1.算法简介
AP(Affinity Propagation)通常被翻译为近邻传播算法或者亲和力传播算法,是在2007年的Science杂志上提出的一种新的聚类算法。AP算法的基本思想是将全部数据点都当作潜在的聚类中心(称之为exemplar),然后数据点两两之间连线构成一个网络(相似度矩阵),再通过网络中各条边的消息(responsibility和availability)传递计算出各样本的聚类中心。
2.相关概念(假如有数据点i和数据点j)
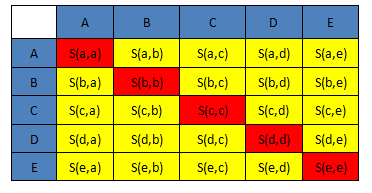

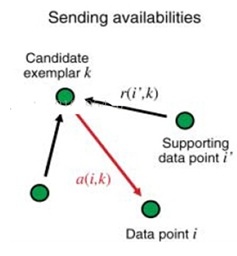
(图1) (图2) (图3)
1)相似度: 点j作为点i的聚类中心的能力,记为S(i,j)。一般使用负的欧式距离,所以S(i,j)越大,表示两个点距离越近,相似度也就越高。使用负的欧式距离,相似度是对称的,如果采用其他算法,相似度可能就不是对称的。
2)相似度矩阵:N个点之间两两计算相似度,这些相似度就组成了相似度矩阵。如图1所示的黄色区域,就是一个5*5的相似度矩阵(N=5)
3) preference:指点i作为聚类中心的参考度(不能为0),取值为S对角线的值(图1红色标注部分),此值越大,最为聚类中心的可能性就越大。但是对角线的值为0,所以需要重新设置对角线的值,既可以根据实际情况设置不同的值,也可以设置成同一值。一般设置为S相似度值的中值。(有的说设置成S的最小值产生的聚类最少,但是在下面的算法中设置成中值产生的聚类是最少的)
4)Responsibility(吸引度):指点k适合作为数据点i的聚类中心的程度,记为r(i,k)。如图2红色箭头所示,表示点i给点k发送信息,是一个点i选点k的过程。
5)Availability(归属度):指点i选择点k作为其聚类中心的适合程度,记为a(i,k)。如图3红色箭头所示,表示点k给点i发送信息,是一个点k选diani的过程。
6)exemplar:指的是聚类中心。
7)r (i, k)加a (i, k)越大,则k点作为聚类中心的可能性就越大,并且i点隶属于以k点为聚类中心的聚类的可能性也越大
3.数学公式
1)吸引度迭代公式:
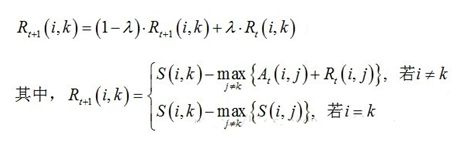 (公式一)
(公式一)
说明1:Rt+1(i,k)表示新的R(i,k),Rt(i,k)表示旧的R(i,k),也许这样说更容易理解。其中λ是阻尼系数,取值[0.5,1),用于算法的收敛
说明2:网上还有另外一种数学公式:
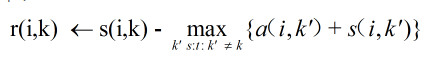 (公式二)
(公式二)
sklearn官网的公式是:
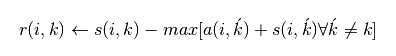 (公式三)
(公式三)
我试了这两种公式之后,发现还是公式一的聚类效果最好。同样的数据都采取S的中值作为参考度,我自己写的算法聚类中心是5个,sklearn提供的算法聚类中心是十三个,但是如果把参考度设置为p=-50,则我自己写的算法聚类中心很多,sklearn提供的聚类算法产生标准的3个聚类中心(因为数据是围绕三个中心点产生的),目前还不清楚这个p=-50是怎么得到的。
2)归属度迭代公式
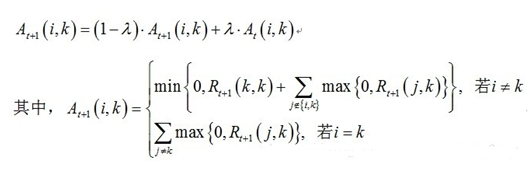
说明:At+1(i,k)表示新的A(i,k),At(i,k)表示旧的A(i,k)。其中λ是阻尼系数,取值[0.5,1),用于算法的收敛
4.算法流程
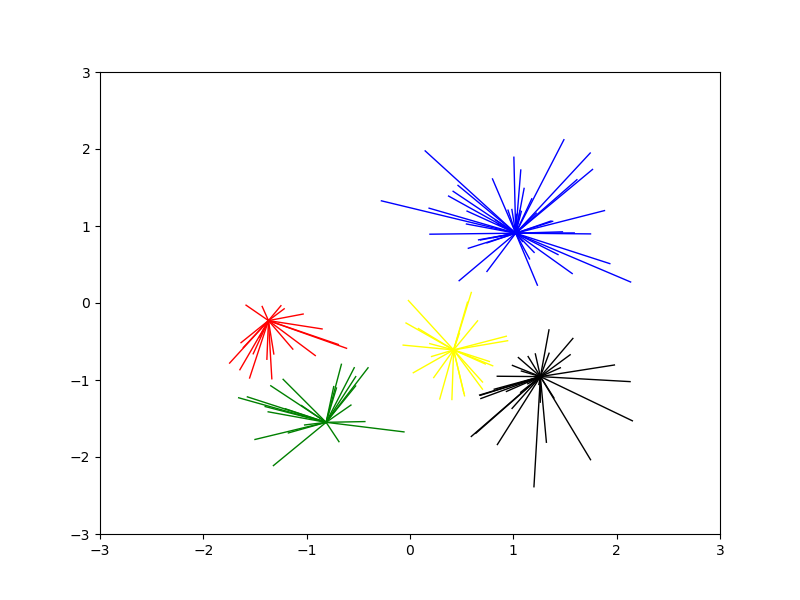
1)设置实验数据。使用sklearn包中提供的函数,随机生成以[1, 1], [-1, -1], [1, -1]三个点为中心的150个数据。
def init_sample():
"""
第一步:生成测试数据
1.生成实际中心为centers的测试样本300个,
2.Xn是包含150个(x,y)点的二维数组
3.labels_true为其对应的真是类别标签
"""
# 生成的测试数据的中心点
centers = [[1, 1], [-1, -1], [1, -1]]
# 生成数据
X, label_true = make_blobs(n_samples=150, centers=centers, cluster_std=0.5, random_state=0)
return X, label_true
2)计算相似度矩阵,并且设置参考度,这里使用相似度矩阵的中值
3)计算吸引度矩阵,即R值。
4)计算归属度矩阵,即A值
5)迭代更新R值和A值。终止条件是聚类中心在一定程度上不再更新或者达到最大迭代次数
6)根据求出的聚类中心,对数据进行分类
这个步骤产生的是一个归类列表,列表中的每个数字对应着样本数据中对应位置的数据的分类
完整代码


# -*- coding: utf-8 -*- """ @Datetime: 2019/3/31 @Author: Zhang Yafei """ import matplotlib.pyplot as plt import numpy as np from sklearn.datasets.samples_generator import make_blobs def init_sample(): """ 第一步:生成测试数据 1.生成实际中心为centers的测试样本300个, 2.Xn是包含150个(x,y)点的二维数组 3.labels_true为其对应的真是类别标签 """ # 生成的测试数据的中心点 centers = [[1, 1], [-1, -1], [1, -1]] # 生成数据 X, label_true = make_blobs(n_samples=150, centers=centers, cluster_std=0.5, random_state=0) return X, label_true class AP(object): """ AP聚类 """ def __init__(self): self.Xn = None self.Xn_len = None self.R = None self.A = None self.simi_matrix = None self.class_cen = None def fit(self, data): self.Xn = data self.Xn_len = len(data) # 初始化R、A矩阵 self.R = np.zeros((self.Xn_len, self.Xn_len)) self.A = np.zeros((self.Xn_len, self.Xn_len)) # 计算相似度 self.cal_simi() # 输出聚类中心 self.class_cen = self.cal_cls_center() def cal_simi(self): """ 计算相似度矩阵 这个数据集的相似度矩阵,最终是二维数组 每个数字与所有数字的相似度列表,即矩阵中的一行 采用负的欧式距离计算相似度 :return: """ simi = [[-np.sqrt((m[0] - n[0]) ** 2 + (m[1] - n[1]) ** 2) for n in self.Xn] for m in self.Xn] # 设置参考度,即对角线的值,一般为最小值或者中值 # p = np.min(simi) ##11个中心 # p = np.max(simi) ##14个中心 p = np.median(simi) ##5个中心 for i in range(self.Xn_len): simi[i][i] = p self.simi_matrix = simi def iter_update_R(self, old_r=0, lam=0.5): """ 计算吸引度矩阵,即R 公式1:r(n+1) =s(n)-(s(n)+a(n))-->简化写法,具体参见上图公式 公式2:r(n+1)=(1-λ)*r(n+1)+λ*r(n) 迭代更新R矩阵 :param old_r: 更新前的某个r值 :param lam: 阻尼系数,用于算法收敛 :return: """ # 此循环更新R矩阵 for i in range(self.Xn_len): for k in range(self.Xn_len): old_r = self.R[i][k] if i != k: max1 = self.A[i][0] + self.R[i][0] ##注意初始值的设置 for j in range(self.Xn_len): if j != k: if self.A[i][j] + self.R[i][j] > max1: max1 = self.A[i][j] + self.R[i][j] ##更新后的R[i][k]值 self.R[i][k] = self.simi_matrix[i][k] - max1 ##带入阻尼系数重新更新 self.R[i][k] = (1 - lam) * self.R[i][k] + lam * old_r else: max2 = self.simi_matrix[i][0] ##注意初始值的设置 for j in range(self.Xn_len): if j != k: if self.simi_matrix[i][j] > max2: max2 = self.simi_matrix[i][j] ##更新后的R[i][k]值 self.R[i][k] = self.simi_matrix[i][k] - max2 ##带入阻尼系数重新更新 self.R[i][k] = (1 - lam) * self.R[i][k] + lam * old_r print("max_r:" + str(np.max(self.R))) def iter_update_A(self, old_a=0, lam=0.5): """ 迭代更新A矩阵 :param old_r: 更新前的某个r值 :param lam: 阻尼系数,用于算法收敛 :return: """ old_a = 0 ##更新前的某个a值 lam = 0.5 ##阻尼系数,用于算法收敛 ##此循环更新A矩阵 for i in range(self.Xn_len): for k in range(self.Xn_len): old_a = self.A[i][k] if i == k: max3 = self.R[0][k] ##注意初始值的设置 for j in range(self.Xn_len): if j != k: if self.R[j][k] > 0: max3 += self.R[j][k] else: max3 += 0 self.A[i][k] = max3 # 带入阻尼系数更新A值 self.A[i][k] = (1 - lam) * self.A[i][k] + lam * old_a else: max4 = self.R[0][k] # 注意初始值的设置 for j in range(self.Xn_len): # 上图公式中的i!=k 的求和部分 if j != k and j != i: if self.R[j][k] > 0: max4 += self.R[j][k] else: max4 += 0 # 上图公式中的min部分 if self.R[k][k] + max4 > 0: self.A[i][k] = 0 else: self.A[i][k] = self.R[k][k] + max4 # 带入阻尼系数更新A值 self.A[i][k] = (1 - lam) * self.A[i][k] + lam * old_a print("max_a:" + str(np.max(self.A))) def cal_cls_center(self, max_iter=100, curr_iter=0, max_comp=30, curr_comp=0): """ 计算聚类中心 进行聚类,不断迭代直到预设的迭代次数或者判断comp_cnt次后聚类中心不再变化 :param max_iter: 最大迭代次数 :param curr_iter: 当前迭代次数 :param max_comp: 最大比较次数 :param curr_comp: 当前比较次数 :return: """ class_cen = [] # 聚类中心列表,存储的是数据点在Xn中的索引 while True: # 计算R矩阵 self.iter_update_R() # 计算A矩阵 self.iter_update_A() # 开始计算聚类中心 for k in range(self.Xn_len): if self.R[k][k] + self.A[k][k] > 0: if k not in class_cen: class_cen.append(k) else: curr_comp += 1 curr_iter += 1 print('iteration the {}'.format(curr_iter)) if curr_iter >= max_iter or curr_comp > max_comp: break return class_cen def c_list(self): # 根据聚类中心划分数据 c_list = [] for m in self.Xn: temp = [] for j in self.class_cen: n = Xn[j] d = -np.sqrt((m[0] - n[0]) ** 2 + (m[1] - n[1]) ** 2) temp.append(d) # 按照是第几个数字作为聚类中心进行分类标识 c = class_cen[temp.index(np.max(temp))] c_list.append(c) print(c_list) return c_list def plot(class_cen, X, c_list): # 画图 colors = ['red', 'blue', 'black', 'green', 'yellow'] plt.figure(figsize=(8, 6)) plt.xlim([-3, 3]) plt.ylim([-3, 3]) for i in range(len(X)): d1 = Xn[i] d2 = Xn[c_list[i]] c = class_cen.index(c_list[i]) plt.plot([d2[0], d1[0]], [d2[1], d1[1]], color=colors[c], linewidth=1) # if i == c_list[i] : # plt.scatter(d1[0],d1[1],color=colors[c],linewidth=3) # else : # plt.scatter(d1[0],d1[1],color=colors[c],linewidth=1) plt.savefig('AP 聚类.png') plt.show() if __name__ == '__main__': # 初始化数据 Xn, labels_true = init_sample() ap = AP() ap.fit(data=Xn) class_cen = ap.class_cen # for i in class_cen: # print(str(i)+":"+str(Xn[i])) c_list = ap.c_list() plot(class_cen=class_cen, X=Xn, c_list=c_list)
效果图
5.sklearn包中的AP算法
1)函数:sklearn.cluster.AffinityPropagation
2)主要参数:
damping : 阻尼系数,取值[0.5,1)
convergence_iter :比较多少次聚类中心不变之后停止迭代,默认15
max_iter :最大迭代次数
preference :参考度
3)主要属性
cluster_centers_indices_ : 存放聚类中心的数组
labels_ :存放每个点的分类的数组
n_iter_ : 迭代次数
4)示例
preference(即p值)取不同值时的聚类中心的数目在代码中注明了。
# -*- coding: utf-8 -*- """ @Datetime: 2019/3/31 @Author: Zhang Yafei """ import numpy as np from sklearn.cluster import AffinityPropagation from sklearn.datasets.samples_generator import make_blobs def init_sample(): """ 第一步:生成测试数据 1.生成实际中心为centers的测试样本300个, 2.Xn是包含150个(x,y)点的二维数组 3.labels_true为其对应的真是类别标签 """ # 生成的测试数据的中心点 centers = [[1, 1], [-1, -1], [1, -1]] # 生成数据 X, label_true = make_blobs(n_samples=150, centers=centers, cluster_std=0.5, random_state=0) return X, label_true def simi_matrix(Xn): simi = [] for m in Xn: ##每个数字与所有数字的相似度列表,即矩阵中的一行 temp = [] for n in Xn: ##采用负的欧式距离计算相似度 s =-np.sqrt((m[0]-n[0])**2 + (m[1]-n[1])**2) temp.append(s) simi.append(temp) return simi if __name__ == '__main__': Xn, label_true = init_sample() simi_matrix = simi_matrix(Xn) p = -50 ##3个中心 #p = np.min(simi) ##9个中心, #p = np.median(simi) ##13个中心 ap = AffinityPropagation(damping=0.5, max_iter=500, convergence_iter=30, preference=p).fit(Xn) cluster_centers_indices = ap.cluster_centers_indices_ print(ap.labels_) for idx in cluster_centers_indices: print(Xn[idx]
6.AP算法的优点
1) 不需要制定最终聚类族的个数
2) 已有的数据点作为最终的聚类中心,而不是新生成一个族中心。
3)模型对数据的初始值不敏感。
4)对初始相似度矩阵数据的对称性没有要求。
5).相比与k-centers聚类方法,其结果的平方差误差较小。
7.AP算法的不足
1)AP算法需要事先计算每对数据对象之间的相似度,如果数据对象太多的话,内存放不下,若存在数据库,频繁访问数据库也需要时间。
2)AP算法的时间复杂度较高,一次迭代大概O(N3)
3)聚类的好坏受到参考度和阻尼系数的影响。