DBSCAN聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,可以将数据点分成不同的簇,并且能够识别噪声点(不属于任何簇的点)。
DBSCAN聚类算法的基本思想是:在给定的数据集中,根据每个数据点周围其他数据点的密度情况,将数据点分为核心点、边界点和噪声点。核心点是周围某个半径内有足够多其他数据点的数据点,边界点是不满足核心点要求,但在某个核心点的半径内的数据点,噪声点则是不满足任何条件的点。接着,从核心点开始,通过密度相连的数据点不断扩张,形成一个簇。
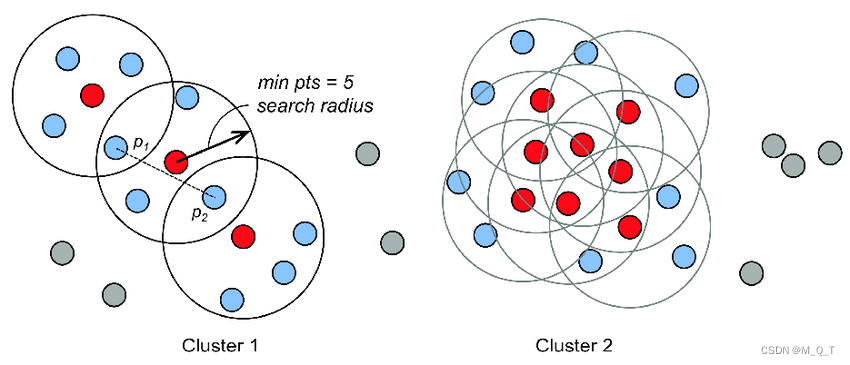
DBSCAN算法的优点是能够处理任意形状的簇,不需要先预先指定簇的个数,能够自动识别噪声点并将其排除在聚类之外。然而,该算法的缺点是对于密度差异较大的数据集,可能无法有效聚类。此外,算法的参数需要根据数据集的特性来合理选择,如半径参数和密度参数。
例子
假设我们有以下的数据点集合:[(1,1), (1,2), (2,1), (8,8), (8,9), (9,8), (15,15)]
我们可以使用DBSCAN算法来将这些点分成不同的簇。首先,我们需要设置两个参数:半径a和最小样本数minPts。这里我们设置 a=2 ,minPts=3。
接下来,我们从数据集中选取一个点,比如第一个点(1,1)作为种子点,并将该点标记为“核心点”,因为它周围有超过 minPts 个点在半径 a 的范围内。然后,我们找到与该点距离在 a 内的所有点,将它们标记为与该点“密度可达”(density-reachable),并将这些点加入同一个簇中。这里包括(1,2)和(2,1)。
接着,我们选取下一个未被分类的点,这里是(8,8),将其标记为“核心点”,并将与它距离在 内的所有点加入同一簇中,这里包括(8,9)和(9,8)。
最后,我们选取最后一个未被分类的点,(15,15),但该点只有1个点在 a 内,不足以满足minPts 的要求,因此该点被标记为噪声点。
于是,最终的聚类结果为:
Cluster 1: [(1,1), (1,2), (2,1)]
Cluster 2: [(8,8), (8,9), (9,8)]
Noise: [(15,15)]可以看出,DBSCAN算法成功地将数据点分成了两个簇,并且将噪声点(15,15)排除在聚类之外。
Python实现
例1
我们还是以上面例子为例,进行Python实现:
from sklearn.cluster import DBSCAN
import numpy as np
# 输入数据
X = np.array([(1,1), (1,2), (2,1), (8,8), (8,9), (9,8), (15,15)])
# 创建DBSCAN对象,设置半径和最小样本数
dbscan = DBSCAN(eps=2, min_samples=3)
# 进行聚类
labels = dbscan.fit_predict(X)
# 输出聚类结果
for i in range(max(labels)+1):
print(f"Cluster {i+1}: {list(X[labels==i])}")
print(f"Noise: {list(X[labels==-1])}")结果为:
Cluster 1: [array([1, 1]), array([1, 2]), array([2, 1])]
Cluster 2: [array([8, 8]), array([8, 9]), array([9, 8])]
Noise: [array([15, 15])]与手算结果一致。
以上Python实现中,首先我们定义了一个数据集X,它包含了7个二维数据点。然后,我们创建了一个DBSCAN对象,将半径设置为2,最小样本数设置为3。这里我们使用scikit-learn库提供的DBSCAN算法实现。
我们将数据集X输入到DBSCAN对象中,调用fit_predict()方法进行聚类,返回的结果是每个数据点所属的簇标签。标签为-1表示该点为噪声点。
最后,我们遍历所有簇标签,输出每个簇中的数据点。在输出簇标签时,我们将标签从0开始,因此需要加上1。
输出结果显示,数据点被分成了两个簇和一个噪声点,与前面手动计算的结果一致。
算法参数详解
下面对sklearn.cluster模块中的参数进行说明.该函数的调用方法为DBSCAN(eps=0.5, *, min_samples=5, metric='euclidean', metric_params=None, algorithm='auto', leaf_size=30, p=None, n_jobs=None)
该算法提供了多个可调参数,以控制算法的聚类效果。下面对常用的参数进行详细说明:
-
eps: 控制着半径的大小,是判断两个数据点是否属于同一簇的距离阈值。默认值为0.5。
-
min_samples: 控制着核心点周围所需的最小数据点数。默认值为5。
-
metric: 用于计算距离的度量方法,可以选择的方法包括欧式距离(euclidean)、曼哈顿距离(manhattan)等。默认值为欧式距离。
-
algorithm: 用于计算距离的算法,可以选择的算法包括Ball Tree(ball_tree)、KD Tree(kd_tree)和brute force(brute)。Ball Tree和KD Tree算法适用于高维数据,brute force算法适用于低维数据。默认值为auto,自动选择算法。
-
leaf_size: 如果使用Ball Tree或KD Tree算法,这个参数指定叶子节点的大小。默认值为30。
-
p: 如果使用曼哈顿距离或闵可夫斯基距离(minkowski),这个参数指定曼哈顿距离的p值。默认值为2,即欧式距离。
-
n_jobs: 指定并行运算的CPU数量。默认值为1,表示单CPU运算。如果为-1,则使用所有可用的CPU。
-
metric_params: 如果使用某些度量方法需要设置额外的参数,可以通过这个参数传递这些参数。默认值为None。
这些参数对于控制DBSCAN算法的聚类效果非常重要,需要根据具体的数据集和需求进行选择和调整。在使用DBSCAN算法时,我们通常需要对这些参数进行多次实验和调整,以达到最佳的聚类效果。
例2:鸢尾花数据集
再以著名的鸢尾花数据集为例进行Python实现
from sklearn.cluster import DBSCAN
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
# 加载数据集
iris = load_iris()
X = iris.data
# 数据预处理,标准化数据
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 使用DBSCAN聚类算法
dbscan = DBSCAN(eps=0.5, min_samples=5)
y_pred = dbscan.fit_predict(X)
# 输出聚类结果
print('聚类结果:', y_pred)上述代码首先使用load_iris()函数加载了iris数据集,然后使用StandardScaler()对数据进行标准化处理。使用DBSCAN类创建了一个DBSCAN对象,并传递了eps和min_samples参数的值。最后,使用fit_predict()方法对数据进行聚类,并将聚类结果存储在y_pred变量中,最后打印聚类结果。
结果如下:
聚类结果: [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 -1 -1 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 -1 -1 0 0 0 0 0 0 0 -1 0 0 0 0 0 0
0 0 1 1 1 1 1 1 -1 -1 1 -1 -1 1 -1 1 1 1 1 1 -1 1 1 1
-1 1 1 1 1 1 1 1 1 1 1 1 1 -1 1 -1 1 1 1 1 1 -1 1 1
1 1 -1 1 -1 1 1 1 1 -1 -1 -1 -1 -1 1 1 1 1 -1 1 1 -1 -1 -1
1 1 -1 1 1 -1 1 1 1 -1 -1 -1 1 1 1 -1 -1 1 1 1 1 1 1 1
1 1 1 1 -1 1]
不过这次结果中将很多点设置为了噪声点(当然我们可以将噪声点归为一类),如果觉得现在的结果不满意,可以进一步调整算法中的参数。
参考资料:
【1】https://mp.weixin.qq.com/s/z6AgcvUP3-FwtwCyyQHgPg
【2】sklearn.cluster.DBSCAN — scikit-learn 1.2.2 documentation