目标网站

准备爬取内容

创建scrapy项目,生成爬虫文件

分析html标签

抓取内容

自定义存储方式
修改pipelines.py,使数据自动存成json格式

在setting文件中加入刚刚写好的管道
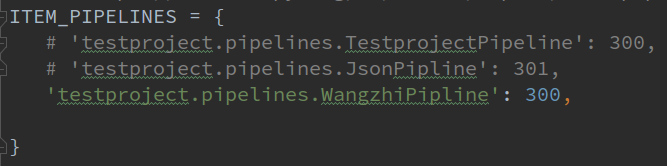
运行一下爬虫

项目目录下新增了一个文件
文件内容

python 爬虫 scrapy 爬取搜狗网址导航
猜你喜欢
转载自blog.csdn.net/weixin_43751840/article/details/88556702
今日推荐
周排行