Python实现简单的KNN聚类算法
完整代码
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 鸢尾花
iris=load_iris()
df = pd.DataFrame(data=iris.data,columns=iris.feature_names)
df["class"]=iris.target
df["class"]=df["class"].map({0:iris.target_names[0], 1:iris.target_names[1], 2:iris.target_names[2]})
# 解析数据
x=iris.data
y=iris.target.reshape(-1,1)
# 划分训练集和测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=35,stratify=y)
# 距离函数定义 欧式距离
def l1_distance(a, b):
return np.sum(np.abs(a-b),axis=1)
# 距离函数定义 曼哈顿距离
def l2_distance(a, b):
return np.sqrt(np.sum((a-b)**2,axis=1))
# 分类器
class KNN(object):
def __init__(self,n_neighbors=1,dist_func=l1_distance):
self.n_neighbors =n_neighbors
self.dist_func = dist_func
# 模型训练
def fit(self,x,y):
self.x_train =x
self.y_train =y
# 模型预测
def predict(self,x):
y_pred=np.zeros((x.shape[0],1),dtype=self.y_train.dtype)
for i,x_test in enumerate(x):
# 计算距离
distance=self.dist_func(self.x_train,x_test)
# 距离排序
nn_index = np.argsort(distance)
nn_y = self.y_train[nn_index[:self.n_neighbors]].ravel()
y_pred[i] = np.argmax(np.bincount(nn_y))
return y_pred
# knn=KNN(n_neighbors=3)
# # 训练
# knn.fit(x_train,y_train)
# # 预测
# y_pred=knn.predict(x_test)
# # 准确率
# accuracy=accuracy_score(y_test,y_pred)
# print("准确率:",accuracy)
knn=KNN()
# 返回结果
result_list=[]
# 训练
knn.fit(x_train,y_train)
# 分别计算欧式距离和曼哈顿距离
for p in [1,2]:
knn.dist_func=l1_distance if p==1 else l2_distance
# k取奇数 步长为2 计算不同k值下的准确率
for k in range(1,10,2):
knn.n_neighbors=k
# 预测结果
y_pred = knn.predict(x_test)
# 准确率
accuracy=accuracy_score(y_test,y_pred)
result_list.append([k, "欧式" if p==1 else "曼哈顿",accuracy])
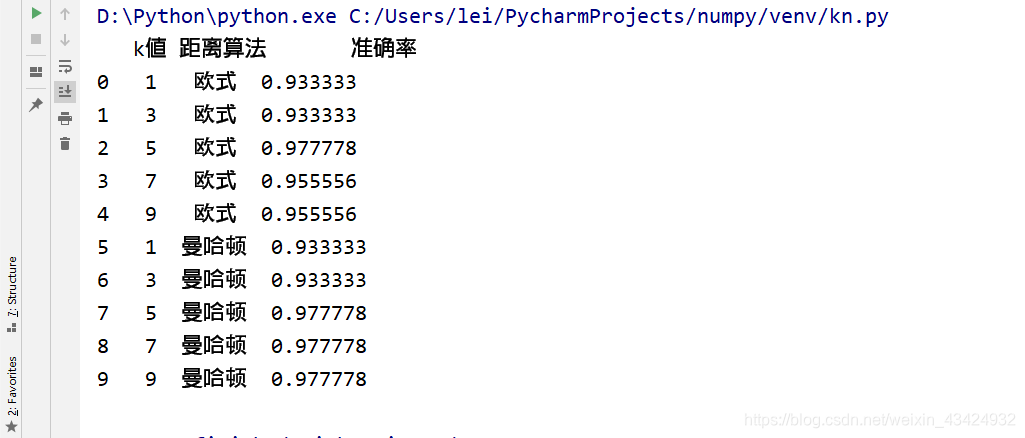
df=pd.DataFrame(result_list,columns=["k值","距离算法","准确率"])
print(df)
准确率结果