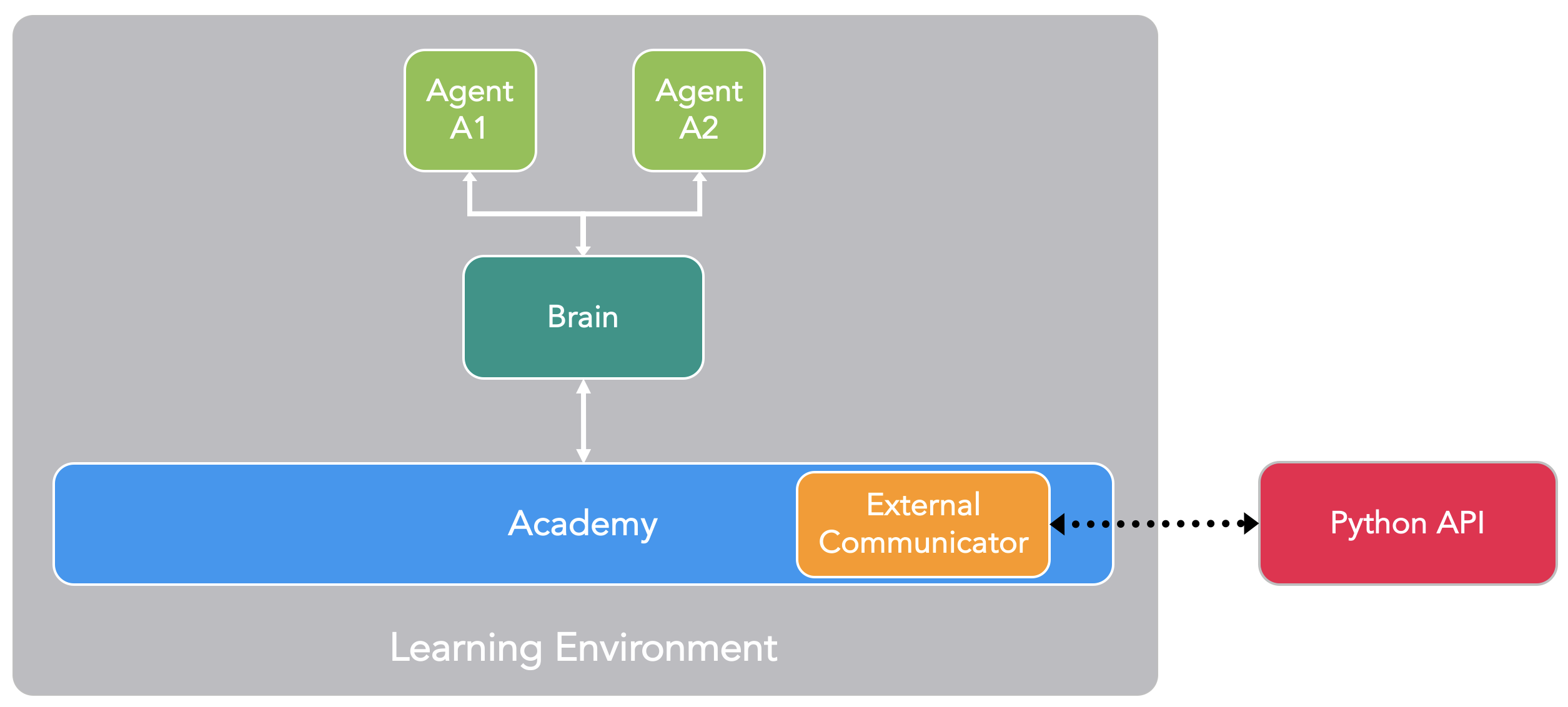
ML-Agents 的示例框图
我们尚未讨论ML-Agents如何训练行为以及Python API和External Communicator的作用。在我们深入了解这些细节之前,让我们总结一下先前的组件。每个游戏角色上附有一个Agent,而每个Agent都连接到一个Brain。Brain从Agent处接收观测结果和奖励并返回动作。Academy除了能够控制环境参数之外,还可确保所有Agent和Brain都处于同步状态。那么,Brain如何控制Agent的动作呢?
实际上,我们有四种不同类型的Brain,它们可以实现广泛的训练和预测情形:
-
External - 使用Python API进行决策。这种情况下,Brain收集的观测结果和奖励通过External Communicator转发给Python API。Python API随后返回 Agent 需要采取的相应动作。
-
Internal - 使用TensorFlow训练的模型进行决策。TensorFlow训练的模型包含了学到的policy,Brain直接使用 此模型来确定每个 Agent 的动作。
-
Player - 使用键盘或控制器的实际输入进行决策。这种情况下,人类玩家负责控制Agent,由Brain 收集的观测结果和奖励不用于控制Agent。
-
Heuristic - 使用写死(硬编码 hard-coded)的逻辑行为进行决策,目前市面上大多数游戏角色行为都是这么定义的。这种类型有助于调试具有硬编码逻辑行为的Agent。也有助于把这种由硬编码逻辑指挥的Agent与训练好的Agent 进行比较。在我们的示例中,一旦我们为军医训练了Brain,我们便可以为一个军队的军医分配经过训练的 Brain,而为另一个军队的军医分配具有写死逻辑行为的Heuristic Brain。然后,我们可以评估哪个军医的效率更高。
根据目前所述,External Communicator 和 Python API 似乎 只能由 External Brain 所用。实际并非如此。 我们可以配置 Internal、Player 和 Heuristic 类型的 Brain, 使它们也能通过 External Communicator(一种称为 broadcasting 的功能) 将观测结果、奖励和动作发送给 Python API。我们很快就会 看到,这样可以实现其他的训练模式。
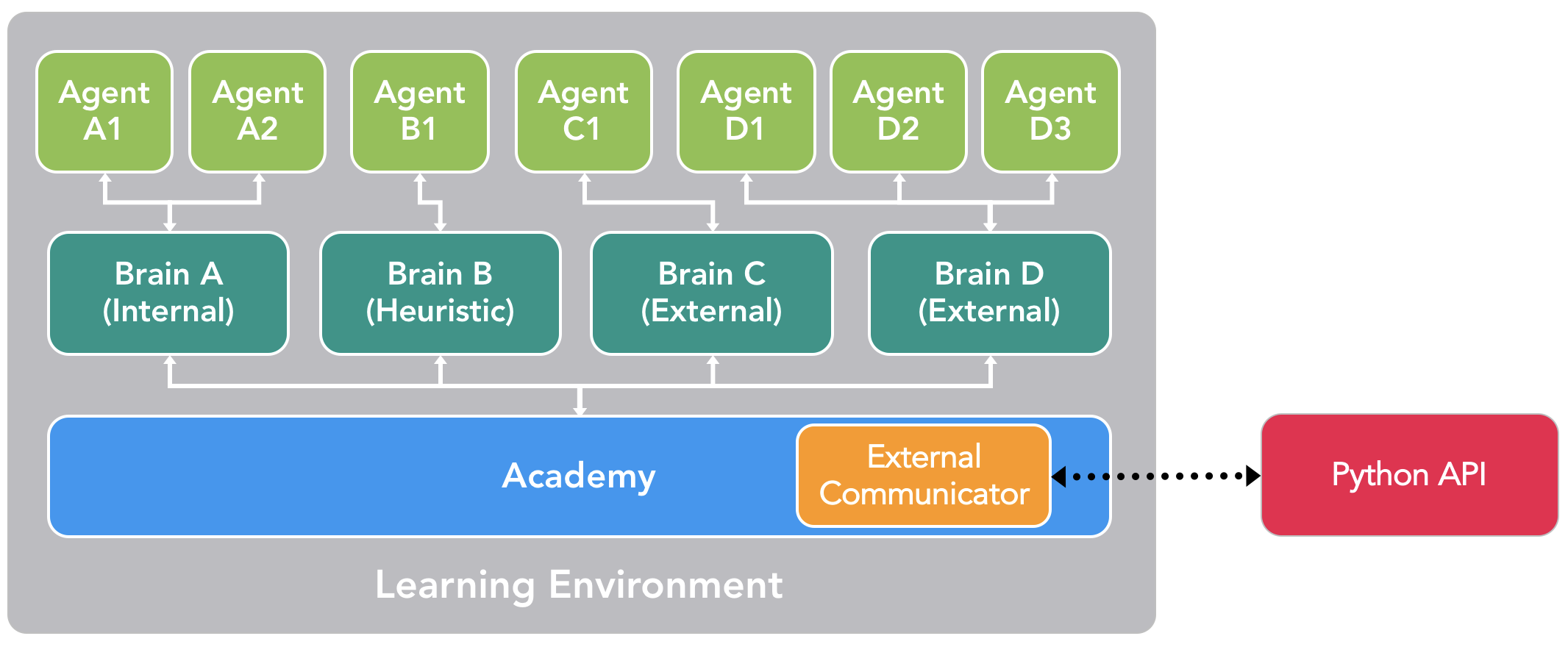
包含多个Agent和Brain的场景配置示例
链接:https://www.jianshu.com/p/31844f586b04/
https://blog.csdn.net/tianjuewudi/article/details/121115480